
Static Timing Analysis for Nanometer Designs:A Practical Approach(v1)
绪论
众所周知,静态时序分析是IC工程师必备知识点,也是秋招中笔试面试的高频考点。
网上不乏优秀视频课,如V3学院尤老师、小梅哥、IC创新学院邸志雄老师的课。
《Static Timing Analysis for Nanometer Designs:A Practical Approach》,可堪称静态时序分析的“圣经”吧!
由于网上找不到此书的翻译,因此笔者决定开坑进行对“圣经”的翻译~!希望可以在加深对静态时序分析的学习同时,完成这一本书的翻译方便大家以后更好地从中学习吧。

本章节概述了纳米级(nanometer)设计下的静态时序仿真过程
本章节解决了如下问题:
- 什么是静态时序分析(static timing analysis)?
- 噪声(noise)与串扰(crosstalk)会带来什么影响 ?
- 如何使用静态时序分析?
- 在整个设计流程中的哪个阶段会应用静态时序分析?
纳米级设计
在半导体器件中,常使用金属互连线来连接电路中的不同部分,从而实现设计。随着工艺技术的发展,这些互连线逐渐开始影响设计的性能。对于深亚微米或者纳米级别的工艺技术,互连线间的耦合效应会带来噪声与串扰,而这两者都会限制设计的运行速度。虽然噪声与串扰带来的影响在老一代的工艺技术下是可以忽略不计的,但在如今纳米级别下已经不容忽视了。因此,不论是物理设计还是设计验证都应考虑到噪声与串扰的影响。
什么是静态时序分析?
静态时序分析(简称STA)是用来验证数字设计时序的技术之一,另外一种验证时序的方法是时序仿真,时序仿真可以同时验证功能和时序。“时序分析”这个术语就是用来指代“静态时序分析“或”时序仿真“这两种方法之一,简单来说,时序分析的目的就是为了解决设计中的各种时序问题。
STA被称为静态的原因是其对于设计的分析是静态地执行的,并不依赖于施加在输入端口上的激励。相比之下,时序仿真则可以被视作动态地执行对设计的分析,具体过程描述如下:施加一组激励,观察在这组激励下电路行为是否符合要求,然后换一组激励再重复以上过程,以此类推。
给定了一个设计、输入时钟以及外部环境,STA的目的就是验证这个设计是否能够运行在预期的速度,即这个设计可以安全地运行在给定的时钟频率下且没有时序违例。
图1-1展示了STA的基本功能:
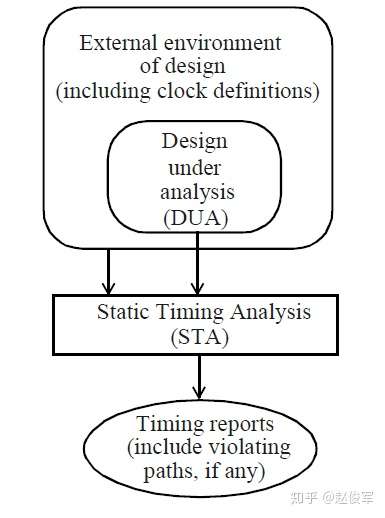
上图中DUA即为待分析的设计。时序检查是指建立时间与保持时间检查:建立时间检查是用来保证数据可以在给定时钟周期内到达触发器;保持时间检查是用来保证数据在被触发器采样后还能保持一定时间,即保证触发器不要漏采数据。这些时序检查的目的都是为了保证触发器可以发送并且采样到正确的数据。
STA更重要的意义在于:整个设计只需要被分析一次,就可以对所有情况下设计中的全部路径进行所需的时序检查。因此,STA是能够被用来验证设计时序的一种完全且详尽的方法。
DUA通常使用硬件描述语言,例如VHDL或者Verilog HDL;外部环境,包括时钟定义,通常使用SDC或等价格式进行描述;SDC是一种时序约束的规范语言;而时序报告通常以ASCII格式呈现,一般报告中会有许多列,每一列都会显示路径延时的一个属性。
为何使用静态时序分析?
STA是一种可以验证设计中所有时序要求的详尽方法,而其他时序分析方法例如时序仿真则只能验证到被当前激励执行到的那部分时序路径。基于时序仿真的验证完备性取决于施加激励的完备性。如果使用时序仿真来验证一个千万门级别的设计,速度将会非常慢,并且实际上也无法充分验证。因此,想要基于时序仿真的方法来进行详尽的时序验证是非常困难的。
相比之下,STA则提供了一种更快更简单的方法去分析并检查设计中的全部时序路径。鉴于如今的ASIC设计规模已达千万门级别,STA已经成为了详尽地验证设计时序的必要方法。
串扰与噪声
设计的功能和性能会受到噪声的影响,引起噪声的主要原因有:与其他信号的串扰、主要输入端口的噪声、电源等。由于噪声会限制设计所能运行的最高频率,并且也可能导致功能错误,因此一个设计必须保证有足够的鲁棒性,即这个设计可以在原有额定性能的基础上抵御一定的噪声。
基于逻辑仿真的验证是无法处理由串扰、噪声以及片上变化(on-chip variations)所带来的的影响的。
本书中所描述的分析方法不仅包括了传统时序分析技术,还包括了能够验证设计中噪声问题的噪声分析。
设计流程
本节主要介绍了本书其余部分使用的CMOS数字设计流程,同时也简要说明了其在FPGA和异步设计中的适用性。
CMOS数字设计
在CMOS数字设计流程中,STA会在实现的各个阶段里被使用到。图1-2展示了一个基本的流程:
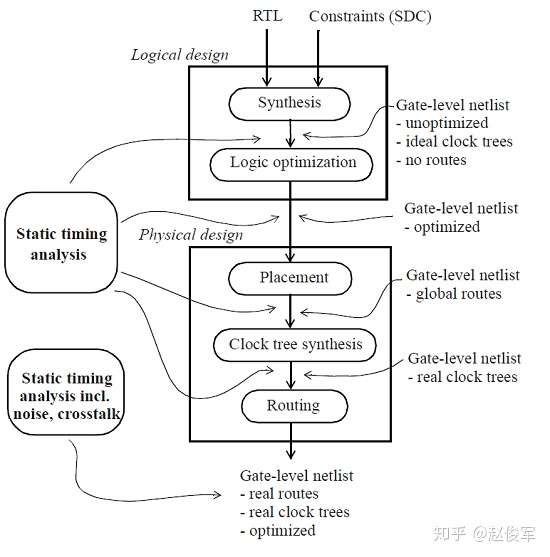
STA很少在RTL级完成,因为在这一抽象层级上,验证设计的功能更为重要,而非时序。 同样,由于块(block)的描述处于行为级,因此时序信息也并非都是可用的。 一旦将RTL级的设计综合到门级,就可以使用STA来验证设计的时序。 STA也可以在执行逻辑优化之前运行,其目标是确定最差或关键的时序路径。 可以在逻辑优化后重新运行STA,以查看是否还有剩余的时序违例路径需要优化,或者确定关键路径。
在物理设计的一开始,时钟树被认为是理想的,即它们具有零延迟。 一旦物理设计开始并且建立了时钟树之后,就可以执行STA来再次检查时序。 实际上,在物理设计过程中,可以在每一步都执行STA以确定最差的路径。
在物理实现中,逻辑单元通过金属互连走线连接。 金属走线的寄生RC(电阻和电容)会影响通过这些走线的信号路径延迟。 在典型的纳米级设计中,大部分延迟和功耗都是由互连线带来的寄生因素所导致的。 因此,对设计的任何分析都应评估互连线对性能(速度,功耗等)的影响。 综上所述,信号走线之间的耦合会导致噪声,并且设计验证必须考虑到噪声对性能的影响。
在逻辑设计阶段,由于没有与布局有关的物理信息,因此可以假设互连线是理想状态的,此阶段会更关注查看导致最差路径的逻辑。 在这个阶段使用的另一种技术是采用线负载模型(wireload model)来估算互连线的长度, 线负载模型会基于逻辑单元的扇出提供一个估计的RC值。
在完成走线的布线之前,设计实现工具会使用布线距离的估算值来获得该路线的寄生RC值。 由于布线尚未完成,因此该阶段称为全局布线(global route)阶段,以将其与最终布线(final route)阶段区分开来。 在物理设计的全局布线阶段,简化的布线用于估计布线长度,而对布线的估计用于确定计算走线延迟所需的电阻和电容值。 在此阶段中,无法考虑耦合效应带来的影响。在实际精细的布线完成后,就可以提取实际的RC值,并且可以分析耦合效应带来的影响。 但是,物理设计工具仍可以使用近似值来帮助缩短计算RC值的运行时间。
提取工具用于从布线设计中提取详细的寄生参数(RC值),这样的提取工具一般具有以下选项:在迭代优化期间以较少的运行时间和较低精确度的RC值来获取寄生参数,以及在最终验证期间以较长的运行时间来提取非常精确的RC值。
总结一下,可以根据以下条件在门级网表上执行静态时序分析:
1.互连线的建模方式:理想互连线,线负载模型,具有近似RC值的全局布线以及具有精确RC值的实际布线。
2.时钟的建模方式:理想时钟(零延迟)或是传播时钟(实际延迟)。
3.是否考虑信号之间的耦合效应以及是否分析串扰噪声。
图1-2似乎暗示着STA是在实现步骤之外完成的,即STA是在综合、逻辑优化和物理设计步骤中的每个步骤之后完成的。 实际上,这些步骤中的每一个都在其功能范围内集成有STA。 例如,逻辑优化步骤中的时序分析引擎可用于识别优化器需要处理的关键路径。 同样,布局工具中集成的时序分析引擎可用于在布局逐步进行过程中保持设计的时序。
FPGA设计
STA的基本流程在FPGA中仍然有效,即使FPGA中的布线受限于通道,提取寄生参数和执行STA的机制也与CMOS数字设计流程相同。 例如,可以在假设互连为理想状态的情况下执行STA,或使用线负载模型,在时钟树为理想状态或真实状态的情况下执行STA,或者对寄生参数情况采用全局布线或真实布线来执行STA。
异步设计
STA的原理也适用于异步设计,但在异步设计中会更加关注从一个信号到另一个信号的时序,而不是进行有可能不存在的建立时间与保持时间检查。 因此,异步设计中的时序检查一般是点到点时序检查或偏斜检查。 用于分析由耦合效应引起的毛刺的噪声分析适用于任何设计,包括同步设计与异步设计。同样,考虑到耦合响应对时序带来影响的噪声分析,对于异步设计也同样有效。
不同阶段的静态时序分析
在逻辑级(未进行物理设计的门级),STA可采用以下模型:
1.理想的互连线或者基于线负载模型的互连线
2.带有延迟和抖动估计值的理想时钟
在物理设计阶段,除了上述模型,STA还可采用以下模型:
- 具有近似估计值的全局布线的互连线、具有近似寄生参数提取值的实际布线的互连线、具有可以签收(signoff)精度寄生参数提取值的实际布线的互连线
2.实际的时钟树
3.包括串扰的影响或者不包括串扰的影响
静态时序分析的局限性
虽然时序分析和噪声分析在所有可能的情况下都可以很好地分析设计中的时序问题,但在最新的技术中仍然无法完全使用STA替代仿真, 这是因为时序验证的某些方面还无法完全被STA捕获并得到验证。
静态时序分析的局限性包括以下几点:
复位顺序:检查所有触发器在异步或同步复位后是否都复位为所需的逻辑值,这是无法使用静态时序分析来检查的。 芯片可能不会退出复位状态。 这是因为某些声明(例如信号的初始值)没有被综合,仅在仿真过程中被验证。
未知态X的处理:STA技术仅处理逻辑0和逻辑1(或高电平/低电平)的逻辑域,或者是上升沿和下降沿的逻辑域。 设计中的未知态X导致不确定的值在整个设计中传播,这也是无法使用STA进行检查。 即使STA内的噪声分析可以分析整个设计中的毛刺,但作为纳米级设计中基于仿真的时序验证的一部分,毛刺分析和传播的范围也与对未知态X的处理大为不同。
PLL设置:PLL的配置可能未被正确加载或设置。
跨异步时钟域:STA不检查是否使用了正确的时钟同步器,需要其他工具来确保在任何跨异步时钟域的地方都有正确的时钟同步器。
IO接口时序:可能仅根据STA约束无法规定IO接口要求。例如,设计人员可能使用SDRAM仿真模型为DDR接口选择详细的电路级仿真。仿真是为了确保可以以足够的余量读取和写入存储器,并且在必要时可以控制DLL(如果有)来对齐信号。
模拟模块和数字模块之间的接口:由于STA不处理模拟模块,因此验证方法需要确保这两种类型的模块之间的连接正确。
伪路径(false path):静态时序分析会验证通过逻辑路径的时序是否满足所有约束,如果通过逻辑路径的时序不符合要求的规范,则标记违例。在许多情况下,即使逻辑可能永远无法传播通过该路径,STA也会将该逻辑路径标记为时序违例路径。 当系统应用程序从不使用此类路径时,或者在时序违例路径的敏感列表中使用了互斥的条件时,可能会发生这种情况。 这种时序路径被称为伪路径,因为这种时序路径实际上不会被执行。当在设计中指定了正确的时序约束(包括伪路径和多周期路径约束)时,STA结果的质量会更好。 在大多数情况下,设计人员可以利用设计的固有知识并指定约束条件,以便在STA期间消除伪路径。
FIFO指针不同步:当两个预期要同步的有限状态机实际上不同步时,STA无法检测到该问题。在功能仿真过程中,两个有限状态机可能始终保持同步变化。但是,在考虑了延迟之后,一个有限状态机有可能与另一个就不同步了,这很可能是因为一个有限状态机比另一个更早退出复位状态,而STA无法检测到这种情况。
时钟同步逻辑:STA无法检测到时钟生成逻辑与时钟定义不匹配的问题。 STA会假设时钟生成器将提供时钟定义中指定的波形。 对时钟生成器逻辑的优化可能很糟糕,比如会导致在未适当约束的路径之一上插入较大的延迟,又或者,添加的逻辑改变了时钟的占空比。而STA无法检测到这些潜在情况中的任何一个。
跨时钟周期的功能行为:STA无法建模或仿真跨时钟周期变化的功能行为。
尽管存在诸如此类的问题,STA依然适合被广泛用于验证设计的时序,而时序仿真可作为备用方法来检查极端情况,并且能够更简单地验证设计的功能正确。
功耗考虑
功耗是设计实现中的重要考虑因素,大多数设计需要在电路板和系统的功耗预算内运行。若需要符合标准并且考虑到芯片运行在电路板和系统上的热预算,可能还会出现功耗方面的考虑。对总功率(total power)和待机功率(standby power)通常存在独立的限制,待机功率限制通常适用于手持式或电池供电的设备。
在大多数实际设计中,功耗和时序通常是密不可分的。设计人员希望使用更快(或更高速度)的单元来满足速度方面的考虑,但可能会受到功耗的限制。 在选择工艺技术和单元库时,功耗是一个重要的考虑因素。
可靠性考虑
设计实现必须满足可靠性要求。如1.4.1节中所述,金属互连走线具有寄生RC值,从而限制了设计的性能。除寄生效应外,在设计金属互连走线宽度时也应当要考虑可靠性因素。例如,高速时钟信号需要足够宽,以满足诸如电迁移之类的可靠性考虑。
本书大纲
尽管表面上静态时序分析似乎是一个非常简单的概念,但该分析背后有很多背景知识。基本概念的范围从准确地表示单元延迟到计算具有最小悲观度的最坏路径延迟。计算单元延迟、组合逻辑块的延时、时钟关系、多个时钟域和门控时钟的概念构成了静态时序分析的重要基础,为设计编写正确的SDC确实是一个挑战。
这本书是按照自底向上(bottom-up)的顺序编写的,即首先介绍简单的概念,在随后的章节中介绍更高级的主题。
●本书首先介绍了准确计算单元延迟(第3章)。
●估计或计算精确的互连延迟及其有效表示方法是第4章的主题。
●在第5章中讨论如何计算由单元和互连线组成的路径延迟。
●信号完整性(即信号在相邻网络上的相互影响)及其对路径延迟的影响是第6章的主题。
●第7章介绍了时钟定义和路径例外来准确表示DUA的环境。
●第8章介绍了在STA中执行时序检查的详细信息。
●第9章将讨论跨各种接口的IO时序建模。
●最后,第10章将介绍高级时序检查,如片上变化(on-chip variation)、时钟门控(clock gating)检查,电源管理和统计时序分析。
●附录提供了SDC(用于表示时序约束),SDF(用于表示单元和网络延迟)和SPEF(用于表示寄生参数)的详细说明。
第7章至第10章介绍的是STA验证的核心,前面的章节为更好地了解STA打下了扎实的基础。
STA概念上
本章节介绍CMOS技术的基础知识以及执行静态时序分析所涉及的术语。
CMOS逻辑设计
CMOS逻辑设计
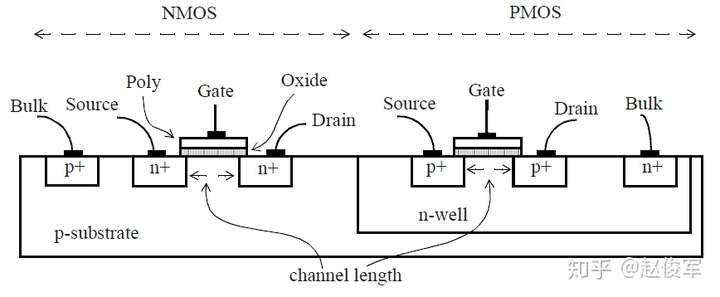
基本MOS结构
MOS晶体管(NMOS和PMOS)的物理实现如图2-1所示。源极(source)和漏极(drain)区域之间的距离(channel length)是MOS晶体管的长度,用于构建MOS晶体管的最小长度即为CMOS技术工艺的最小特征尺寸(feature size)。例如,0.25um技术允许制造具有0.25um或更大沟道长度的MOS晶体管。 通过缩小沟道的几何形状,晶体管的尺寸会变小,这样就可以在同样的面积上封装更多的晶体管。 正如我们将在后面章节看到的那样,更小的晶体管尺寸同样还可以使设计以更高的速度运行。
CMOS逻辑门
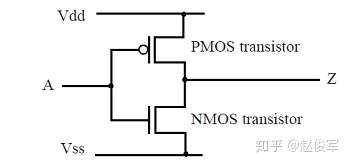
CMOS逻辑门使用NMOS和PMOS晶体管搭建而成。图2-2给出了CMOS反相器(inverter)的示例。CMOS反相器有两种稳定状态,具体取决于输入的电平状态。 当输入A为低电平(Vss或逻辑0)时,NMOS晶体管截止,而PMOS晶体管导通,导致输出Z的电平被上拉至逻辑为1的Vdd。当输入A为高电平(Vdd或逻辑1)时,NMOS晶体管导通,而PMOS晶体管截止,导致输出Z的电平被下拉至逻辑为0的Vss。在上述两种状态中的任何一种状态下,CMOS反相器都是稳定的,不会从输入端A或电源Vdd汲取任何电流。
CMOS反相器的特性可以扩展到任何CMOS逻辑门。在CMOS逻辑门中,输出节点通过上拉结构(由PMOS晶体管构成)连接至Vdd,并通过下拉结构(由NMOS晶体管构成)连接至Vss。例如,图2-3展示了一个两输入CMOS与非门(nand)。在该例中,上拉结构由两个并联的PMOS晶体管组成,下拉结构由两个串联的NMOS晶体管组成。
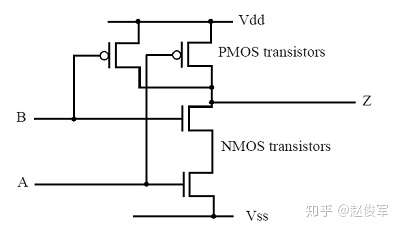
对于任何CMOS逻辑门,上拉和下拉结构是互补的。对于逻辑0或逻辑1的输入,如果上拉结构开启,则下拉结构将关闭;类似地,如果上拉结构关闭,则下拉结构将开启。下拉和上拉结构由CMOS门实现的逻辑功能控制。例如,在CMOS与非门中,控制下拉结构的功能是“A&B”,即当A和B都为逻辑1时下拉被接通。类似地,控制上拉结构的功能是“ ”,即当A或B处于逻辑0时上拉被打开。这些特性确保了控制上拉结构的功能将输出节点的逻辑上拉至Vdd。由于下拉结构由互补函数控制,因此当上拉结构函数的值为0时,输出节点处于逻辑0。
对于逻辑0或逻辑1的输入,由于上拉和下拉结构不能同时开启,因此处于稳态的CMOS逻辑门不会对输入或电源汲取任何电流。CMOS逻辑的另一个重要方面是,输入仅对前一级构成容性负载。
若CMOS逻辑门是一个反相门,这意味着单个输入的变化(上升或下降)只能使输出往相反的方向改变,也就是说,输出无法与输入同相变化。但是,可以将CMOS逻辑门级联起来以实现更复杂的逻辑功能。
标准单元
芯片中的大多数复杂功能通常是使用基本构建块(basic building block)来设计的,这些基本构建块实现了简单的逻辑功能,例如与、或、与非、或非、或与非,与或非以及触发器(flip-flop)。这些基本构建块是预先设计的,称为标准单元(standard cell)。标准单元的功能和时序已预先确定,可供设计人员使用。然后,设计人员可以使用标准单元作为基本构建块来实现所需的功能。
前面小节中描述的CMOS逻辑门的关键特性适用于所有CMOS数字设计。当输入处于稳定的逻辑状态时,所有数字CMOS单元的设计都能够保证不从电源汲取电流(漏电流除外)。因此,大多数功耗与设计的功能有关,并且是由设计中CMOS单元输入端的充放电引起的。
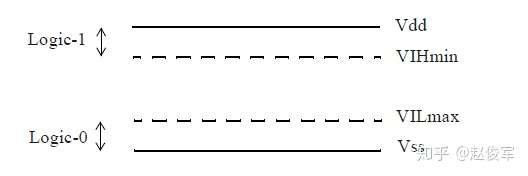
什么是逻辑1或逻辑0?在CMOS单元中,VIHmin和 VILmax这两个值定义了范围:高于VIHmin的电压值被认为是逻辑1,低于VILmax的电压值被认为是逻辑0。如图2-4所示,0.13um工艺下一个具有1.2V Vdd电源的CMOS反相器单元的典型VILmax值为0.465V、VIHmin值为0.625V。 VIHmin和VILmax的值是从标准单元的直流传输特性中得出的。直流传输特性会在接下去的6.2.3节中有更详细的描述。
CMOS单元建模
如果一个单元的输出引脚驱动多个扇出单元,则该单元的输出引脚上的总电容等于该单元正在驱动的单元的所有输入电容的总和加上构成该网络所有走线电容之和再加上驱动单元的输出电容。注意,在CMOS单元中,输入引脚仅呈现电容性负载。
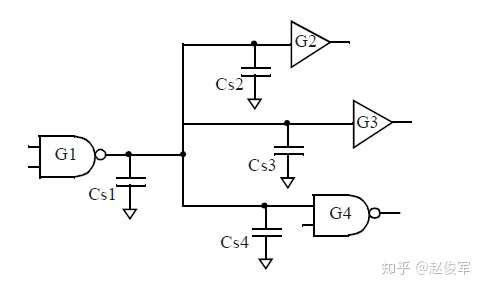
图2-5是一个单元G1驱动其他三个单元G2、G3和G4的示例。 Cs1,Cs2,Cs3和Cs4是组成该网络的走线电容值,因此G1输出引脚的总电容=G2单元的输入电容+G3单元的输入电容+G4单元的输入电容+G1单元的输出电容+ Cs1+Cs2+Cs3+Cs4 。这个值就是G1单元进行电平切换时需要充放电的电容值,因此该总电容值会影响G1单元的时序特性。
从时序角度来看,我们需要对CMOS单元建模,以帮助我们分析通过该单元的时序。每个输入引脚必须指定一个输入引脚电容,而大多数CMOS逻辑单元可以不包括输出引脚的引脚电容,但也可能存在输出引脚电容。
当输出为逻辑1时,输出级的上拉结构导通,并提供了一条从输出到Vdd的路径。同样,当输出为逻辑0时,输出级的下拉结构提供了一条从输出到Vss的路径。当CMOS单元切换电平状态时,切换的速度取决于输出引脚上的电容被充放电的速度。输出引脚上的电容(图2-5)分别通过上拉和下拉结构充电和放电。注意,上拉和下拉结构中的通道会对输出的充放电路径构成电阻,充放电路径的电阻是决定CMOS单元速度的主要因素。上拉电阻的倒数称为单元的输出高电平驱动(output high drive)。输出上拉结构越大,上拉电阻就越小,即单元的输出高电平驱动就越大,较大的输出结构也意味着该单元的面积较大。而输出上拉结构越小,单元的面积就越小,其输出高电平驱动也就越小。上拉结构的相同概念可用于下拉结构,下拉结构决定了下拉路径的电阻值以及输出低电平驱动(output low drive)。通常,单元的上拉和下拉结构具有相似的驱动强度。
输出驱动决定了可以驱动的最大电容负载,最大电容负载又决定了扇出的最大数量,即可以驱动多少个其他单元。较高的输出驱动对应较低的输出上拉/下拉电阻,这使单元可以在输出引脚上对较大的负载进行充电和放电。
下图2-6是CMOS单元的等效抽象模型。该模型的目的是抽象单元的时序行为,因此仅对输入级和输出级进行建模,此模型无法捕获单元的固有延迟或电学行为。
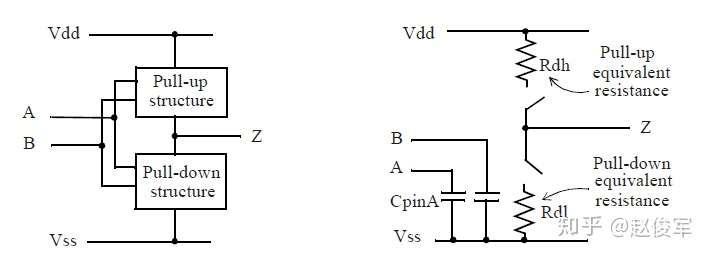
CpinA是单元在输入A上的输入引脚电容;Rdh和Rdl是单元的输出驱动电阻,可根据单元所驱动的负载确定输出引脚Z电平转换时的上升/下降时间,输出驱动电阻还确定了单元的最大扇出限制。
图2-7与图2-5具有相同的网络,但使用等效模型表示了CMOS单元:
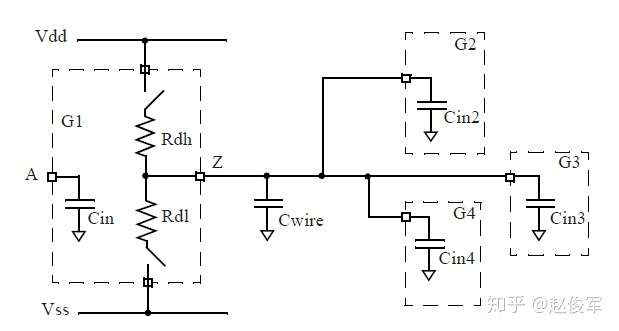
● Cwire = Cs1+Cs2+Cs3+Cs4
● 输出充放电延迟 = Rout × (Cwire + Cin2 + Cin3 + Cin4)
在上述表达式中,Rout是Rdh或Rdl之一,其中Rdh是上拉的输出驱动电阻,Rdl是下拉的输出驱动电阻。
电平切换波形
如图2-8(a)所示,通过按下SW0开关将电压施加到RC网络时,输出将变为逻辑1。假设还未按下SW0时输出为0V,则输出电压的变化由以下公式表示:
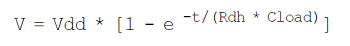
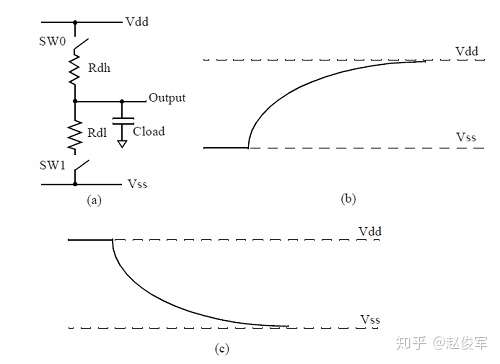
该上升的电压波形如图2-8(b)所示。乘积(Rdh * Cload)称为RC时间常数(RC time constant),该值与输出的过渡时间有关。
断开SW0开关同时按下SW1开关,输出就会从逻辑1变为逻辑0,输出电压的变化如图2-8(c)所示。输出电容通过按下的SW1开关放电,这种情况下的电压变化由以下公式表示:
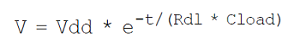
在CMOS单元中,由于PMOS上拉晶体管和NMOS下拉晶体管在短时间内会同时导通,因此输出的充放电波形不会像图2-8的RC充放电波形那样。 图2-9显示了在CMOS反相器单元内,从逻辑1到逻辑0输出切换时各个阶段的电流路径。图2-9(a)显示了当上拉和下拉结构同时开启时的电流流动。随后,上拉结构关闭,电流流向随即如图2-9(b)中所示。输出达到最终状态后,由于电容Cload已完全放电,因此不再有电流流动。
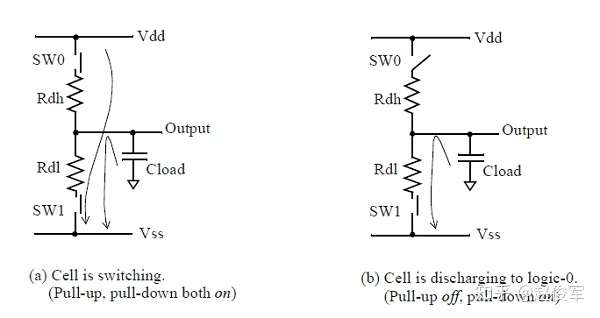
图2-10(a)是CMOS单元输出级的典型波形,请注意观察过渡波形如何逐渐朝向Vss和Vdd弯曲,且波形的线性部分位于中间位置。
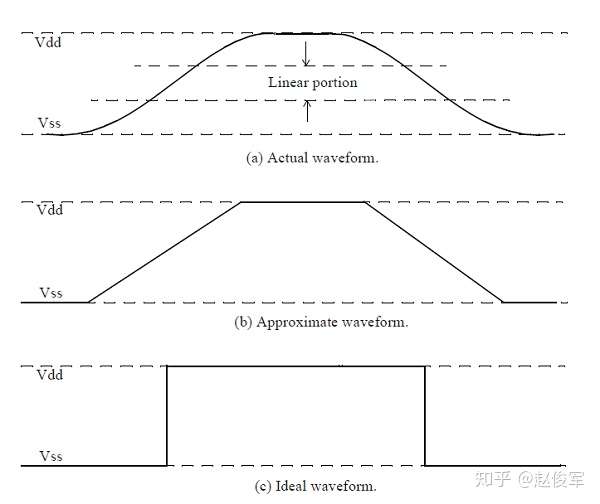
在本文中,我们将使用如图2-10(b)所示的简化版来描绘一些波形,简化版的近似波形也是具有一定过渡时间(transition time)的波形,过渡时间是指从一种逻辑状态过渡到另一种逻辑状态所需的时间。图2-10(c)是过渡时间为0的波形,即理想波形。我们将在本文中交替使用(b)(c)这两种形式的波形来解释一些概念,但我们一定要清楚,实际上每个波形都有(a)那样的真实的边缘特性。
传播延时
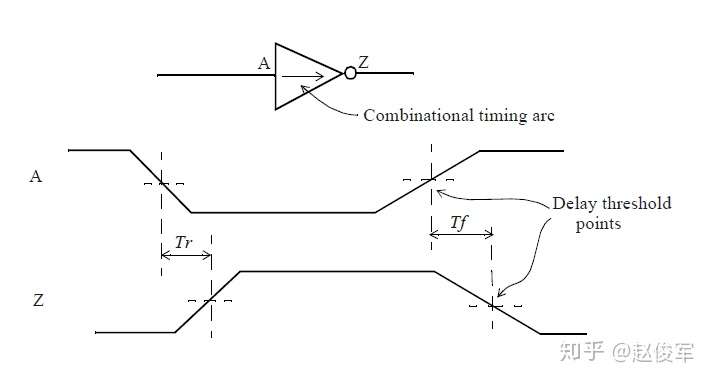
考虑一个CMOS反相器单元及其输入和输出波形,单元的传播延时(propagation delay)是由电平切换波形上的某些测量点定义的。使用以下四个变量定义这些测量点:
#输入端口下降沿的阈值点
input_threshold_pct_fall:50.0;
#输入端口上升沿的阈值点
input_threshold_pct_rise:50.0;
#输出端口下降沿的阈值点
output_threshold_pct_fall:50.0;
#输出端口上升沿的阈值点
output_threshold_pct_rise:50.0;
以上这些变量是用于描述单元库(cell library)的命令集里的一部分。 这些阈值的单位是Vdd或电源的百分比,对于大多数标准单元库,通常将50%阈值用于计算延时。
上升沿是指从逻辑0到逻辑1的跳变,下降沿是从逻辑1到逻辑0的跳变。
假设有一个CMOS反相器单元,其输入输出管脚的波形如图2-11所示,传播延时是指如下两个值:
1.输出下降沿延时(output fall delay):Tf
2.输出上升沿延时(output rise delay):Tr
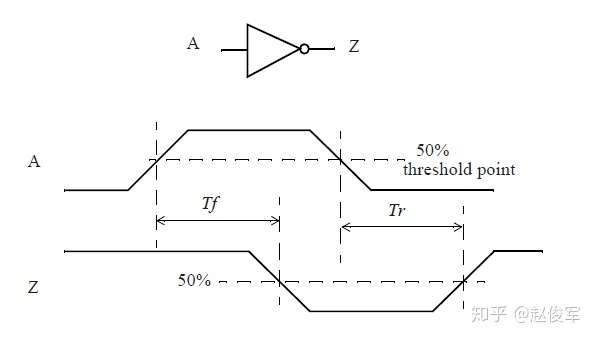
通常,这两个值是不相等的,上图2-11也展示了这两个传播延时值是如何测量的。
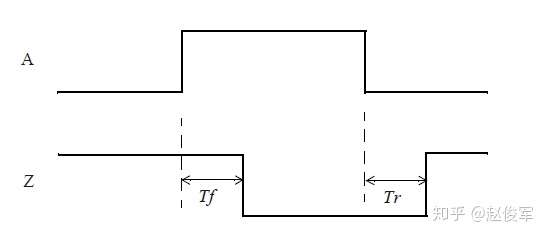
若使用理想波形来看,则传播延时将仅仅是两个边沿之间的延迟,如图2-12所示:
波形的压摆
压摆率(slew rate)的定义是电压转换速率。在静态时序分析中,通常会根据电平转换的快慢来衡量上升波形或下降波形。 压摆(slew)通常是根据转换时间(transition time)来定义的,转换时间是指信号在两个特定电平之间转换所需要的时间。请注意,转换时间实际上就是压摆率的倒数,因此转换时间越大,压摆率就越低,反之亦然。
回顾图2-10给出的CMOS单元输出端典型波形:靠近Vdd和Vss两端的波形是渐近的,很难确定过渡时间的确切起点和终点。因此,一般使用指定的阈值电压来规定过渡时间计算的起点和终点。例如,压摆阈值设置可以如下所示:
#下降沿的阈值点
slew_lower_threshold_pct_fall:30.0;
slew_upper_threshold_pct_fall:70.0;
#上升沿的阈值点
slew_lower_threshold_pct_rise:30.0;
slew_upper_threshold_pct_rise:70.0;
以上这些数值的单位同样是Vdd的百分比。阈值设置指定了下降压摆(Fall slew)为下降沿达到Vdd的70%和30%的时间之差。类似地,设置指定了上升压摆(Rise slew)为上升沿达到Vdd的30%和70%的时间之差,如图2-13所示:
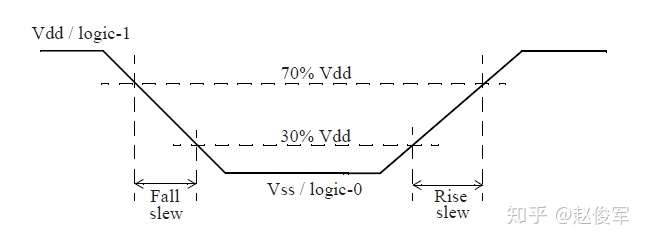
图2-14是另一个示例,其中下降沿的压摆测量范围为80%至20%,而上升沿的压摆测量范围为10%至90%,以下是这个例子的阈值设置:
#下降沿的阈值点
slew_lower_threshold_pct_fall:20.0;
slew_upper_threshold_pct_fall:80.0;
#上升沿的阈值点
slew_lower_threshold_pct_rise:10.0;
slew_upper_threshold_pct_rise:90.0;
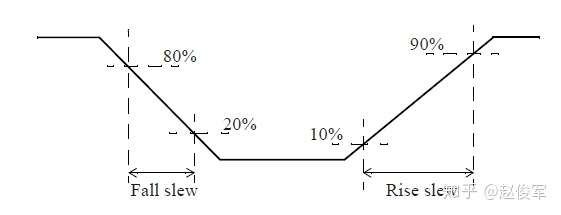
信号偏斜
偏斜(skew)是指两个或多个信号(数据或者时钟)之间的时序之差。例如,如果一个时钟树(clock tree)有500个终点,并且有50ps的偏斜,则意味着最长时钟路径和最短时钟路径之间的延迟差为50ps。如图2-15所示是一个时钟树,时钟树的起点通常是定义时钟的节点,时钟树的终点通常是同步元件(例如触发器)的时钟引脚。时钟延迟(clock latency)是指从时钟源到终点所花费的总时间,时钟偏斜(clock skew)是指到达不同时钟树终点的时间差。
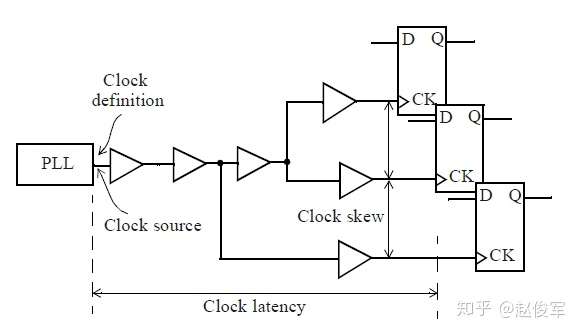
理想时钟树是假定时钟源具有无限驱动力,也就是说,时钟可以无延迟地驱动无限个终点。另外,假定时钟树中存在的任何逻辑单元都具有零延迟(zero delay)。 在逻辑设计的早期阶段,STA通常使用理想的时钟树来执行,因此分析的重点是数据路径(data path)。在理想的时钟树中,默认情况下时钟偏斜为0ps,可以使用set_clock_latency命令显式地指定时钟树的延迟:
set_clock_latency 2.2 [get_clocks BZCLK]
上述命令规定了时钟树BZCLK的上升沿延迟(rise latency)和下降沿延迟(fall latency)均为2.2ns。注意,如果两个延时值不同,可以使用选项-rise和-fall来分别指定延时值。
时钟树的时钟偏斜可以借助set_clock_uncertainty命令显式指定时钟不确定度的值来进行描述:
set_clock_uncertainty 0.250 -setup [get_clocks BZCLK]
set_clock_uncertainty 0.100 -hold [get_clocks BZCLK]
set_clock_uncertainty命令为时钟沿的出现指定了一个窗口。时钟边沿时序的不确定性将考虑多个因素,例如时钟周期抖动(jitter)和用于时序验证的额外裕量(slack)。每个实际的时钟源都有一定的抖动量,即一个时间窗口,在该窗口内都可能会出现时钟沿。时钟周期抖动取决于所使用的时钟发生器的类型。实际上是不存在理想时钟的,也就是说,所有时钟都具有一定的抖动量,并且在指定时钟不确定度(clock uncertainty)时应包括时钟周期抖动。
在时钟树被实现(implement)之前,时钟不确定度还必须包括预期的时钟偏斜。
可以为建立时间(setup time)检查和保持时间(hold time)检查指定不同的时钟不确定度。保持时间检查不需要将时钟抖动包括在内,因此通常为保持时间检查指定较小的时钟不确定度。
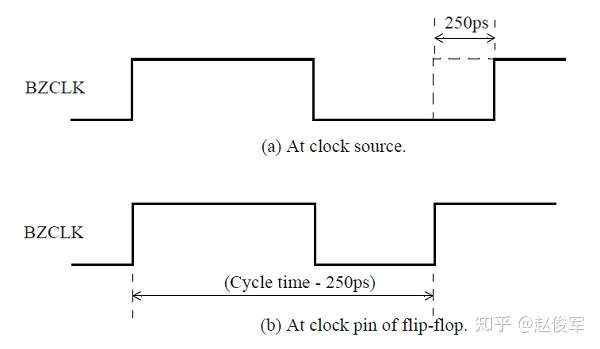
如下图2-16所示是时钟不确定度为250ps的建立时间检查。图2-16(b)揭示了时钟不确定度是如何从逻辑传播到下一个触发器的耗时中消去的,这相当于要验证设计能够以更高的频率运行。
如上所述,set_clock_uncertainty命令也可以用于建模任何额外时序裕量。例如,设计人员可以在设计过程中依据一定的悲观度而设置50ps的时序裕量,使用set_clock_uncertainty命令时会将这个值加进去。
总而言之,在实现时钟树之前,set_clock_uncertainty命令指定的值将包括时钟抖动、时钟偏斜估计值以及额外悲观度。
set_clock_latency 2.0 [get_clocks USBCLK]
set_clock_uncertainty 0.2 [get_clocks USBCLK]
上面这条命令中200ps的时钟不确定度可能是由50ps时钟抖动、100ps时钟偏斜以及50ps的额外悲观度组成的。
随后我们将看到set_clock_uncertainty这条命令是如何影响建立时间和保持时间检查的,我们最好能够将时钟不确定度视为最终计算时序裕量(slack)的补偿(offset)。
时序弧
每个逻辑单元都有多个时序弧(timing arc)。像与门、或门、与非门、加法器这些组合逻辑单元,每个输入引脚到每个输出引脚都存在一条时序弧。而像触发器之类的时序逻辑单元除了有从时钟引脚到输出引脚的时序弧,还有相对于时钟引脚的数据引脚时序约束(timing constraint)。每个时序弧都具有特定的时序敏感(timing sense),即输出如何针对输入的不同跳变类型而变化。如果输入引脚上的上升沿跳变导致输出引脚电平上升(或不变),而输入引脚上的下降沿跳变导致输出引脚电平下降(或不变),则时序弧为正单边(positive unate)类型。 例如,与门和或门的时序弧为正单边类型,如下图2-17(a)所示:
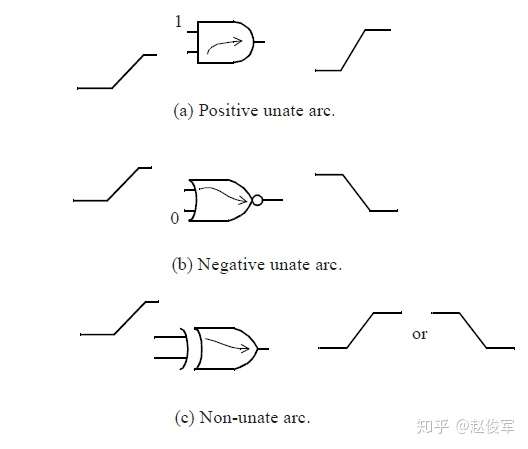
如果输入引脚上的上升沿跳变导致输出引脚电平下降(或不变),而输入引脚上的下降沿跳变导致输出引脚电平上升(或不变),则时序弧为负单边(negative unate)类型。例如,与非门和或非门的时序弧为负单边类型,如上图2-17(b)所示。
在非单边(non-unate)时序弧中,仅仅从一个输入引脚的跳变方向是无法确定输出引脚电平将如何跳变的,还要取决于其他输入引脚的状态。例如,异或门中的时序弧是非单边时序弧,如上图2-17(c)所示。
单边性(unateness)对于时序很重要,因为它指定了输入引脚上电平跳变沿将如何通过逻辑单元传播以及将如何出现在逻辑单元的输出引脚上。
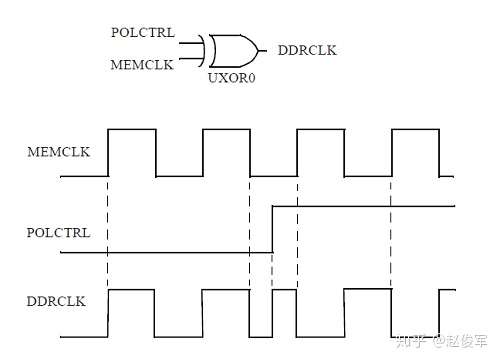
可以利用时序弧的非单边性(如异或门)来反转时钟的极性(polarity)。如下图2-18所示,如果输入POLCTRL为逻辑0,则单元UXOR0的输出上的时钟DDRCLK具有与输入时钟MEMCLK相同的极性。如果POLCTRL为逻辑1,则单元UXOR0的输出时钟的极性与输入时钟MEMCLK的极性相反。
最小与最大时序路径
逻辑通过逻辑路径传播的总延迟称为路径延迟(path delay),包括了逻辑路径中经过各个逻辑单元(cell)和网络走线(net)的延迟。通常,逻辑想要传递到一个终点可能有不止一条逻辑路径可走,所经过的实际路径取决于逻辑路径上其他输入的状态。图2-19给出了一个例子,由于有多个到达逻辑终点的路径,因此可以得出到达逻辑终点的最大时序和最小时序,对应于最大时序和最小时序的路径分别称为最大路径和最小路径。两个节点之间的最大路径是指延迟最大的路径(也称为最长路径),同样,最小路径是指延迟最小的路径(也称为最短路径)。请注意,最长和最短是指路径上的累积延迟,而不是路径上的逻辑单元个数。
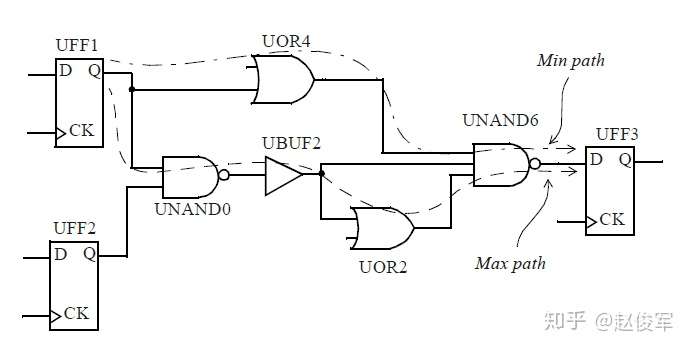
图2-19给出了两级触发器之间数据路径的示例。可以看到经过UNAND0、UBUF2、UOR2和UNAND6单元的路径是触发器UFF1和UFF3之间的最大路径,而经过UOR4和UNAND6单元的路径是触发器UFF1和UFF3之间的最小路径。请注意,本例中所说的最小与最大时序路径都是基于终点是触发器UFF3的D引脚。
通常也称最大路径为晚路径(late path),称最小路径为早路径(early path)。
当考虑从UFF1到UFF3这样的从触发器到触发器的路径时,其中一个触发器发起(launch)数据,另一个触发器捕获(capture)数据。在这种情况下,由于UFF1发起数据,因此UFF1被称为发起触发器(launch flip-flop),由于UFF3捕获数据,因此UFF3被称为捕获触发器(capture flip-flop)。请注意,“发起”和“触发”不是绝对的,一定是相对于某一条时序路径才能决定触发器到底是发起数据还是捕获数据。例如,UFF3发起的数据如果被下一级触发器捕获了,那么在那条时序路径中UFF3则变为了发起触发器。
时钟域
在同步逻辑设计中,周期性的时钟信号将计算出的新数据锁存到触发器中。新的输入数据基于的是前一个时钟周期的触发器值,因此锁存到的数据将被用于计算下一个时钟周期的数据。
一个时钟通常驱动许多触发器,由同一时钟驱动的一组触发器称为其时钟域(clock domain)。在典型的设计中,可能有多个时钟域。例如,USBCLK驱动了200个触发器,而时钟MEMCLK驱动了1000个触发器,如图2-20所示。在此示例中,我们称有两个时钟域。
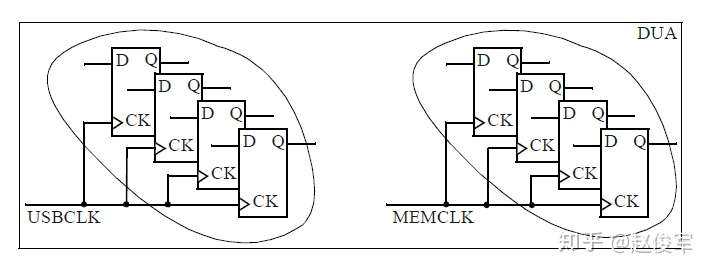
需要关注一个问题:两个时钟域是相关的还是彼此独立的?答案取决于是否存在一条从一个时钟域开始并在另一时钟域结束的数据路径,如果没有这样的路径,我们可以肯定地说这两个时钟域彼此独立,这意味着没有时序路径从一个时钟域开始而在另一时钟域结束。
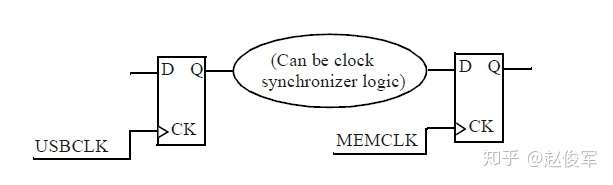
若存在跨时钟域的数据路径(如图2-21所示),则必须确定这些路径是否为真实(real)路径。例如,一个两倍频时钟驱动的触发器发起数据,再由一倍频时钟驱动的触发器捕获数据,这条路径就是一条真实路径。伪路径(false path)的一个例子是设计人员将时钟同步器(clock synchronizer)逻辑明确放置在两个时钟域之间。在这种情况下,即使好像存在从一个时钟域到下一时钟域的时序路径,但这也不是真实的时序路径,因为数据没有被约束要在一个时钟周期之内通过同步器逻辑传播。这样的路径称为伪路径(不是真实的),因为是由时钟同步器来确保数据正确地从一个时钟域传递到另一个时钟域。可以使用set_false_path命令指定时钟域之间的伪路径,例如:
set_false_path -from [get_clocks USBCLK] -to [get_clocks MEMCLK]
虽然无法从图2-21中看到,但实际出现跨时钟域的情况往往是双向的,即从USBCLK时钟域到MEMCLK时钟域,以及从MEMCLK时钟域到USBCLK时钟域,这两种情况都需要在STA中正确理解和处理。
为什么要讨论时钟域之间的路径呢?通常,一个设计中会有多个时钟,并且时钟域之间可能有无数条路径。 分辨出哪些跨时钟域路径是真实的,哪些是伪路径,是时序验证工作的重要组成部分,这使得设计人员可以专注于验证真实的时序路径。
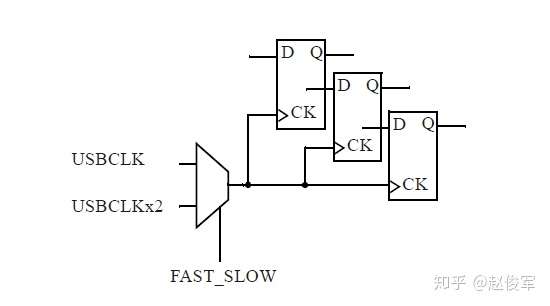
图2-22给出了时钟域的另一个示例,多路复用器(multiplexer)根据设计的工作模式选择时钟源。虽然只有一个时钟域,但却有两个时钟,这两个时钟是互斥的,因为一次只有一个时钟处于有效状态。因此,在这个例子中,USBCLK和USBCLKx2这两个时钟域之间永远不会存在时序路径(假定多路复用器的控制是静态的,并且设计中其余部分也不存在这两个时钟域之间的时序路径)。
工作条件
静态时序分析通常是在特定的工作条件(operating condition)下执行的,工作条件定义为工艺(process)、电压(voltage)和温度(temperature)的组合,简称PVT。逻辑单元延迟和互连线的走线延迟是根据特定的工作条件计算的。
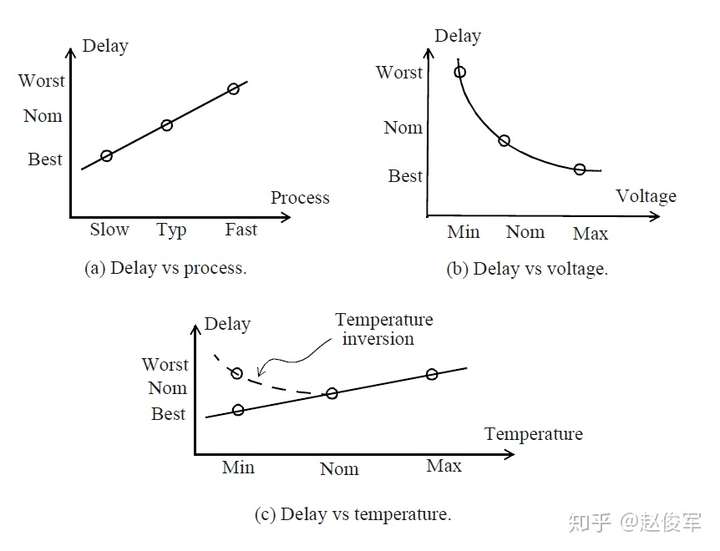
半导体代工厂(foundry)为数字设计提供了3种加工工艺模型:慢速(slow)工艺模型,典型(typical)工艺模型和快速(fast)工艺模型,快速和慢速工艺模型代表了半导体代工厂加工的两个极端工艺角(process corner)。对于稳健(robust)的设计,应该在极端加工工艺角以及温度和电源电压都比较极端的环境下对设计进行验证。图2-23(a)展示了逻辑单元延迟如何随工艺角变化;图2-23(b)展示了逻辑单元延迟如何随电源电压变化;图2-23(c)展示了逻辑单元延迟如何随温度变化。因此,为静态时序分析选择特定的工作条件是非常重要的。
为STA选择合适的工作条件还需要考虑到可用的单元库(cell library),3种标准的工作条件如下所示:
(1)WCS(Worst-Case Slow):工艺慢(slow)、温度最高(例如125°C)并且电压最低(例如额定1.2V减去10%)。对于使用低电源的纳米技术,可能还有另一个最坏的情况:工艺慢、电压最低并且温度也最低。低温下的延迟并不总是小于高温下的延迟,这是因为对于纳米技术而言,相对于电源的器件阈值电压(Vt)裕度降低了。在这种低电源的情况下,负载较小的逻辑单元的延迟在低温下要高于在高温下的延迟。 对于高Vt(较高阈值,较大延迟)甚至是标准Vt(常规阈值,较低延迟)的单元,情况尤其如此。在较低温度下延迟增加的这种异常行为称为温度反转(temperature inversion),参见图2-23(c)。
(2)TYP(Typical):典型(typical)工艺,温度是额定值(例如25°C),电压是额定值(例如1.2V)。
(3)BCF(Best-Case Fast):工艺快(fast),温度最低(例如-40°C),电压最高(例如额定1.2V加10%)。
功耗分析(power analysis)的工作条件通常不同于静态时序分析所使用的工作条件。 对于功耗分析,工作条件可能是:
(1)ML(Maximal Leakage):工艺快,温度最高(例如125°C),电压也最高(例如1.2V加10%)。该工作条件有最大的漏电功耗(leakage power),对于大多数设计,也有着最大的有效功耗(active power)。
(2)TL(Typical Leakage):经典工艺,温度最高(例如125°C),电压是额定值(例如1.2V)。该工作条件下的漏电功耗比较具有代表性,因为由于正常工作时的功耗,芯片温度往往会更高。
静态时序分析基于的是设计人员所加载(load)和链接(link)的库,可以使用set_operating_conditions命令明确指定设计的工作条件。
set_operating_conditions “WCCOM” -library mychip
上述命令使用了在单元库mychip中定义的名为WCCOM的工作条件。
单元库可在各种工作条件下使用,选择何种工作条件进行分析取决于为STA加载的单元库。
标准单元库
本章节介绍库(library)里单元描述中所提供的时序信息。单元可以是标准单元、IO缓冲器或者是如USB内核这样的复杂IP。
●除时序信息外,库单元描述中还包含一些其它属性,例如单元面积和功能,这些属性与时序无关,但在RTL综合(synthesis)过程中会用到。在本章节中,我们仅关注与时序和功耗计算有关的那些属性。
●可以使用各种标准格式来描述库单元,各种格式的内容基本相似,本书中使用Liberty语法描述库单元。
●本章节的前面部分介绍了线性和非线性时序模型,随后介绍了用于纳米技术的高级时序模型,这些将在3.7节中进行介绍。
引脚电容
单元的每个输入和输出都可以在引脚(pin)上指定电容。在大多数情况下,仅为单元输入引脚指定电容,而不为输出引脚指定电容,即大多数单元库中的输出引脚电容为0。

上面的示例展示了输入INP1引脚电容值的一般规格(specification)。在最基本的格式中,引脚电容被指定为单个值(在上面的示例中为0.5个单位)。电容单位通常为皮法拉(pF),一般在库文件的开头指定。单元描述中还可以为rise_capacitance(0.5个单位)和fall_capacitance(0.45个单位)分别指定值,这些值是指引脚INP1上发生电平上升和下降跳变时的值。也可以将rise_capacitance和fall_capacitance的值指定为范围,并在描述中指定下限值和上限值。
时序模型
逻辑单元的时序模型(timing model)旨在为设计中的各种单元实例(instance)提供准确的时序信息。通常会从单元的详细电路仿真中获得时序模型,用以对单元工作时的实际情况进行建模,且需要为逻辑单元的每个时序弧都建立一个时序模型。
让我们首先考虑图3-1中所示的反向器(inverter)的时序弧。 由于这是一个反相器,因此输入端的电平上升(下降)跳变会导致输出端的电平下降(上升)跳变。表征这个反相器的两种延迟是:
●Tr:输出上升沿延迟
●Tf:输出下降沿延迟
注意,延迟是根据单元库中定义的阈值(threshold)点(详见2.4节)测量的,通常为50%Vdd。 因此,延迟值是指从输入经过其阈值点到输出经过其阈值点的延迟。
通过反相器的时序弧的延迟取决于两个因素:
1.输出负载,即反相器输出引脚上的电容负载
2.输入信号的过渡(transition)时间
延迟值与负载电容有直接关系:负载电容越大,延迟越大。在大多数情况下,延迟会随着输入信号过渡时间的增加而增加。而在某些情况下,输入信号阈值点(用于测量延迟)与单元的内部开关点(switching point)明显不同。在这种情况下,通过单元的延迟可能相对于输入信号过渡时间表现出非单调行为:较大的输入信号过渡时间可能会产生较小的延迟,尤其是在输出负载较小的情况下。
逻辑单元输出引脚的压摆(slew)主要取决于输出引脚电容:输出信号过渡时间会随着输出负载的增加而增加。 因此,在输入端压摆较大(输入信号过渡时间较长)的情况下,选择合适的单元类型及输出负载,可以改善输出端的压摆。图3-2展示了通过调节逻辑单元的输出负载,可以改善或恶化单元输出信号过渡时间的情况。
线性时序模型
一个简单的时序模型是线性延迟模型(linear delay model),该模型使用含两个参数的线性函数表示逻辑单元的延迟和输出过渡时间,这两个参数是:输入过渡时间(input transition time)和输出负载电容(output load capacitance)。通过逻辑单元的延迟(D)使用线性模型的一般形式如下所示:
D = D0 + D1 * S + D2 * C
其中D0,D1,D2是常数,S是输入过渡时间,C是输出负载电容。 对于亚微米(submicron)技术,线性延迟模型在输入过渡时间和输出负载电容的范围内并不准确,因此,目前大多数单元库都使用更复杂的模型,例如非线性延迟模型(non-linear delay model)。
非线性延迟模型
大多数单元库都包括表格模型(table model),用于为单元的各种时序弧指定延迟并进行时序检查。一些用于纳米技术的较新的时序库还提供了基于电流源的高级时序模型(例如CCS,ECSM等),本章稍后将对此进行介绍。 这些表格模型被称为NLDM(Non-Linear Delay Model),可用于延迟、输出压摆计算或其他时序检查。表格模型中提供了:在单元输入引脚处输入过渡时间和输出引脚处输出负载电容的各种组合下通过单元的延迟。
NLDM模型以二维形式表示,两个独立变量是输入过渡时间和输出负载电容,表中的数值表示延迟。以下是一个典型反相器单元的表格模型示例:

上面的示例描述了输出引脚OUT的延迟信息。单元描述里的这个部分包含了从引脚INP1到引脚OUT时序弧的上升和下降延迟模型,以及引脚OUT的max_transition允许时间。上升和下降延迟有单独的模型(用于输出引脚),分别标记为cell_rise和cell_fall。索引(index)变量的类型和顺序在以下查找表模板delay_template_3x3中进行了描述:

该查找表模板指定了表中的第一个变量是输入过渡时间,第二个变量是输出负载电容。表中数值的给定类似于嵌套循环,其中第一个索引(index_1)为外部循环变量,第二个索引(index_2)为内部循环变量,依此类推。在上面的示例中每个变量都有三个可能值(条目),因此它对应于一个3×3的表。在大多数情况下,表的条目也可按照表的格式设置,然后可以将第一个索引(index_1)视为行索引,而第二个索引(index_2)则等同于列索引。索引值(例如1000)是伪占位符,它们会被cell_fall和cell_rise延迟表中的实际索引值覆盖。指定索引值的另一种方法是在模板定义中指定索引值,而不是在cell_rise和cell_fall表中指定索引值,例如以下示例:

根据延迟表,输入下降过渡时间为0.3ns且输出负载为0.16pf时,反相器的上升延迟为0.1018ns。 由于输入的下降沿跳变导致反相器输出的上升沿跳变,因此当输入引脚发生下降沿跳变时,应该去查询cell_rise延迟表。
将表格中的延迟值表示为输入过渡时间和输出负载电容这两个变量的函数的这种形式称为非线性延迟模型,因为在这些表格中可以看到延迟随输入过渡时间和输出负载电容的非线性变化。
注意,表格模型也可以是3维的,例如一个具有互补输出Q和QN的触发器,这将在3.8节中进行介绍。
NLDM模型不仅可以用于计算延迟,而且还可用于计算逻辑单元输出引脚的过渡时间,该时间同样由输入过渡时间和输出负载电容来表征。因此,还存在着另外一张独立的用于计算单元的输出上升和下降过渡时间的二维表格。

输出过渡时间也同样有两张表:rise_transition和fall_transition。如第2章所述,过渡时间是根据特定的压摆阈值点(通常为电源的10%-90%)测量的。
综上所述,使用NLDM模型的反相器单元具有下列表格模型:
● 上升延迟时间(Rise delay)
● 下降延迟时间(Fall delay)
● 上升过渡时间(Rise transition)
●下降过渡时间(Fall transition)
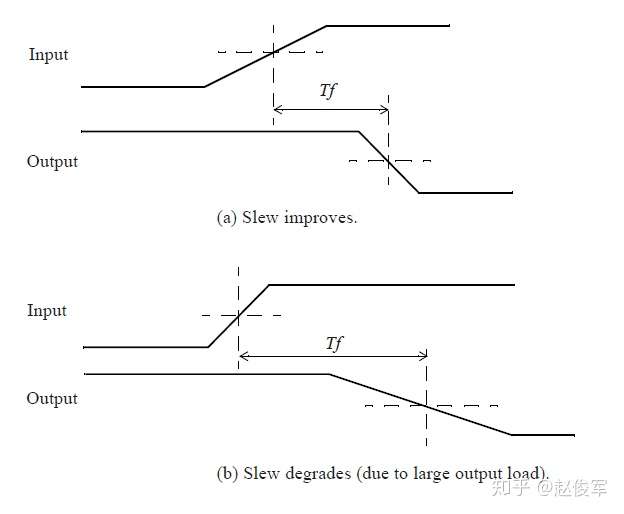
假设有这么一个反相器单元,其输入过渡时间和输出负载电容如图3-3所示。对于15ps的输入(下降)过渡时间和10fF负载,可从cell_rise表中获得输出上升延迟时间,而从cell_fall表中可获得20ps输入(上升)过渡时间和10fF负载下的输出下降延迟时间 。
指定单元逻辑功能为“反相”(invert)的信息在哪里呢?该信息可以在时序弧里的timing_sense字段中找到,但在某些情况下如果该字段中未指明,则应该也可从引脚功能(pin function)中推断出。
例如对于反相器单元,时序弧为negative_unate,这表明输出引脚电平跳变方向与输入引脚电平跳变方向相反。因此,在cell_rise表中进行查找时使用的参数是输入引脚的下降过渡时间。
查找非线性延迟模型
这个小节通过一个例子来说明表格模型的查找。如果输入过渡时间和输出电容正好与表格条目中的值相对应,则表格查找是很简单的,因为可以直接从表中对应的位置读出时序值。以下示例对应于一般情况,即输入过渡时间和输出电容无法与表格条目中的值对应的情况。在这种情况下,可利用二维插值的方法来得到最终的时序值,一般选择每个维度中两个最接近的表格条目中的值以进行表格插值。考虑输入过渡时间为0.15ns、输出电容为1.16pF的输出下降沿查找表(前文的示例), 下面复制了与二维插值有关的输出下降过渡表的相应部分。

在下面的公式中,两个index_1值分别表示为x1和x2;两个index_2值分别表示为y1和y2,而对应的表值分别表示为T11,T12,T21和T22。
如果需要在表中查找(x0,y0)的值,则查找值T00只能通过插值获得,计算公式如下:
T00 = X20 * Y20 * T11 + X20 * Y01 * T12 + X01 * Y20 * T21 + X01 * Y01 * T22
其中
X01 = (x0 - x1)/(x2 - x1)
X20 = (x2 - x0) /(x2 - x1)
Y01 = (y0 - y1)/(y2 - y1)
Y20 = (y2 - y0)/(y2 - y1)
将0.15ns代入index_1,将1.16pF代入index_2,根据上述公式可计算出fall_transition值为:
T00 = 0.75 * 0.25 * 0.1937 + 0.75 * 0.75 * 0.7280 + 0.25 * 0.25 * 0.2327 +0.25 * 0.75 * 0.7676 = 0.6043
请注意,上面的等式对于内插和外推均有效,即当索引值(x0,y0)超出范围时依然成立。例如,当index_1索引值为0.05且index_2索引值为1.7时,fall_transition值计算如下:
T00 = 1.25 * (-0.25) * 0.1937 + 1.25 * 1.25 * 0.7280 + (-0.25)(-0.25) 0.2327 + (-0.25) * 1.25 * 0.7676 = 0.8516
阈值规格和压摆降额
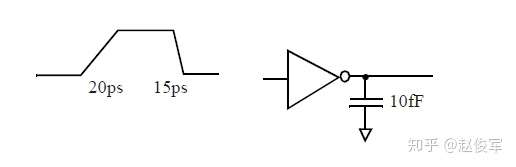
压摆值(slew)基于的是在库中指定的测量阈值点,大多数上一代的库(0.25um或更旧的库)都使用10%和90%作为压摆(或称过渡时间)的测量阈值点。
压摆阈值点的选择对应的是波形的线性部分。随着技术的发展,实际波形最线性的部分通常在30%至70%之间。 因此,大多数新一代时序库都将压摆测量阈值点指定为Vdd的30%和70%。但是,由于之前测得的过渡时间在10%至90%之间,因此在填充库时,通常将测得的30%至70%的过渡时间加倍,这由压摆降额系数(slew derate factor)指定,通常指定为0.5。压摆测量阈值点为30%和70%且压摆降额系数为0.5,等效于测量阈值点为10%和90%。 阈值设置的示例如下:

上面的设置规定了要将表格中的过渡时间乘以0.5,以获得与阈值(30%-70%)设置相对应的过渡时间。这意味着表格中的值(以及相应的索引值)实际上是10%-90%阈值点的测量值。在标定过渡时间值时,首先在30%-70%处测量,然后再把测量值外推到10%至90%((70-30)/(90-10)= 0.5)。
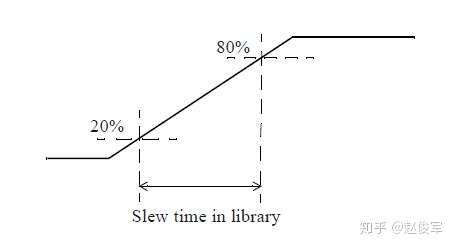
以下是压摆测量阈值点设置的另一个例子:
slew_lower_threshold_pct_fall:20.0;
slew_upper_threshold_pct_fall:80.0;
slew_lower_threshold_pct_rise:20.0;
slew_upper_threshold_pct_rise:80.0;
slew_derate_from_library not specified
在上述20%-80%压摆阈值设置的例子中,未指定slew_derate_from_library(默认值为1.0),这意味着库中的过渡时间不会降额(derate)。表格中的过渡时间值直接对应于20%-80%的阈值点,如图3-4所示:
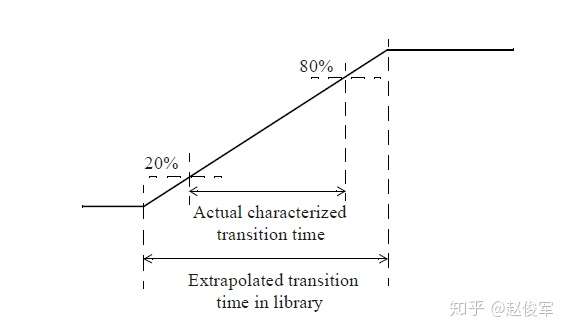
对上述单元库中压摆阈值设置稍作修改,如下所示:
slew_lower_threshold_pct_fall:20.0;
slew_upper_threshold_pct_fall:80.0;
slew_lower_threshold_pct_rise:20.0;
slew_upper_threshold_pct_rise:80.0;
slew_derate_from_library:0.6;
在这种情况下,将slew_derate_from_library设置为0.6,并将压摆测量阈值点指定为20%和80%,这意味着库中的过渡时间表里的数据对应于外推到0%至100%((80-20)/(100-0)= 0.6)的值,如图3-5所示:
指定了压摆降额后,计算延迟时使用的压摆值等于:
库中过渡时间值 * 压摆降额系数 ( library_transition_time_value * slew_derate)
这就是延迟计算工具在内部使用的压摆值,是对应于指定的压摆阈值测量点的。
时序模型-组合逻辑单元
考虑一个两输入与门(and)的时序弧,由前面章节所述可知该单元的两个时序弧均为正单边类型(positive_unate), 因此,输入引脚的电平上升对应于输出引脚的电平上升,反之亦然。
对于这个两输入与门,共有以下4种延时:
● A -> Z :输出上升沿延迟(Output rise)
● A -> Z :输出下降沿延迟(Output fall)
● B -> Z :输出上升沿延迟(Output rise)
● B -> Z :输出下降沿延迟(Output fall)
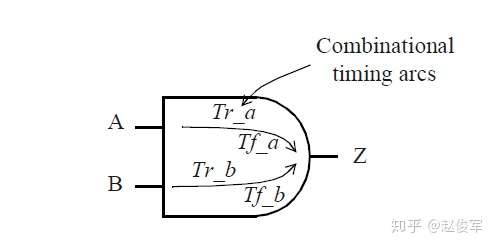
这意味着对于NLDM模型,将会有四个表格模型用于指定延迟。同样,也将有四个表格模型用于指定输出过渡时间(压摆)。
延迟与压摆模型
以下是一个用于分析三输入与非门(nand)单元的输入INP1到输出OUT的时序模型:


在上面的例子中,使用了两个单元延迟表cell_rise和cell_fall以及两个过渡时间表rise_transition和fall_transition来描述从INP1到OUT的时序弧的特性,上面的例子中还包括了输出的最大过渡时间(max_transition)值。
如章节2.7中所述,与非门单元中的时序弧为负单边类型(negative unate),这表示输出引脚电平跳变方向与输入引脚电平跳变方向是相反的。因此,查找cell_rise表对应于输入引脚上的下降过渡时间。同样,通过与门单元或者或门单元的时序弧是正单边类型(positive unate)的,因为输出引脚电平跳变方向与输入引脚电平跳变方向相同。
通用组合逻辑块
考虑以下这个具有三输入和两输出的通用组合逻辑块(General Combinational Block):
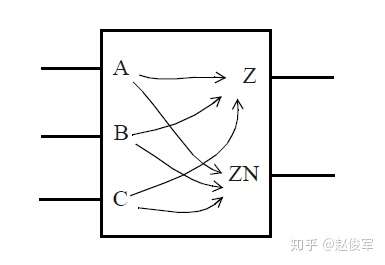
像这样的组合逻辑块可以具有多个时序弧。通常,从块的每个输入到每个输出都有一条时序弧。如果从输入到输出的逻辑路径是同相(non-inverting)或正单边类型的,则输出的极性(polarity)与输入的极性相同;如果逻辑路径是反相(inverting)或负单边类型,则输出的极性与输入相反,即当输入电平上升时,输出电平将下降。这些时序弧代表了通过这个组合逻辑块的传播延迟。
通过组合逻辑单元的某些时序弧可以既是正单边类型,也是负单边类型的。一个例子是通过两输入异或门(xor)单元的时序弧,根据该单元的另一个输入的逻辑状态,两输入异或门单元的输入引脚处的电平跳变会导致输出引脚处的电平沿相同或相反的方向跳变。这些时序弧可以描述为非单边类型(non-unate)的,也可以描述为两组状态相关(state-dependent)的正单边类型时序模型和负单边类型时序模型。这种与状态相关的表格模型将在3.5节中有更详细的描述。
时序模型-时序逻辑单元
考虑如下图3-8所示的时序逻辑单元的时序弧:
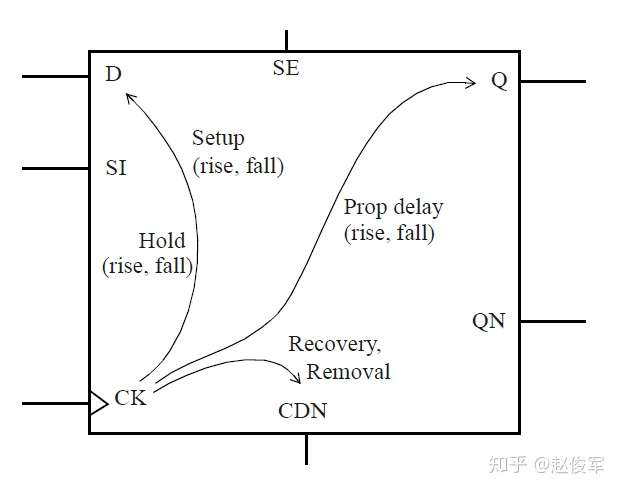
对于同步(synchronous)输入,例如引脚D(或SI,SE),存在以下时序弧:
● 建立(Setup)时间检查时序弧(包括上升沿和下降沿)
● 保持(Hold)时间检查时序弧(包括上升沿和下降沿)
对于异步(asynchronous)输入,例如引脚CDN,存在以下时序弧:
● 恢复(Recovery)时间检查时序弧
● 撤销(Removal)时间检查时序弧
对于触发器的同步输出,例如引脚Q或QN,存在以下时序弧:
● 时钟引脚(CK)到输出端口(Q或QN)的传播延迟时序弧(包括上升沿和下降沿)
所有同步时序弧均相对于时钟的有效沿(active edge),即时序逻辑单元捕获数据的时钟沿。此外,时钟引脚和异步引脚(如复位引脚)还需要进行脉冲宽度(pulse width)时序检查。各种时序检查如下图3-9所示:
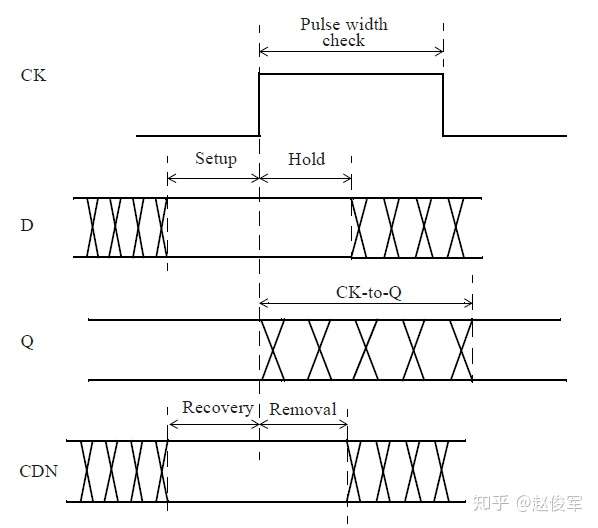
同步时序检查:建立时间与保持时间
需要进行建立时间和保持时间的同步时序检查,才能确保数据能够正确通过时序单元传播。这些时序检查可验证输入的数据在时钟有效沿上是否为确定的逻辑状态,并且在有效沿上将正确的数据锁存下来。这些时序检查也可以验证输入的数据在有效时钟沿附近是否稳定:输入的数据必须在有效时钟沿之前保持稳定的最短时间称为建立时间(setup time)。这是根据最晚的(the latest)数据信号超过其阈值(通常为Vdd的50%)到有效时钟沿超过其阈值(通常为Vdd的50%)的时间间隔测量的。同样,保持时间(hold time)是在时钟有效沿之后输入的数据必须保持稳定的最短时间,这也是根据有效时钟沿超过其阈值到最早的(the earliest)数据信号超过其阈值的时间间隔来度量的。如前文所述,时序单元的时钟有效沿是指使时序单元捕获数据的上升沿或下降沿。
建立时间与保持时间检查示例
时序单元同步引脚的建立时间和保持时间约束通常用二维表格来描述,如下所示。下面的例子展示了触发器数据引脚的建立时间和保持时间时序信息:


上面的例子展示了相对于时序单元时钟引脚CK的上升沿,在输入引脚D上的建立时间和保持时间约束。二维表格模型是根据约束引脚constrained_pin(D)和相关引脚related_pin(CK)处的过渡时间确定的,二维表格的查找是基于库中描述的模板setuphold_template_3x3的。对于上述示例,查找表模板setuphold_template_3x3如下所示:

与前面示例中一样,表中的值如嵌套循环一样被指定,其中第一个索引index_1是外部循环变量,第二个索引index_2是内部循环变量, 以此类推。因此,当D引脚的上升沿过渡时间为0.4ns,CK引脚的上升沿过渡时间为0.84ns时,D引脚上升沿的建立时间约束为0.112ns,该值是从rise_constraint表中读取的。对于D引脚的下降沿,建立时间约束将检查建立时间表中的fall_constraint表。在表中查找过渡时间不与索引值相对应的建立时间和保持时间约束时,可使用章节3.2中所描述的非线性模型查找的一般过程。
请注意,建立时间约束的rise_constraint和fall_constraint表是指constrained_pin。所用的时钟过渡时间由Timing_type决定,它会指定该时序逻辑单元是上升沿触发还是下降沿触发。
建立时间和保持时间检查里的负值
请注意,上面示例中的某些保持时间值是负数。这是可以接受的,这种情况通常发生在触发器的引脚到数据内部锁存点的路径长于相应的时钟路径时。因此,负的保持时间检查意味着触发器的数据引脚可以在时钟引脚之前改变,并且仍然满足保持时间的检查要求。
触发器的建立时间值也可以为负。这意味着触发器的数据引脚可以在时钟引脚之后改变,并且仍然满足建立时间的检查要求。
建立时间和保持时间可以都为负吗?不行!为使建立时间和保持时间检查相一致,建立时间和保持时间的数值总和应为正。因此,如果建立(或保持)时间检查包含负值,则相应的保持(或建立)时间检查应为正值,且足够大,以使建立时间加上保持时间之和是一个正数。 具有负的保持时间值的示例如图3-10所示,由于建立时间检查会先于保持时间检查,所以此时的建立时间加上保持时间显然是一个正数。建立时间加上保持时间即为要求数据信号稳定的区域的宽度。
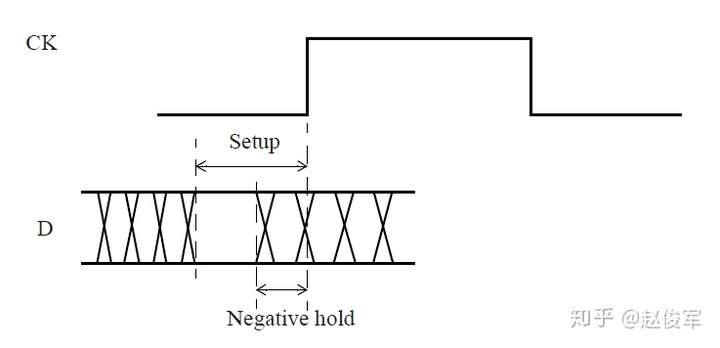
对于触发器,在扫描数据(scan data)输入引脚上设置一个负的保持时间会很有帮助,这样可以给予时钟偏斜(clock skew)一定的灵活性,并且可以消除当扫描模式(scan mode)下保持时间发生违例时插入缓冲器(buffer)的需要(扫描模式是将触发器串联在一起形成一条扫描链的模式,触发器的输出通常连接到串联的下一个触发器的扫描数据输入引脚,这些连接是用于芯片测试的)。
与同步数据输入引脚上的建立时间或保持时间检查类似,对异步引脚进行的时序约束检查将在下个小节中介绍。
异步时序检查
恢复时间和撤销时间检查
诸如异步复位(clear)或异步置位(set)之类的异步引脚会覆盖单元的任何同步行为。当异步引脚处于有效(active)状态时,输出将由异步引脚控制,而不是由时钟锁存到的输入数据控制。但是,当异步引脚变为无效(inactive)状态时,时钟的有效边沿将开始锁存输入的数据。异步恢复(recovery)时间和撤销(removal)时间约束检查将验证异步引脚在下一个时钟有效沿处是否已明确返回到了无效状态。
恢复时间是指异步输入被置为无效(de-asserted)后在下一个时钟有效沿之前需要保持稳定的最短时间。
同样,撤销时间是指在一个有效的时钟沿之后,异步引脚必须保持有效状态的最小时间,即在有效时钟沿之后必须经过一段撤销时间才能够将异步引脚置为无效状态。
异步恢复时间和撤销时间检查将分别在8.6节和8.7节中介绍。
脉冲宽度检查
除了同步和异步时序检查外,还有一项检查去确保逻辑单元输入引脚上的脉冲宽度满足最低要求。例如,如果时钟引脚上的脉冲宽度小于指定的最小值,则时钟可能无法正确锁存数据。也可以为相关的同步和异步引脚指定脉冲宽度检查(pulse width check),并且可以为高脉冲和低脉冲分别指定最小脉冲宽度检查。
恢复时间、撤销时间和脉冲宽度检查示例
下面给出了触发器的异步清零引脚CDN的恢复时间、撤销时间和脉冲宽度检查的示例,其中恢复时间和撤销时间检查还与时钟引脚CK有关。由于恢复时间和撤销时间检查是针对异步引脚被置为无效的时刻,因此在以下示例中仅存在上升约束。CDN引脚的最小脉冲宽度检查用于低脉冲,这是由于CDN引脚为低电平有效,因此该引脚上的高脉冲宽度没有限制,因此未指定。


传播延迟
时序单元的传播延迟(propagation delay)是指从时钟的有效沿到输出的上升沿或下降沿。以下是一个时钟下降沿触发的触发器从时钟引脚CKN到输出Q的传播延迟弧的示例。这是一个非单边类型(non-unate)的时序弧,因为时钟的有效沿会导致输出引脚Q的电平上升或下降。


与前一章中的示例一样,输出的传播延迟会根据输入过渡时间和输出负载电容以二维表格的形式呈现。但是在此示例中,由于触发器是时钟下降沿触发的,因此要使用的输入过渡时间是CKN引脚的下降过渡时间,这在上面的示例中可以从Timing_type字段中看出,上升沿触发的触发器将把rising_edge指定为其timing_type。

状态相关的时序模型
在许多组合逻辑模块中,输入和输出之间的时序弧取决于模块中其他引脚的逻辑状态。输入和输出引脚之间的这些时序弧可以是正单边类型时序弧、负单边类型时序弧也可以既是正单边类型又是负单边类型时序弧。异或门(xor)以及同或门(xnor)单元就是一个例子,其输入到输出的时序弧可以是正单边类型的也可以是负单边类型的。 在这种情况下,其时序行为可能会有所不同,具体取决于该模块其他输入的状态。通常,取决于引脚状态的多个时序模型被称为状态相关的时序模型(state-dependent models)。
考虑一个两输入异或门单元的例子。当另一个输入A2为逻辑0时,从输入A1到输出Z的时序路径为正单边类型;当输入A2为逻辑1时,从A1到Z的路径为负单边类型。这两个时序模型是使用状态相关的时序模型指定的。A2为逻辑0时从A1到Z的时序模型如下所示:


使用when来指定与状态有关的条件。虽然以上单元模型的片段仅说明了cell_rise延迟,但其它时序模型(cell_fall,rise_transition和fall_transition)也指定了相同的when条件。当when中条件改变,如改为A2为逻辑1这个条件时,会指定另一个独立的时序模型:

sdf_cond用于指定生成SDF文件时要使用的时序弧的条件,详情参见后面3.9节中的示例。
状态相关的时序模型可用于各种类型的时序弧,许多时序逻辑单元会使用状态相关的时序模型指定建立时间或保持时间的时序约束。以下是使用状态相关的时序模型进行保持时间约束的扫描触发器(scan flip-flop)的一个示例。在这种情况下,指定了两组时序模型:扫描使能引脚SE处于有效状态时的一组,以及扫描使能引脚处于无效状态时的另一组。

当扫描使能引脚SE为逻辑0时使用以上时序模型,当when中条件为SE是高电平时也有类似的时序模型。
可以既使用状态相关的时序模型又使用非状态相关的时序模型来指定一些时序关系。在这种情况下,如果单元的状态是已知的并且这个状态包含在状态相关的时序模型之一中,则时序分析将使用状态相关的时序模型。而如果状态相关的时序模型未包含单元的这个状态,则使用来自非状态相关模型的时序。例如考虑一种情况,保持时间约束仅由当when条件为SE处于逻辑0时来指定,而没有为SE处于逻辑1时指定单独的状态相关模型。在这种情况下,如果SE被置为逻辑1,则将会使用非状态相关时序模型的保持时间约束。而如果没有用于保持时间约束的非状态相关时序模型,那么将没有任何有效的保持时间约束!
可以为时序库中的任何属性指定状态相关的模型,因此可以存在功率、漏电功率、过渡时间、上升和下降延迟、时序约束等状态相关的模型。下面给出了一个状态相关的漏电功率模型示例:

黑盒的接口时序模型
本节将介绍黑盒(任意模块或块)的IO接口时序弧,时序模型将捕获黑盒(black box)IO接口(interface)的时序。黑盒的接口时序模型可以具有组合逻辑弧,也可以有时序逻辑弧。通常,这些时序弧也可能取决于状态。
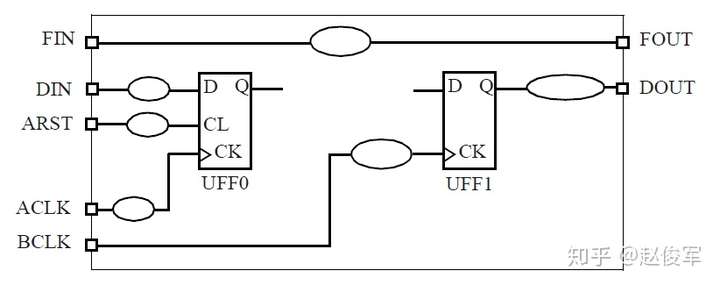
对于如图3-11所示的例子,可以将时序弧分为以下几类:
● 输入到输出的组合逻辑弧:这对应于直接从输入到输出的组合逻辑路径,例如从输入端口FIN到输出端口FOUT。
● 输入时序逻辑弧:这对应于连接到触发器D引脚的输入端口的建立时间或保持时间。通常,在将模块的输入端口连接到触发器的D引脚之前,可以存在一些组合逻辑。这样的一个例子是在输入端口DIN上相对于时钟端口ACLK的建立时间检查。
● 输出时序逻辑弧:这类似于触发器时钟端到输出端Q的传播延迟。通常,触发器输出引脚与模块输出端口之间可以存在一些组合逻辑。一个示例是从时钟BCLK到触发器UFF1的输出引脚再到输出端口DOUT的路径。
● 异步输入时序弧:这类似于触发器异步输入引脚的恢复时间和撤销时间时序约束,例如输入端口ARST到触发器UFF0的异步清零引脚。
除上述时序弧外,在黑盒的外部时钟引脚上还可以进行脉冲宽度检查。还可以定义内部节点(node)并在这些内部节点上定义衍生时钟(generated clock),从而指定在这些节点之间的时序弧。总之,黑盒模型可以具有以下时序弧:
● 纯组合逻辑路径的输入到输出时序弧(Input to output timing arcs)
● 从同步输入端口到相关时钟端口的建立时间和保持时间时序弧(Setup and hold timing arcs)
● 从异步输入端口到相关时钟端口的恢复时间和撤销时间时序弧(Recovery and removal timing arcs)
● 从时钟端口到输出端口的输出传播延迟(Output propagation delay)
如上所述的接口时序模型并非旨在捕获黑盒的内部时序,而只是捕获其接口上的时序。
高级时序建模
非线性延迟模型(NLDM)这类的时序模型是基于输出负载电容和输入过渡时间来表示通过时序弧的延迟的。实际上,单元输出的负载不仅包括电容还应当包括互连电阻(interconnect resistance)。由于NLDM方法假设输出负载为纯电容,因此互连电阻成为了一个问题。即使互连电阻不为零,但当互连电阻的影响较小时,仍使用了这些NLDM模型。在互连电阻存在的情况下,延迟的计算方法通过在单元的输出端获得等效的有效电容(effective capacitance)来改进NLDM模型。延迟计算工具中使用的“有效”电容法获得的等效电容可保证单元输出延迟与具有RC互连的单元输出延迟相同。有效电容法将在5.2节里的延迟计算部分再详细介绍。
随着特征尺寸的缩小,由于波形变得高度非线性,互连电阻的影响会导致较大的误差,各种建模方法为单元的输出驱动能力提供了更高的精度。通常,这些方法通过用等效电流源对驱动器(driver)的输出级进行建模来获得更高的精度。例如CCS(Composite Current Source)复合电流源或ECSM(Effective Current Source Model)有效电流源模型:CCS时序模型通过使用随时间变化且依赖电压的电流源,为建模单元输出驱动能力提供了更高的精度。通过为不同情况下的接收引脚电容(receiver pin capacitance)和输出充电电流(output charging currents)指定详细时序模型,可以提供时序信息。接下来描述CCS模型的细节。
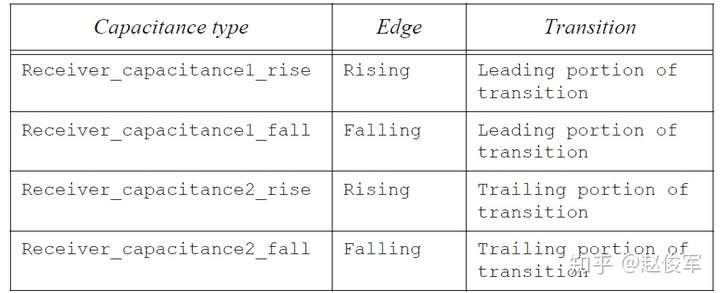
接收引脚电容
接收引脚电容对应于NLDM模型中指定的输入引脚电容(input pin capacitance)。与NLDM模型的输入引脚电容不同,CCS模型允许在过渡波形的不同部分分别指定接收引脚电容。由于互连RC和由单元内部输入设备的米勒效应(Miller effect)所引起的等效输入非线性电容,接收引脚电容值会在过渡波形的不同点处发生变化。因此,该电容值在波形的初始部分(leading portion)与在波形的后续部分(trailing portion)的建模是不同的。
接收电容可以在引脚级别(pin level)上指定(如NLDM模型),通过该引脚的所有时序弧都使用该电容值;或者,接收电容可以在时序弧(timing arc level)级别上指定,在这种情况下可以为不同的时序弧指定不同的电容模型。接下来将介绍这两种指定接收引脚电容的方法。
在引脚级别指定电容
当在引脚级别指定电容时,接收引脚电容的一维表格示例如下:

index_1指定了此引脚输入过渡时间的索引值,一维表格values为波形的初始部分指定了输入引脚上用于上升沿波形的接收电容。
与上面示例中的receiver_capacitance1_rise表格类似,receiver_capacitance2_rise表格为波形的后续部分指定了输入引脚上用于上升沿波形的接收电容。而下降电容(用于下降沿输入波形的引脚电容)分别由表格receiver_capacitance1_fall和receiver_capacitance2_fall指定。
在时序弧级别指定电容
接收引脚电容值也可以在时序弧级别上,根据输入过渡时间和输出负载以二维表格的形式来指定。以下给出了在时序弧级别指定电容的示例。本示例指定了输入引脚IN上波形初始部分的接收引脚上升电容,该电容取决于输入引脚IN上的过渡时间和输出引脚OUT上的负载。


上面的示例指定了receiver_capacitance1_rise的模型,库中也包含有关receiver_capacitance2_rise、receiver_capacitance1_fall和receiver_capacitance2_fall的类似定义。
下表总结了四种不同类型的接收电容类型。如上所述,可以在引脚级别将它们指定为一维表格,或在时序弧级别将它们指定为二维表格。
输出电流
在CCS模型中,非线性时序表现为输出电流。输出电流信息被指定为一个查找表,该表的查找取决于输入过渡时间和输出负载。
输出电流会根据输入过渡时间和输出负载电容的不同组合被指定,对于每一个组合,都将分别指定一个输出电流波形。本质上,此处的波形指的是随时间变化的输出电流值。以下示例使用output_current_fall指定了用于下降输出波形的输出电流:
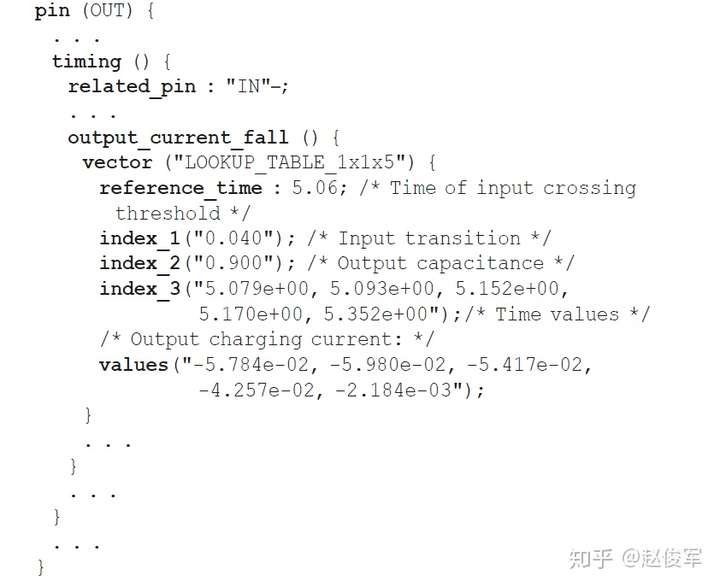
reference_time是指输入波形超过延迟阈值的时间,index_1和index_2是指输入过渡时间和所使用的输出负载电容,而index_3是时间。index_1和index_2(输入过渡时间和输出负载电容)只能有一个值,index_3是指时间值,表值是指相应的输出电流。因此,对于给定的输入过渡时间和输出负载,输出电流波形是时间的函数。同样,还指定了用于输入过渡时间和输出电容的其他组合的查找表。
类似地可以使用output_current_rise去指定上升输出波形的输出电流。
串扰噪声分析模型
本节介绍用于串扰噪声(或毛刺)分析的CCS模型,又被称为CCSN(CCS Noise)模型。CCS噪声模型是结构(structural)模型,并针对单元内的不同沟道连接块-CCB(Channel Connected Blocks)表示。
什么是CCB? CCB是指单元的源极(source)-漏极(drain)的沟道(channel)连接部分。例如,单级(single stage)单元(例如反相器、与非门和或非门单元)仅包含一个CCB,即整个单元仅通过一个沟道连接区域进行连接,而多级单元(例如与门和或门单元)包含多个CCB。
通常仅为由单元输入驱动的第一个CCB和驱动单元输出的最后一个CCB指定CCSN模型,并且会使用稳态电流、输出电压和传播噪声模型来指定这些CCSN模型。
对于单级组合逻辑单元(例如与非门和或非门单元),将为每个时序弧指定CCS噪声模型。 这些单元只有一个CCB,因此模型将会是从单元的输入引脚到输出引脚的。
以下是一个与非门单元的模型示例:


现在我们描述CCS噪声模型的属性:ccsn_first_stage字段表示该模型用于与非门单元的第一级CCB。如前所述,与非门单元只有一个CCB。is_needed字段几乎始终为true,但天线单元(antenna cell)等非功能性单元除外。stage_type字段中的both表示该级CCB同时具有上拉(pull-up)和下拉(pull-down)结构。miller_cap_rise和miller_cap_fall分别代表输出上升和下降过渡时的米勒(Miller)电容值。
直流电流
dc_current表中为输出引脚上针对输入和输出引脚电压不同组合的的直流电流,其中index_1为输入电压,index_2为输出电压, 二维表格中的数值为CCB输出处的直流电流。输入电压和输出电流均在库中指定单位(通常为伏特和毫安)。对于从与非门单元的输入引脚IN1到输出引脚OUT的CCS噪声模型示例,当输入电压为-0.9V并且输出电压为0V时,输出端的直流电流为0.42mA。
输出电压
output_voltage_rise和output_voltage_fall表中分别包含CCB输出上升和下降的时序信息。这些表格是CCB输出节点的多维表格,指定了针对不同输入过渡时间和输出电容的上升和下降输出电压。每个表格的index_1指定了轨到轨输入过渡时间,index_2指定了输出电容,index_3指定了输出电压超过特定阈值点的时间(在这种情况下,为0.9V的Vdd电源的30%,70%和90%)。在每个多维表中,电压交叉点(voltage crossing points)是固定的,并且CCB输出节点与电压交叉时的时间值在index_3中指定。
噪声传播
propagated_noise_high模型和propagated_noise_low模型指定的多维表格提供了通过CCB的噪声传播信息。这些模型表征了串扰毛刺(或噪声)从CCB的输入到输出的传播,表征时输入端使用了对称的三角波。噪声传播的多维表被组织为了多个表,这些表指定了CCB输出处的毛刺波形。这些多维表包含:
● 输入毛刺幅值(index_1)
● 输入毛刺宽度(index_2)
● CCB输出电容(index_3)
● 时间(index_4)
表格中的数值指定了CCB输出电压(或通过CCB传播的噪声)。
两级单元的噪声模型
与单级单元一样,两级单元(例如与门和或门单元)的CCS噪声模型通常被描述为时序弧的一部分。由于这些单元包含两个单独的CCB,因此需要分别为ccsn_first_stage和ccsn_last_stage指定噪声模型。例如,对于两输入与门单元,CCS噪声模型由第一级和最后一级相互独立的模型组成,如下所示:

为IN2引脚指定的ccsn_last_stage中的模型与为IN1引脚指定的ccsn_last_stage中的模型是相同的。
多级单元和时序单元的噪声模型
通常将较为复杂的组合逻辑单元或时序逻辑单元的CCS噪声模型描述为引脚规范(pin specification)的一部分,这与前面在单级或二级单元的CCS噪声模型中以引脚对(pin-pair)为基础,指定为时序弧的一部分是不同的。通常由所有输入引脚的ccsn_first_stage模型和所有输出引脚的ccsn_last_stage模型描述复杂的多级和时序单元。这些单元的CCS噪声模型不是时序弧的一部分,但通常是为引脚指定的。
如果输入和输出之间的内部路径多达两级CCB,则噪声模型也可以表示为引脚对时序弧的一部分。通常,多级单元中可以将某些CCS噪声模型指定为引脚对时序弧的一部分,而其他一些噪声模型可以通过引脚说明来指定。
下面的示例使用引脚说明以及时序弧的一部分指定了CCS噪声模型:


请注意,上述触发器单元的某些CCS模型是通过引脚定义的。使用输入引脚上的引脚说明定义的指定为ccsn_first_stage,而输出引脚QN上的CCS模型指定为ccsn_last_stage。另外,两级CCS噪声模型被描述为CDN到Q的时序弧的一部分。因此本示例表明,一个单元可以具有指定为引脚说明一部分和时序弧一部分的CCS模型。
其它噪声模型
除了上述CCS噪声模型之外,某些单元库还提供了其他模型来表征噪声。早在CCS噪声模型出现之前,就已经使用了其中一些模型。如果CCS噪声模型可用,则不需要这些附加模型。为了完整起见,我们在下面介绍一些早期的噪声模型。
直流裕度模型(Models for DC margin):直流裕度是指单元输入引脚允许的最大直流变化(DC variation),它将使单元保持稳定状态,即不会在输出端引起毛刺。例如,低电平输入的直流裕度指的是输入引脚上最大的直流电压值,而不会在输出端引起任何电平跳变。
抗扰度模型(Models for noise immunity):抗扰度模型指定输入引脚可以允许的毛刺幅度(glitch magnitude)。通常以二维表的形式来描述,其中毛刺宽度和输出电容为两个索引量,表中的值对应于输入引脚可以允许的毛刺幅度。这意味着任何小于指定幅度和宽度的毛刺都不会通过单元传播。抗扰度模型还具有不同变形形式,例如:
● noise_immunity_high
● noise_immunity_low
● noise_immunity_above_high
● noise_immunity_below_low
功耗建模
单元库中也包含与单元功耗有关的信息,包括有功功率(active power)以及待机(standby)或漏电(leakage)功率。顾名思义,有功功率与设计中的行为有关,而待机功率是待机模式下的功耗,这主要是由于漏电引起的。
有功功率
有功功率与单元输入和输出引脚上的行为有关。单元中的有功功率是由于输出负载的充电以及内部的开关引起的,通常分别称这两个为输出开关功率(output switching power)和内部开关功率(internal switching power)。
输出开关功率与单元类型无关,仅取决于输出负载电容、开关频率和供电电源;内部开关功率取决于单元的类型,因此该值会包含在单元库中,接下来将介绍库中的内部开关功率。
内部开关功率在单元库中被称为internal power,这是当单元的输入或输出处于活动状态时单元内部的功耗。对于组合逻辑单元,输入引脚的电平跳变会导致输出引脚的电平跳变,从而导致内部开关功耗。例如,每当输入引脚电平跳变(上升或下降)时,反相器单元就会消耗功率。 库中描述的内部开关功率如下所示:


上面的示例展示了单元从输入引脚A到输出引脚Z1的功耗,模板中的2x2表是根据引脚A上的输入过渡时间和引脚Z1上的输出电容来确定的。注意,尽管该表包含了输出电容,但表中的值仅对应于内部开关,不包括输出电容的影响。该值表示每个开关转换(上升或下降)时在单元中耗散的内部能量,单位是从库中的其他单位导出的(通常电压以伏特V为单位,电容以皮法拉pF为单位,并且表示为以皮焦耳pJ为单位的能量)。因此,库中的内部开关功率实际上是指每次开关转换时内部所消耗的能量。
除了内部开关功率表之外,上面的示例中还给出了电源引脚、接地引脚的说明,并且指定了可将单元断电的条件。这些构造允许在设计和方案中使用多个电源,在这些情况下可以关闭不同的电源。下面展示了单元的电源引脚说明:


功率描述的语法允许上升和下降(指输出过渡方向)功率使用单独的构造。就像时序弧一样,功率描述也可能取决于状态。例如,可以将异或门(XOR)单元的状态相关功耗指定为取决于各种输入的状态。
对于组合逻辑单元,开关功率是基于输入-输出引脚对指定的。但是,对于诸如具有互补输出Q和QN的触发器之类的时序单元来说,CLK-> Q转换也会导致CLK-> QN转换。因此,该库可以将内部开关功率指定为三维表格,如下所示。下例中的三个维度分别是CLK的输入压摆(input slew)和Q与QN的输出电容。


即使输出和内部状态没有转换,也可以消耗开关功率。一个常见的例子是在触发器的时钟引脚上切换(toggle)的时钟。触发器在每次时钟切换时都会消耗功率,通常是由触发器单元内部反相器的开关所带来的。即使触发器输出未切换,也会消耗由于时钟引脚切换引起的功率。因此,对于时序逻辑单元,输入引脚功率(input pin power)是指单元内部的功耗,即输出不切换时的功耗。以下例子中描述了输入引脚功率:

上述例子展示了CLK引脚切换时的功率说明,它表示即使输出未切换,时钟切换也会导致功耗。
时钟引脚的功率是否被重复计算了?
注意,触发器还包含由于CLK-> Q转换引起的功耗。因此重要的是,CLK-> Q功率描述表格中的值是不包括与CLK内部功率有关的影响的,CLK内部功率与输出Q不切换时的状况相对应。
以上内容涉及到了应用工具对功率表使用的一致性,能够确保在功率计算期间与时钟输入有关的内部功率不会被重复计算。
漏电功率
大多数标准单元的设计都仅在输出或状态发生变化时才消耗功率。单元通了电但没有任何行为时,所有功耗都归因于泄漏电流(leakage current)。泄漏可能是由于MOS器件的亚阈值电流引起的,也可能是由于通过栅极氧化物的隧穿电流引起的。在以前的CMOS工艺技术中,漏电功率可以忽略不计,并且在设计过程中并不是主要考虑因素。但是,随着技术的发展,漏电功率变得越来越大,与有功功率相比,漏电功率已经无法忽略不计了。
如上所述,漏电功率主要有两个来源:MOS器件中的亚阈值电流和栅氧化物隧穿。通过使用高阈值电压单元,可以降低亚阈值电流;然而,由于高阈值电压单元的速度较低而存在一个折中(trade-off):高阈值电压单元的漏电较小,但速度较慢。同样,低阈值电压单元的漏电较大,但速度较高。无论是使用高阈值电压还是低阈值电压的单元,栅极氧化物隧穿带来的影响都差不多。因此,控制漏电功率的可能方法是使用高阈值电压的单元。类似于在高阈值电压和标准阈值电压单元之间进行选择,设计中使用的单元强度(strength)也是一种漏电和速度之间的折中。强度较高的单元具有较高的漏电功率,但速度较高。与功率管理有关的折中将在10.6节中详细介绍。
MOS器件的亚阈值泄漏电流与温度具有很强的非线性特性,在大多数工艺技术中,随着器件温度从25°C升高到125°C,亚阈值泄漏电流可能会增加10倍至20倍。栅极氧化物隧穿带来的影响基本不随温度或器件阈值电压而改变,在100nm及以上工艺技术中可以忽略的栅极氧化物隧穿已成为65nm或更精细技术在较低温度下漏电的主要原因。例如,对于65nm或更精细的工艺技术,栅极氧化物隧穿漏电量可能等于室温下的亚阈值漏电量。而在高温下,亚阈值漏电仍然是导致漏电功率的主要因素。
库中的每个单元都被指定了漏电功率。例如,反相器单元的漏电功率可能描述如下:
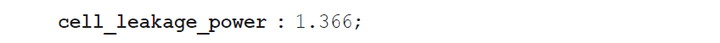
这是单元中耗散的漏电功率,漏电功率单位在库的头文件中指定,通常以纳瓦为单位。通常,漏电功率还取决于单元的状态,可以使用when条件指定状态相关值。
例如,一个反相器单元可以具有如下描述:

其中I是反相器单元的输入引脚。需要注意的是,上例中的描述还包括了一个默认值(在when条件之外),该默认值通常是在when条件内指定值的平均值。
单元库中的其它属性
除时序信息外,库中的单元描述还指定了单元面积、功能和时序弧的SDF条件。这些将在本节中进行简要描述,有关更多详细信息,请参阅Liberty手册。
单元面积
面积描述中指定了一个单元或一组单元的面积:
area:2.35
上面指定了单元的面积为2.35个面积单位,这可以代表单元实际使用的硅面积,也可以是面积的相对测量值。
单元功能
功能描述中指定了一个引脚或一组引脚的功能:

上面指定了一个两输入与门单元输出引脚Z的逻辑功能。
SDF条件
SDF条件属性支持标准延迟格式SDF(Standard Delay Format)文件的生成以及在反标(backannotation)期间的条件匹配。就像when条件指定用于时序分析的状态相关模型的条件一样,SDF标注(annotation)时状态相关时序的相应条件由sdf_cond来表示。以下是一个示例:

特征和工作条件
单元库中还会指定创建该库的特征(characterization)和工作条件。例如,库文件的头部可能包含以下内容:

工作条件(nom_process、nom_temperature和nom_voltage)指定了对库进行表征的工艺、电压和温度, 也指定了使用该库中单元的条件。如果特征和工作条件不同,则需要对延迟计算过程中获得的时序值进行降额(derate)处理, 这可以通过使用库中指定的降额系数(k-系数)来实现。
在除用于表征之外的条件下使用降额获得时序值会导致时序计算不准确。只有当无法在预期的条件下表征库时,才能使用降额过程。
什么是工艺变量?
与作为物理量的温度和电压不同,工艺是不可量化的变量。就数字特征和验证而言,它可能是缓慢(slow)、典型(typical)或快速(fast)的工艺之一。因此,工艺值为1.0(或任何其它值)是什么意思?答案在下面。
库的表征是一个耗时的过程,针对各种工艺角(process corner)对库进行表征可能需要数周的时间,工艺变量的设置使得以特定工艺角为特征的库可以用于不同工艺角的时序计算。工艺的k-系数可用于完成从特征库工艺到目标工艺的延迟降额。如上所述,降额系数的使用在时序计算期间引入了不准确性,跨工艺条件进行降额尤其不准确,因此很少采用。总而言之,指定不同工艺变量值(例如1.0或任何其它值)的唯一功能就是在少数情况下允许跨工艺条件进行降额处理。
使用K-系数降额
如上所述,当工作条件不同于表征条件时,降额系数(或称k-系数)可用于计算延迟,k-系数是近似系数。库中k-系数的示例如下所示:


当延迟计算过程中工作条件的工艺、电压或温度与库中的标称条件不同时,可使用这些系数来进行计算。注意,k_volt系数为负,这意味着延迟随着电压的增加而减小,而k_temp因子为正,这意味着延迟通常随温度的升高而增加(除非单元具有2.10节中所描述的温度反转现象)。k-系数的用法如下:
● 降额后延迟 = 库中原始延迟 * (1 + k_process * Process + k_volt *
Volt + k_temp *
Temp)
例如,假设使用slow工艺模型在1.08V和125°C下表征了一个库。如果要获得1.14V和100°C的延迟,则slow工艺模型的单元上升延迟可以通过以下计算获得:
● 降额后延迟 = 库中原始延迟 * (1 + k_volt_cell_rise * 0.06 - k_temp_cell_rise * 25)
假设使用上例中的k-系数代入以上计算公式,可得:
● 降额后延迟 = 库中原始延迟 * (1 - 0.42 * 0.06 - 0.0012 * 25) = 库中原始延迟 * 0.9448
可见,在降额条件下的延迟约为原始延迟的94.48%。
库中各单位
单元描述中数值的单位都是在库中指定的,可使用Liberty命令集在库文件中声明单位。电压、时间、电容和电阻的单位声明如下例所示:
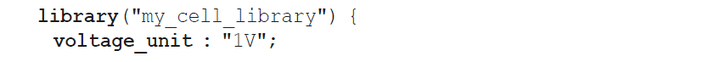

在本书中,我们假设库中时间单位为纳秒(ns),电压单位为伏特(V),每转换一次的内部功率单位为皮焦耳(pJ),漏电功率单位为纳瓦(nW),电容单位为皮法(pF),电阻单位为Kohms,面积单位为平方微米,但明确有特殊说明的情况除外。
互联寄生
本章节介绍用于处理和表示互连寄生(interconnect parasitics)现象的各种技术,以验证设计的时序。
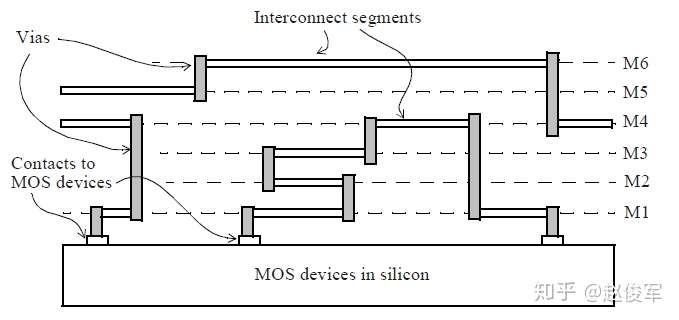
● 在数字设计中,将标准单元或块(block)的引脚连接在一起的线(wire)称为网络(net)。网络通常只有一个驱动,但它可以驱动多个扇出单元或块。物理实现(physical implementation)后,网络可以在芯片的多个金属层上移动,各种金属层可以具有不同的电阻和电容值。对于等效的电气表示,通常将网络划分为多个段(segment),每个段均由等效的寄生参数表示。我们也将段称为互连走线(interconnect trace),也就是说,它是特定金属层上网络的一部分。
互连RLC
互连电阻(R)来自设计实现中各种金属层和过孔(vias)中的互连走线。图4-1是一个穿越各种金属层和过孔的网络示例。因此,可以将互连电阻视为单元的输出引脚与扇出单元的输入引脚之间的电阻。
互连电容(C)也来自金属走线,包括接地电容以及相邻信号路径之间的电容。
互连电感(L)是由于电流环路而产生的,通常,电感效应在芯片内可以忽略不计,仅在封装和板级分析中考虑。在芯片级设计中,电流环路又窄又短,这意味着电流返回路径是通过电源或地信号而紧密相连的。在大多数情况下,时序分析不考虑片上电感,片上电感分析的任何进一步描述都超出了本书的范围。接下来仅分析互连电阻和互连电容的表示方法。
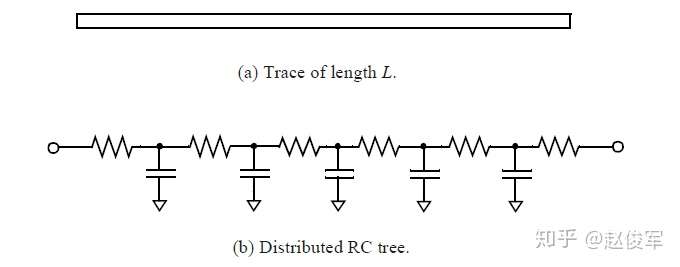
理想情况下,互连走线一部分的电阻和电容(RC)用分布式(distributed)RC树表示,如图4-2所示。 在此图中,RC树的总电阻和总电容Rt和Ct分别等于Rp * L和Cp * L,其中Rp和Cp分别是单位长度走线的互连电阻和电容值,L是走线长度。Rp和Cp值通常是从各种配置下提取的寄生参数中获得的,并由ASIC代工厂提供。
RC互连可以通过各种简化模型来表示,这些将在下面的小节中进行介绍。
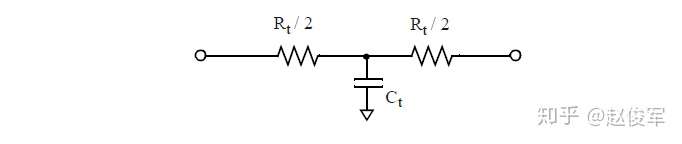
T模型
使用T模型表示时,总电容Ct被建模为在电阻树中间的连接。总电阻Rt被分为两部分(每部分为Rt / 2),Ct连接在电阻树的中点,如图4-3所示。
π模型
在如图4-4所示的π模型中,总电容Ct被分为两部分(每部分为Ct / 2),并连接在电阻的两侧。

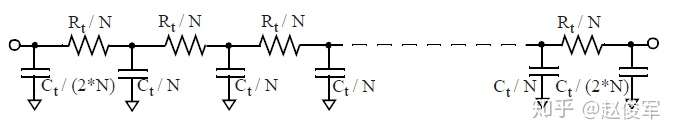
通过将Rt和Ct分成多个部分,可以获得分布式RC树的更准确表示。若分为N个部分,则每个中间部分的电阻和电容值分别为Rt / N和Ct /N,而两端部分需要根据T模型或π模型的概念来进行建模。图4-5中两端部分使用了T模型进行建模,而图4-6中两端部分使用了π模型进行建模。
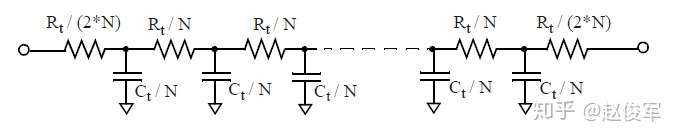
线负载模型
在进行布局规划(floorplanning)或布局(layout)之前,可以使用线负载模型(wireload models)来估计由互连线带来的电容、电阻以及面积开销。线负载模型可用于根据扇出数量来估计网络的长度,线负载模型取决于块(block)的面积,具有不同面积的设计可以选择不同的线负载模型。线负载模型还可以将网络的估计长度映射(map)为电阻、电容以及由于布线而产生的相应面积开销。
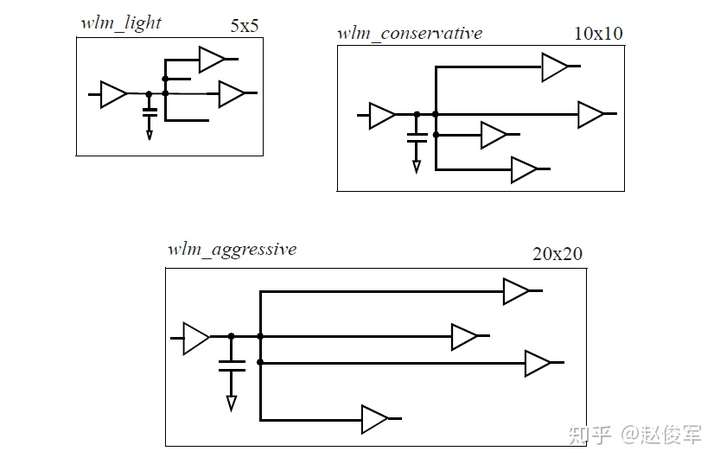
块内的平均走线长度与块的面积密切相关:随着块面积的增加,平均走线长度也会增加。图4-7显示,对于不同的面积(芯片或块),通常将使用不同的线负载模型来确定寄生效应。因此,下图中面积小的块的电容比较小。
以下是一个线负载模型的例子:

resistance是互连线单位长度的电阻值,capacitance是互连线单位长度的电容值,area是互连线单位长度的面积开销,slope是用于扇出-长度(fanout_length)表中未指定的数据点的外推斜率。
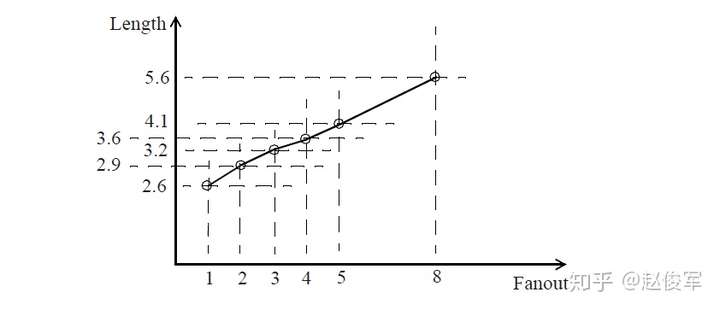
线负载模型描述了互连线长度与扇出之间的函数关系,上面的示例如图4-8所示。对于表中未明确列出的任何扇出值,可使用具有指定斜率的线性外推法计算得到互连线长度。例如,扇出为8时可进行如下计算:
● 互连线长度 = 4.1 + (8 - 5) * 0.5 = 5.6
● 电容值 = 5.6 * 1.1 = 6.16
● 电阻值 = 5.6 * 5 =28.0
● 面积开销 = 5.6 * 0.05 = 0.28
上述计算结果中长度、电容、电阻、面积的单位都会在库(library)中指定。
互连树
一旦确定了预布局(pre-layout)后互连线的电阻电容估计值(即Rwire和Cwire),下一个问题便是互连结构。互连RC结构相对于驱动单元该如何分布呢? 这一点很重要,因为从驱动引脚(driver pin)到负载引脚(load pin)的互连延迟取决于互连的结构。通常,互连延迟取决于沿路径的互连电阻和电容大小。因此,延迟值可能会有所不同,具体取决于给这个网络(net)假定的拓扑结构。
对于预布局估计,可以使用以下三种不同形式来表示互连RC树(见图4-9)。请注意,每个互连线的总长度(以及电阻和电容估计值)在这三种情况下是相同的。
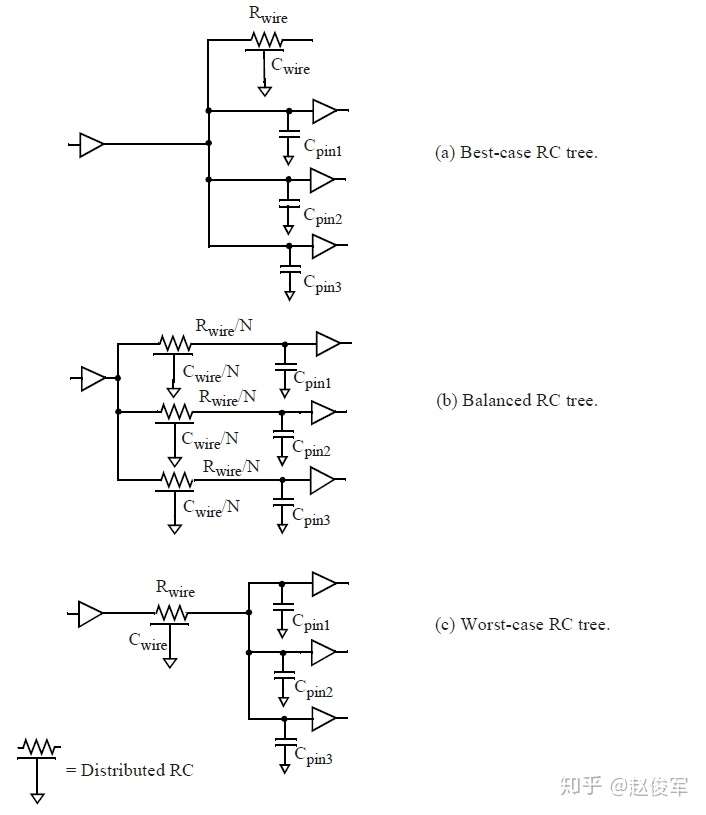
● Best-case tree
在最佳情况树中,假定负载引脚在物理上与驱动引脚相邻。因此,到负载引脚的路径中都没有互连电阻,来自其它扇出引脚的所有互连线电容和引脚电容仍然作为驱动引脚上的负载。
● Balanced tree
在这种情况下,假定每个负载引脚都在互连线的一部分上,并且每条到达负载引脚的路径上的总电阻和电容都相等。
● Worst-case tree
在最差情况树中,假定所有负载引脚都集中在互连线的另一端。因此,每条到负载引脚的路径上都会有全部的互连线电阻和电容。
指定线负载模型
使用以下命令指定线负载模型:
set_wire_load_model "wlm_cons" -library "lib_stdcell"
以上命令表示使用单元库lib_stdcell中的线负载模型wlm_cons。
当一个网络跨越了设计层次(hierarchical)的边界时,可以基于线负载模式(wireload mode)将不同的线负载模型应用于每个层次中网络的不同部分。这些线负载模式是:
● top
● enclosed
● segmented
可以使用set_wire_load_mode来指定线负载模式:
set_wire_load_mode enclosed
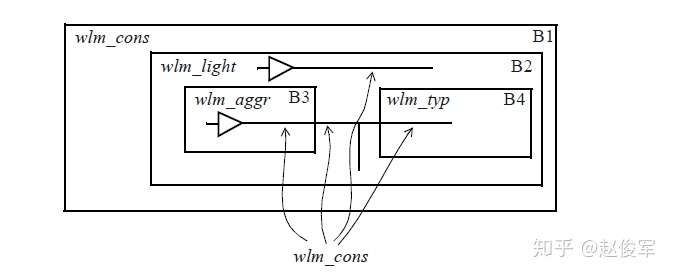
在top线负载模式下,层次结构中的所有网络都将继承顶层(top)的线负载模型,即忽略下级层级中指定的任何线负载模型。因此,顶层的线负载模型具有优先权。对于图4-10所示的例子,块B1中指定的wlm_cons线负载模型优先于块B2、B3和B4中指定的所有其它线负载模型。
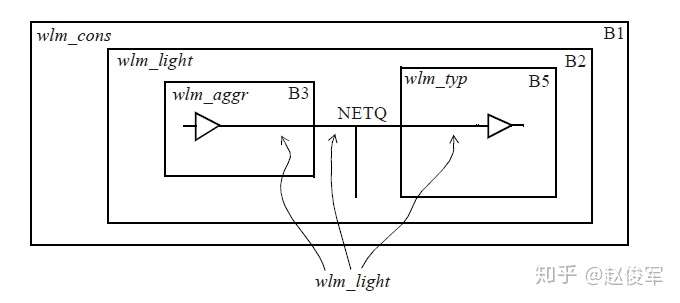
在enclosed线负载模式下,将完全包含网络的那个块中使用的线负载模型用于整个网络。对于图4-11中所示的例子,网络NETQ被完全包含在块B2中,因此将块B2的线负载模型wlm_light用于该网络。同理,完全包含在块B3中的网络使用wlm_aggr线负载模型,而完全包含在块B5中的网络使用wlm_typ线负载模型。
在segmented线负载模式下,网络的每段(segment)都从包含该段的块中获取其线负载模型,网络的每个部分都在该层次内使用适当的线负载模型。图4-12举例说明了一个网络NETQ,它的三段分别在三个块中。B3块中此网络的扇出互连使用wlm_aggr线负载模型,B4块中使用wlm_typ线负载模型,B2块中使用wlm_light线负载模型。
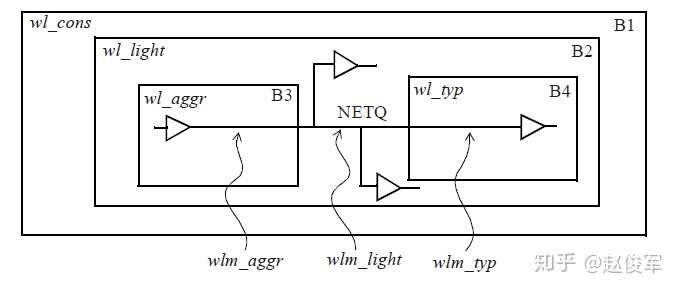
通常,是根据模块的芯片面积来选择线负载模型的。但是,可以根据用户的判断修改或更改它们。例如,可以为面积在0到400之间的块选择线负载模型wlm_aggr,为面积在400到1000之间的块选择线负载模型wlm_typ,为面积大于1000的块选择线负载模型wlm_cons。 线负载模型通常在单元库中定义,但是用户也可以自定义线负载模型。可以在单元库中将默认的线负载模型指定为:
default_wire_load : "wlm_light" ;
在单元库中定义了一个线负载模型选择组,该组根据面积选择线负载模型,以下是一个示例:

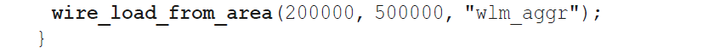
单元库可以包含许多这样的选择组。通过使用set_wire_load_selection_group,可以选择特定的一个组供STA使用。
set_wire_load_selection_group WireAreaSelGrp
本节介绍了在物理实现之前(即在预布局阶段)估算寄生参数的建模过程。下一节将介绍从布局中提取得到的寄生参数的表示方法。
提取所得寄生参数的表示方法
从布局(layout)中提取的寄生参数可以用三种格式描述:
● 详尽的寄生参数格式 :Detailed Standard Parasitic Format(DSPF)
● 精简的寄生参数格式 :Reduced Standard Parasitic Format(RSPF)
● 标准的寄生参数格式 :Standard Parasitic Extraction Format(SPEF)
一些工具还提供了专用的寄生参数二进制表示格式,例如SBPF;这有助于减小文件存储空间,并加快了工具读取寄生参数的速度。下面分别对以上三种格式进行简要说明。
详尽的寄生参数格式
使用DSPF格式时,详尽的寄生参数以SPICE格式表示。SPICE中的Comment语句用于表明单元类型、单元引脚及其电容。电阻和电容值采用标准SPICE语法,并且单元实例也包含在此表示格式中。这种格式的优势在于,DSPF文件可以用作SPICE仿真器本身的输入。但是,缺点是DSPF语法过于详细和冗长,导致模块的总文件大小非常大。因此,这种格式在实际中仅用于相对较小的一组网络。
以下是DSPF文件的示例,描述了从主输入IN到缓冲器BUF的输入引脚A以及从BUF的输出引脚OUT到主输出引脚OUT的一个网络互连。

DSPF中的非标准SPICE语句是以 * |开头,并具有以下格式:


精简的寄生参数格式
使用RSPF格式时,寄生参数以精简的形式表示。精简格式包括电压源和受控电流源。RSPF格式也是SPICE文件,也可以将其读取到类似SPICE的仿真器中。RSPF格式要求简化详细的寄生参数并将其映射为精简格式,因此这是RSPF格式的一个缺点,因为寄生提取过程的重点通常是提取的精度,而不是压缩成RSPF之类的精简格式。RSPF格式的另一个限制是不能以这种格式表示双向信号流。
以下是RSPF文件的示例,原始设计和等效表示如图4-13所示。

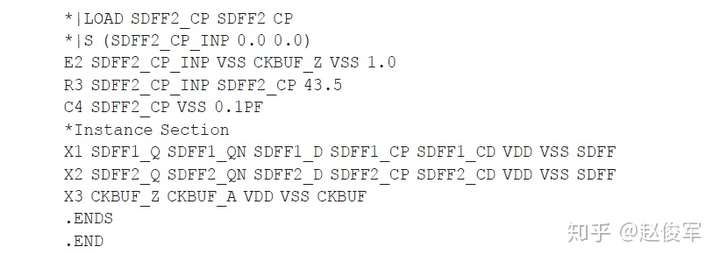
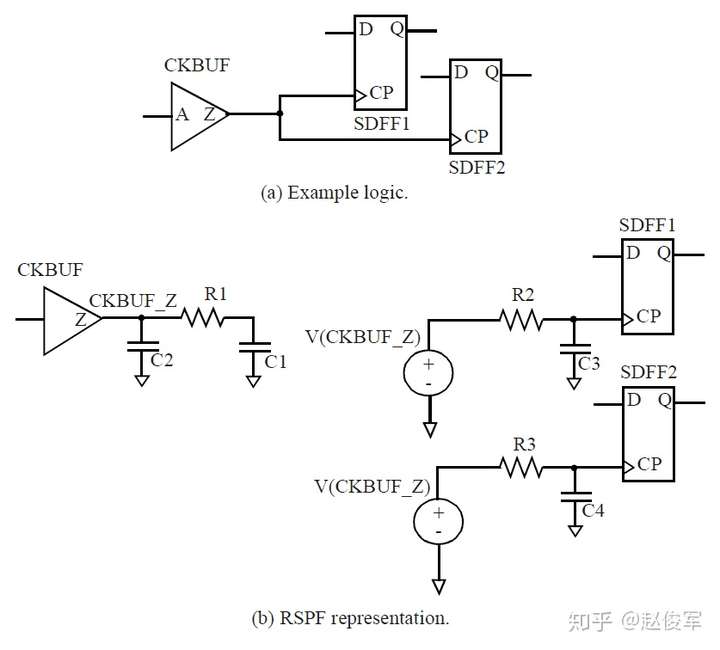
这个文件具有以下特点:
● 在每个扇出单元的输入引脚上都使用0.1pF的电容(C3和C4)和电阻(R2和R3)对引脚到引脚(pin-to-pin)的互连延迟进行建模,电阻值的选取原则是使RC延迟对应于引脚到引脚的互连延迟。驱动单元输出引脚上的π型负载模拟了通过该单元的延迟。
● 输入端的RC元件由理想电压源(E1和E2)驱动,该电压源等于驱动单元输出端的电压。
标准的寄生参数格式
SPEF是一种紧凑格式,可以表示详细的寄生参数。下面是一个具有两个扇出的网络的示例:


寄生电阻和电容的单位在SPEF文件的开头中指定,附录C中提供了SPEF文件的更详细说明。由于SPEF的紧凑性和表示的完整性,它是设计中寄生参数表示方法的首选格式。
耦合电容的表示方法
上一节说明了将一个网络的电容表示为接地(grounded)电容的情况。由于纳米技术中的大多数电容是侧壁(sidewall)电容,因此这些电容的恰当表示形式应该是信号到信号(signal-to-signal)的耦合电容(Coupling Capacitance)。
DSPF中耦合电容的表示是对原始DSPF标准的附加(add-on),因此不是唯一的。耦合电容会在两组耦合网络之间被复制,这意味着由于两组网络中有重复的耦合电容,因此DSPF无法直接被读入SPICE。一些输出DSPF的工具通过在两个耦合网络中各包含一半的耦合电容解决了这一问题。
RSPF是精简的格式,因此不适合表示耦合电容。
SPEF标准以统一和明确的方式处理耦合电容,因此是考虑串扰(crosstalk)时序时优先选择的提取格式。此外,就文件大小而言,SPEF是紧凑的表示格式,适合用于表示带耦合或不带耦合的寄生参数。
如附录C中所描述,管理文件大小的机制之一是在文件的开头列出名称目录(name directory)。现在,许多提取工具在SPEF文件的开头指定了网络名目录(将网络名表示为索引),从而避免了重复网络名的冗长性,这样可以大大减小文件大小。附录C中列举了一个SPEF的名称目录示例。
分层方法
大型复杂的设计通常在物理设计过程中需要使用分层方法(hierarchical methodology)来进行寄生参数提取和时序验证。在这种情况下,模块的寄生参数会在模块级别提取,然后可以在更高的层次上使用。
可以将从一个模块的布局中提取得到的寄生参数用于尚未完成布局的另一个模块的时序验证。在这种情况下,通常将已布局完的模块的寄生参数与预布局模块的基于线负载模型的估计寄生参数结合使用。
在使用分层方法的流程中,顶层(top)模块的布局最先完成,但其中的模块仍为黑匣子(预布局),基于线负载模型估计所得的寄生参数可以结合从布局完成的顶层中提取得到的寄生参数用于较低层次的模块。 一旦各模块的布局也完成了,就可以将从顶部和模块的布局中提取得到的寄生参数结合在一起。
布局中的重复模块
如果将一个设计模块在布局中复制多次,则可以将从一个实例(instantiation)中提取的寄生参数用于所有实例,这就要求该模块的布局在各方面对于每个实例都是相同的。例如,从布局内的布线网络看,布局环境(environment)应该没有差异,这意味着模块内网络不与模块外部的任何网络电容耦合。可以做到这一点的一种方法是:确保没有在模块内布线任何顶层的网络,并且对在块的边界附近布线的网络有足够的保护或间距。
减少关键网络的寄生参数
本节简要概述了管理寄生参数对关键(critical)网络影响的常用技术。
降低互连电阻
对于关键网络,重要的是要保持较低的压摆率(slew)或快速的过渡时间(transition),这意味着应降低互连电阻。通常,有两种方法可以实现较低的电阻:
● 宽走线(Wide trace):具有比最小宽度更加宽的走线可以降低互连电阻,而且不会引起寄生电容的显著增加。因此,可以减少总的RC互连延迟和过渡时间。
● 在较高(较厚)金属中布线:较高的金属层通常具有低电阻率,可用于给关键信号布线。较低的互连电阻可减少互连延迟以及目标引脚(destination pin)上的过渡时间。
增加走线间距
增加走线之间的间距可以减少网络的耦合电容和总电容。大的耦合电容会增加串扰,避免串扰是在长距离相邻走线中布线的网络的重要考虑因素。
相关网络的寄生参数
在许多情况下,一组网络必须在时序上匹配。比如高速DDR接口的一个字节通道内的数据信号,因为需要保证一个字节通道内的所有信号都具有相同的寄生参数,所以这些信号都应在同一金属层中布线。例如,虽然金属层M2和M3具有相同的平均值和相同的统计变化,但是这些变化是独立的,从而这两个金属层中的寄生参数变化是无关的。因此,如果对于关键信号的时序匹配很重要,则在每个金属层中的布线必须相同。
延迟计算
本章节介绍了用于布局前后时序验证的基于单元(cell-based)的设计的延迟计算(delay calculation)。
● 前几章重点介绍了对互连线和单元库的建模,单元和互连线建模技术可用于获得设计的时序信息。
概述
延迟计算基础
典型的设计中包括各种组合逻辑单元和时序逻辑单元,我们使用如图5-1中所示的逻辑设计来描述延迟计算的概念:
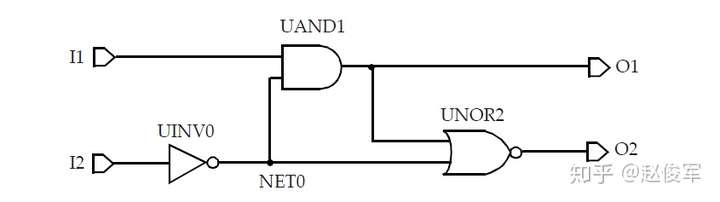
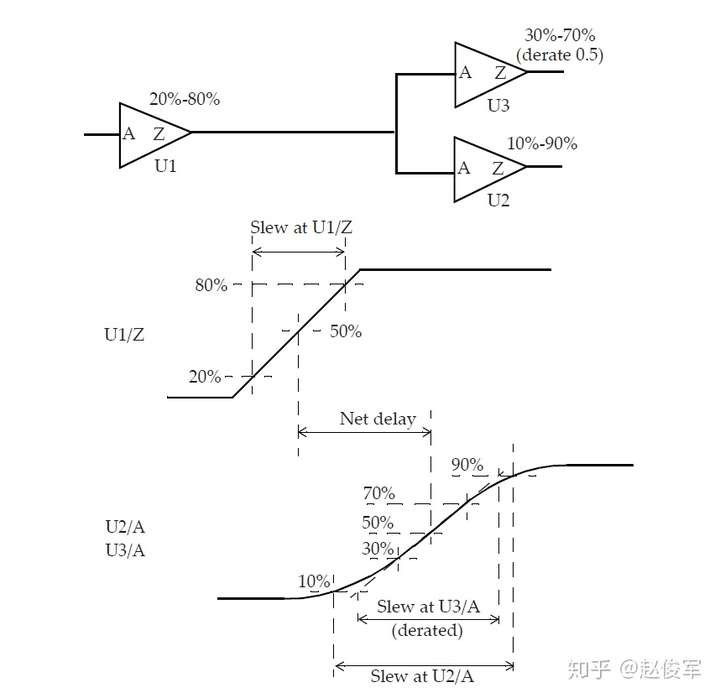
库中为每个单元的每个输入引脚都指定了电容值,因此,设计中的每个网络都具有容性负载,该负载是该网络每个扇出的引脚负载电容再加上互连线的寄生电容之和。为了简单起见,本节中暂不考虑互连线的影响,这些内容将在后面章节中进行介绍。不考虑互连寄生的影响,图5-1中的内部网络NET0的电容将由UAND1和UNOR2单元的输入引脚电容组成;输出O1具有UNOR2单元的输入引脚电容再加上逻辑模块输出端口的任何电容性负载;输入I1和I2具有UAND1和UINV0单元的输入引脚电容。通过这种抽象,图5-1中的逻辑设计可以用图5-2所示的等效表示来描述:
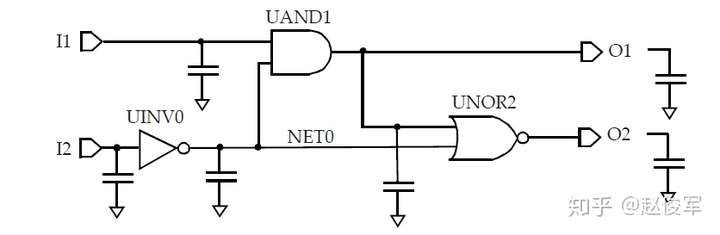
如第3章所述,单元库中包含了用于各种时序弧的NLDM时序模型,非线性模型以输入过渡时间和输出负载电容的形式表示为二维表格。逻辑单元的输出过渡时间也以输入过渡时间和总输出负载电容的形式表示为二维表格。因此,如果在逻辑块的输入引脚处(I1和I2)指定了输入过渡时间(或称压摆),则可以从库中获得UINV0单元和UAND1单元(对于输入I1)的时序弧的输出过渡时间和延迟。对扇出单元使用如上相同的方法,则可以获得通过UAND1单元的另一条时序弧(从NET0到O1)以及通过UNOR2单元的过渡时间和延迟。对于多输入单元(例如UAND1),不同的输入引脚会导致不同的输出过渡时间值,对扇出网络过渡时间的选择取决于压摆合并(slew merge)选项,这将在5.4节中进行介绍。使用上述方法,可以基于输入引脚上的过渡时间和输出引脚上的电容来获得通过任何逻辑单元的延迟。
带互连线的延迟计算
布局前时序
如第4章所述,在布局前(pre-layout)时序验证期间,使用线负载模型估算了互连寄生参数。在许多情况下,线负载模型中电阻的影响被设置为了0。在这种情况下,线负载是纯电容性的,因此上一部分中描述的延迟计算方法适用于获得设计中所有时序弧的延迟。
如果线负载模型考虑了互连电阻的影响,则将NLDM模型与总网络电容一起使用,以计算通过单元的延迟。由于互连线是电阻性的,因此从驱动单元的输出到扇出单元的输入引脚会有额外的延迟。互连线的延迟计算过程将在5.3节中进行介绍。
布局后时序
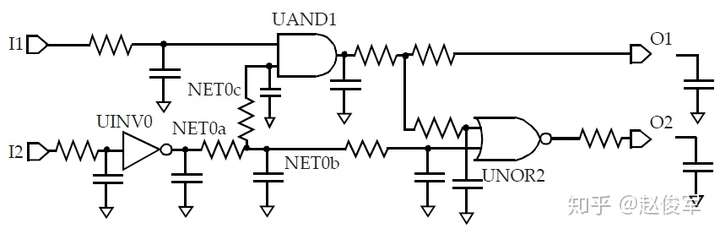
金属走线的寄生参数将被映射为驱动单元和目标单元之间的RC网络。以图5-1中示例为例,网络的互连电阻如图5-3所示。内部网络(例如图5-1中的NET0)映射到了多个子节点,如图5-3所示。因此,反相器单元UINV0的输出负载由RC结构组成。由于NLDM表格仅针对输入过渡时间和输出负载电容而言,因此输出引脚上的电阻性负载意味着NLDM表格不能直接应用。下一节将介绍如何将NLDM表格模型与互连电阻一起结合使用。
使用有效电容计算单元延迟
如上所述,当单元输出端的负载包含互连电阻时,NLDM模型不可直接使用。因此,采用“有效”电容法来处理电阻的影响。
有效电容法试图找到一个可以用作等效负载的电容,以使原始设计与具有等效电容负载的设计在单元输出的时序方面表现一致。这个等效电容被称为有效电容(effective capacitance)。
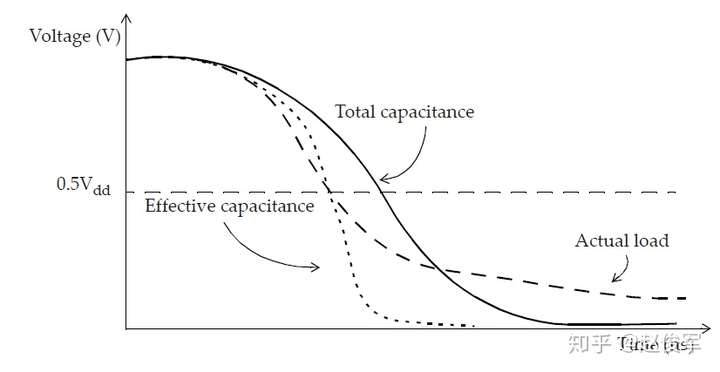
图5-4(a)为在扇出处具有RC互连的单元,该RC互连可由等效的π模型表示,如图5-4(b)所示。有效电容的概念是为了获得等效的输出电容Ceff(如图5-4(c)所示),此时通过单元的延迟与具有RC互连负载的原始设计相同。通常,具有RC互连负载的单元输出波形与具有单个电容性负载的单元输出波形非常不同。
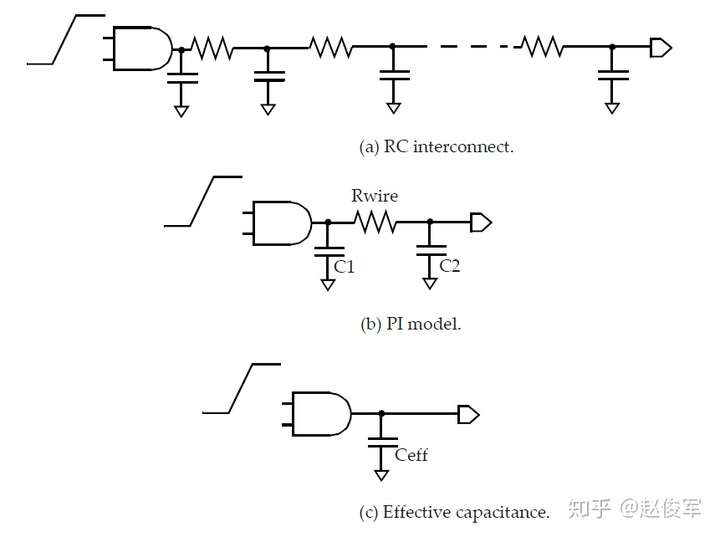
图5-5中展示了具有总电容、有效电容的单元输出端的代表性波形以及具有实际RC互连的波形。选择准确的有效电容Ceff应该可以使得图5-4(c)中单元输出处的延迟(在过渡波形的中点测得)与图5-4(a)中的延迟相同,如图5-5所示。
使用π模型等效表示RC互连时,有效电容可以表示为:
● Ceff = C1 + k * C2 , 0 <= k <= 1
其中C1是近端(near-end)电容,C2是远端(far-end)电容,如图5-4(b)所示。k的值在0到1之间。在互连电阻可忽略的情况下,有效电容几乎等于总电容。通过在图5-4(b)中将R设置为0,可以直接解释这一点。同样,如果互连电阻相对较大,则有效电容几乎等于近端电容C1,这可以通过将R增加到无限大(本质上是开路)的极限情况来解释。
有效电容是以下各项的函数:
● 驱动单元
● 负载的特性,尤其是驱动单元负载的输入阻抗。
对于给定的互连线,输出驱动较弱的单元将比驱动较强的单元具有更大的有效电容。因此有效电容的值将介于最小值C1(对于较大的互连电阻或者较强的驱动单元)与最大值C1+C2(对于小到可忽略的互连电阻或较弱的驱动单元)之间。注意,目标引脚的转换要晚于驱动单元的输出。近端电容充电速度比远端电容快的现象也被称为互连线的电阻屏蔽效应(resistive shielding effect),因为驱动单元只能看到一部分远端电容。
与通过库中的NLDM模型直接查找来计算延迟不同,延迟计算工具通过迭代过程获得有效电容。就算法而言,第一步是获取单元输出端看到的实际RC负载的驱动点阻抗,可以使用二阶AWE或Arnoldi算法等方法计算实际RC负载的驱动点阻抗。计算有效电容的下一步是使两种情况下直到过渡波形中点为止传输的电荷量相等:使用实际RC负载时(基于驱动点阻抗)在单元输出处传输的电荷与使用有效电容作为负载时的电荷传输量相匹配,请注意,电荷传输匹配仅到过渡波形的中点为止。该过程从有效电容的估算值开始,然后迭代更新估算值。在大多数实际情况下,有效电容值会在少量次数的迭代中收敛。
因此,有效电容近似值是计算通过单元的延迟的优秀模型。但是,使用有效电容法获得的输出压摆(slew)与单元输出处的实际波形并不一致。有效电容近似值不能代表单元输出处的波形,尤其是波形的后半部分。请注意,在典型情况下,需要关注的波形并不是在单元输出处,而是在互连线的终点处,也即扇出单元的输入引脚处。
有多种方法可以计算互连线终点处的延迟和波形。在许多实现(implementation)方法中,有效电容的计算过程还会计算驱动单元的等效戴维宁(Thevenin)电压源。戴维宁电压源由具有串联电阻Rd的电压源组成,如图5-6所示。串联电阻Rd对应于单元输出级的下拉电阻(或上拉电阻)。
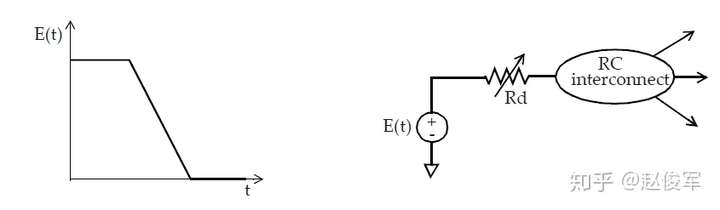
本节介绍了使用有效电容替代RC互连来计算通过驱动单元的延迟。有效电容的计算还提供了等效的戴维宁电压源模型,然后将其用于获取通过RC互连的时序。接下来将具体介绍获取通过RC互连时序信息的过程。
互连线延迟
如第4章所述,网络的互连寄生通常由RC电路表示,RC互连电路可以是布局前或布局后的。虽然布局后的互连寄生可以包括与相邻网络的耦合,但是基本延迟计算中将所有电容(包括耦合电容)都视为接地电容。一个网络及其驱动单元和扇出单元的寄生参数如图5-7所示:

使用有效电容法,可以分别获得通过驱动单元和通过互连线的延迟。使用有效电容法可获得通过驱动单元的延迟,并在单元的输出端提供等效的戴维宁电压源,然后使用戴维宁电压源分别计算通过互连线的延迟。互连线部分具有一个输入和与目标引脚一样多的输出。在互连线输入端使用等效戴维宁电压源,计算到每个目标引脚的延迟,如图5-6所示。
在布局前进行分析时,RC互连结构由RC树类型决定,而RC互连结构又决定了互连线延迟。4.2节中已详细介绍了三种类型的RC互连树表示形式,所选的RC树类型通常在库中定义。通常,最坏情况(worst-case)的慢速库会选择最坏情况的RC树,因为该类型的树提供了最大的互连线延迟。类似地,最佳情况(best-case)的RC树结构中不包括从源引脚到目标引脚的任何电阻,通常在最佳情况的快速工艺角时被选择。因此,最佳情况RC树的互连延迟等于零。典型(typical)情况RC树和最坏情况RC树的互连延迟的处理方式与布局后RC互连一样。
Elmore延迟模型
Elmore延迟模型(如图5-8所示)适用于RC树。什么是RC树? RC树应满足以下三个条件:
● 有单一的输入(源)节点
● 没有任何电阻回路
● 所有电容都在节点和地之间
Elmore延迟可以看作是找到每段的延迟,即R与下游电容的乘积,然后取各延迟之和。

到各个中间节点的延迟计算如下:
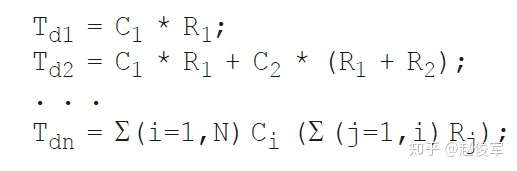
Elmore延迟在数学上考虑的是脉冲响应的第一时刻。 现在,我们将Elmore延迟模型进行如下简化表示:互连线的寄生电阻与电容分别为Rwire和Cwire,互连线远端的引脚电容由负载电容Cload来建模。等效的RC网络可以简化为π模型或T模型,分别如前面章节四中图4-4和图4-3所示。两种模型都具有如下走线延迟(基于Elmore延迟方程):
● Rwire * ( Cwire / 2 + Cload)
这是因为Cload在充电路径中能看到整个互连线的电阻,而Cwire电容在T模型中仅能看到Rwire / 2且Cwire / 2在π模型中能看到Rwire。以上方法也可以扩展到更复杂的互连结构。
下面给出了使用线负载模型和平衡(balanced)RC树(以及最坏情况RC树)计算一个网络的Elmore延迟的示例。
使用平衡RC树模型时,网络的电阻和电容在网络的各个分支之间平均分配(假设扇出为N)。对于具有引脚负载Cpin的分支,使用平衡RC树的延迟为:
● (Rwire / N)* (Cwire / (2N)+ Cpin)
使用最坏情况RC树模型时,网络的每个分支终点都考虑了网络的电阻和整个电容。此时的延迟值如下所示,这里的Cpins是所有扇出的总引脚负载:
● Rwire * (Cwire / 2 + Cpins)
图5-9是一个设计实例:
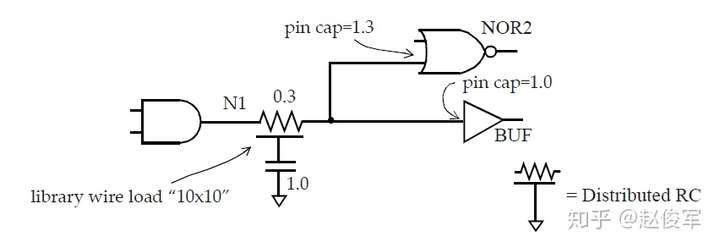
如果我们使用最坏情况RC树模型来计算网络N1的延迟,我们将得到:
● Rwire * (Cwire / 2 + Cpins)= 0.3 * (0.5 + 2.3)=0.84
如果使用平衡RC树模型,则对于网络N1的两个分支,将得到以下延迟:
● 到NOR2单元的分支 : (0.3 / 2)* (0.5 / 2 + 1.3)= 0.2325
● 到BUF单元的分支: (0.3 / 2)*(0.5 / 2 + 1.0)= 0.1875
高阶互连线延迟估计
如上所述,Elmore延迟考虑的是脉冲响应的第一时刻,而AWE(渐近波形评估)、Arnoldi或其他方法能够匹配更高阶的响应时刻。通过进行更高阶的估计,可以提高计算互连线延迟的精度。
全部片上延迟计算
到目前为止,本章已经介绍了单元延迟以及单元输出处互连线的延迟计算。因此,给定在单元输入处的过渡时间,可以计算通过单元和单元输出处互连线的延迟。互连线远端(终点)的过渡时间是下一级的输入,整个设计过程中都会重复此过程,这样就计算出了设计中每个时序弧的延迟。
压摆合并
当多个压摆到达一个公共点时(例如在多输入单元的情况下)会发生什么呢?这种公共点称为压摆合并点(slew merge point)。 选择哪个压摆在压摆合并点处继续向下传播呢?考虑图5-10所示的2输入单元:
由于引脚A上的信号改变,引脚Z上的压摆到达较早,但上升缓慢(压摆较小);由于引脚B上的信号改变,引脚Z上的压摆到达较晚,但上升很快(压摆较大)。在压摆合并点(例如引脚Z),应选择哪个压摆进一步传播呢?取决于所执行的时序分析的类型(最大或最小时序路径分析),这些压摆值中的任何一个都可能是正确的。
进行最大时序路径分析时有两种可能性:
● 最差的压摆传播(Worst slew propagation):此模式选择要在合并点传播最坏的压摆,这将是图5-10(a)中的压摆。对于通过引脚A-> Z的时序路径,此选择是准确的,但对于通过引脚B-> Z的任何时序路径都是悲观的。
● 最差的到达时间传播(Worst arrival propagation):此模式选择要在合并点传播最差的到达时间,这对应于图5-10(b)中的压摆。在这种情况下选择的压摆对于通过引脚B-> Z的时序路径是准确的,但对于通过引脚A-> Z的时序路径是乐观的。
同样,进行最小时序路径分析时也有两种可能性:
● 最佳的压摆传播(Best slew propagation):此模式选择要在合并点传播最佳的压摆,这就是图5-10(b)中的压摆。对于通过引脚B-> Z的时序路径,此选择是准确的,但对于通过引脚A> Z的任何时序路径,该选择的压摆值较小。对于经过A-> Z的路径,路径延迟小于实际值,因此对于最小时序路径分析是悲观的。
● 最佳的到达时间传播(Best arrival propagation):此模式选择要在合并点传播最佳的到达时间,这对应于图5 10(a)中的压摆。在这种情况下,选择的压摆对于通过引脚A-> Z的时序路径是准确的,但大于通过引脚B-> Z的时序路径的实际值。对于经过B-> Z的路径,路径延迟大于实际值,因此对于最小时序路径分析是乐观的。
设计人员可以在静态时序分析环境之外执行延迟计算,以生成SDF文件。在这种情况下,延迟计算工具通常使用最差的压摆传播。生成的SDF文件足以用于最大时序路径分析,但对于最小时序路径分析可能是过于乐观的。
大多数静态时序分析工具均使用最差和最佳的压摆传播作为默认设置,因为它会保守地限制分析。但是,在分析特定路径时可以使用精确的压摆传播,精确的压摆传播需要在时序分析工具中启用一个选项。因此,重要的是要了解静态时序分析工具中默认使用哪种压摆传播模式,并清楚其可能过于悲观的情况。
不同压摆阈值
通常,库会指定在单元表征(characterization)期间使用的压摆(过渡时间)阈值。问题是,当具有一组压摆阈值的单元驱动其他具有不同压摆阈值设置的单元时,会发生什么呢? 考虑图5-11中所示的情况,具有20%-80%压摆阈值的单元驱动两个扇出单元,其中一个具有10%-90%的压摆阈值,另一个具有30%-70%的压摆阈值且压摆降额系数为0.5。
U1单元的压摆设置在单元库中定义如下:
slew_lower_threshold_pct_rise: 20.00
slew_upper_threshold_pct_rise:80.00
slew_derate_from_library:1.00
input_threshold_pct_fall:50.00
output_threshold_pct_fall:50.00
input_threshold_pct_rise:50.00
output_threshold_pct_rise:50.00
slew_lower_threshold_pct_fall:20.00
slew_upper_threshold_pct_fall:80.00
U2单元的压摆设置在另一个单元库中定义如下:
slew_lower_threshold_pct_rise:10.00
slew_upper_threshold_pct_rise:90.00
slew_derate_from_library:1.00
slew_lower_threshold_pct_fall:10.00
slew_upper_threshold_pct_fall:90.00
U3单元的压摆设置在另一个单元库中定义如下:
slew_lower_threshold_pct_rise:30.00
slew_upper_threshold_pct_rise:70.00
slew_derate_from_library:0.5
slew_lower_threshold_pct_fall:30.00
slew_upper_threshold_pct_fall:70.00
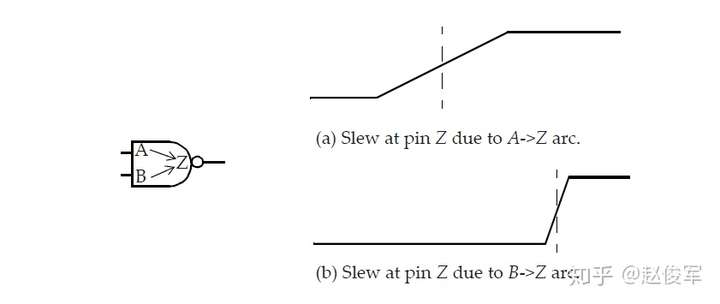
上面仅展示了与U2和U3压摆相关的设置, 输入和输出阈值的延迟相关设置为50%,未在上面显示。延迟计算工具会根据连接到这个网络的单元的压摆阈值来计算过渡时间。图5-11显示了U1 / Z处的压摆如何与此引脚上的切换波形相对应,U1/ Z处的等效戴维宁源可用于获得扇出单元输入端的切换波形。延迟计算工具会根据U2 / A和U3 / A处的波形及其压摆阈值,计算出U2 / A和U3 / A处的压摆。请注意,U2 / A的压摆是基于10%-90%设置的,而U3 / A所用的压摆是基于30%-70%设置,然后根据库中指定的压摆降额(slew derate)系数0.5使用的。 此示例说明了如何根据切换波形和扇出单元的压摆阈值设置来计算扇出单元输入端的压摆。
在可能不考虑互连电阻的预布局(pre-layout)设计阶段时,可以按以下方式计算具有不同阈值的网络处的压摆。例如,10%-90%压摆阈值和20%-80%压摆阈值之间的关系为:
● slew2080 / (0.8 - 0.2) = slew1090 / (0.9 - 0.1)
因此,10%-90%阈值测量点设置时的500ps压摆对应于20%-80%阈值测量点设置时(500ps * 0.6)/ 0.8 = 375ps的压摆。类似地,20%-80%阈值测量点设置时的600ps压摆对应于10%-90%阈值测量点设置时(600ps * 0.8)/ 0.6 = 800ps的压摆。
不同电压域
典型的设计中可能会对芯片的不同部分使用不同的电源。在这种情况下,在不同电压域之间的接口处应使用电平转换单元(level shifting cell)。电平转换单元在一个电压域接受输入,而在另一电压域提供输出。例如,一个标准单元输入可以为1.2V,其输出可以为较低的电压,如0.9V。下图5-12为一个示例:
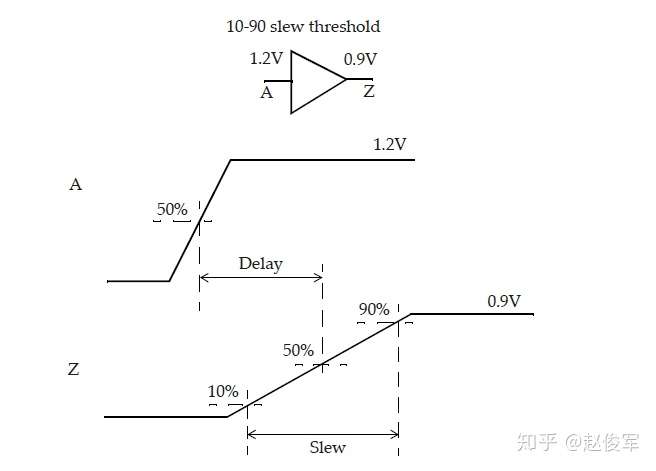
请注意,延迟是根据50%阈值点计算的。对于接口单元的不同引脚,这些点可能处于不同的电压。
路径延迟计算
一旦得到了每个时序弧的全部延迟,则可以将设计中各个单元的时序表示为时序图。通过组合逻辑单元的时序可以表示为从输入到输出的时序弧。类似地,互连线可用从源引脚到每个目的引脚的相应弧表示,表示为单独的时序弧。一旦整个设计由相应的时序弧标定(annotate)了,计算路径延迟就是将沿路径的所有网络和单元的时序弧相加起来即可。
组合逻辑路径延迟
考虑串联的三个反相器,如图5-13所示。在考虑从网络N0到网络N3的路径时,我们同时考虑了上升沿和下降沿路径,现假设网络N0处有上升沿。
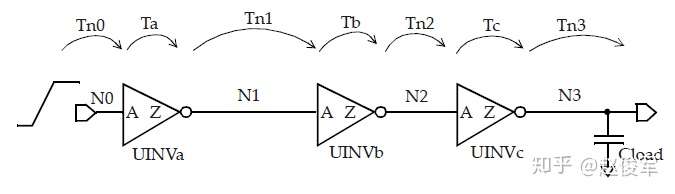
可以指定第一个反相器输入端的过渡时间(或压摆),若没有此类指定的话,就假定过渡时间为0(相当于理想情况)。输入UINVa / A处的过渡时间可通过使用上一节中指定的互连延迟模型来确定,同样,这个互连延迟模型也可用于确定网络N0的延迟Tn0。
根据UINVa输出处的RC负载,可以获得输出处UINVa/Z的有效电容。输入处UINVa/A的过渡时间和输出处UINVa/Z的等效有效负载则可用于获得单元输出下降延迟(output fall delay)。
等效的戴维宁电压源模型在引脚UINVa/Z上通过互连延迟模型可确定引脚UINVb/A上的过渡时间,互连延迟模型还用于确定网络N1上的延迟Tn1。
一旦知道了输入UINVb/A的过渡时间,就可以类似地计算通过UINVb的延迟。UINVb/Z处的RC互连以及引脚UINVc/A的引脚电容可用于确定N2处的有效负载。UINVb/A处的过渡时间可用于确定通过反相器UINVb的输出上升延迟(output rise delay),依此类推。
最后一级的负载由明确的负载说明来指定,如果没有指定,则仅使用网络N3的线负载。
上述分析假设网络N0为上升沿,对于网络N0的下降沿,可以进行类似的分析。因此,在这个简单的示例中,存在两条具有以下延迟的时序路径:
● Tfall = Tn0rise + Tafall + Tn1fall + Tbrise + Tn2rise + Tcfall + Tn3fall
● Trise = Tn0fall + Tarise + Tn1rise + Tbfall + Tn2fall + Tcrise + Tn3rise
通常,由于驱动单元输出处的戴维宁电压源模型不同,通过互连线的上升和下降延迟可能会有所不同。
到触发器的路径
输入到触发器路径
考虑从输入SDT到触发器UFF1的时序路径,如图5-14所示:
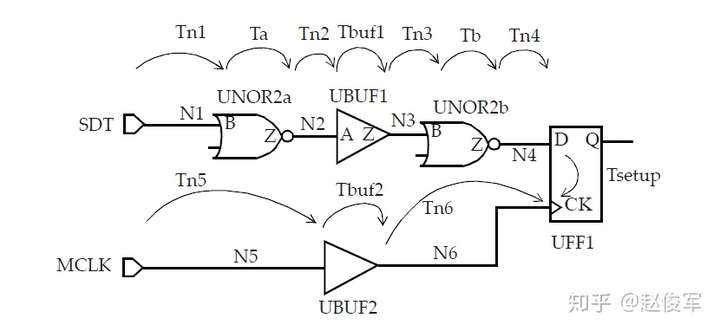
我们需要同时考虑上升沿和下降沿路径。对于输入SDT的上升沿,数据路径延迟为:
● Tn1rise + Tafall + Tn2fall + Tbuf1fall + Tn3fall + Tbrise + Tn4rise
同样,对于输入SDT的下降沿,数据路径延迟为:
● Tn1fall + Tarise + Tn2rise + Tbuf1rise + Tn3rise + Tbfall + Tn4fall
输入MCLK上升沿的捕获(capture)时钟路径延迟为:
● Tn5rise + Tbuf2rise + Tn6rise
触发器到触发器路径
图5-15给出了两个触发器之间的数据路径和相应的时钟路径的示例:
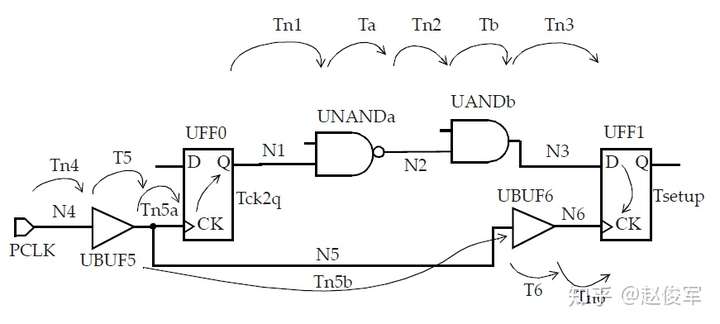
UFF0 / Q上升沿的数据路径延迟为:
● Tck2qrise + Tn1rise + Tafall + Tn2fall + Tbfall + Tn3fall
输入PCLK上升沿的发起(launch)时钟路径延迟为:
● Tn4rise + T5rise + Tn5arise
输入PCLK上升沿的捕获(capture)时钟路径延迟为:
● Tn4rise + T5rise + Tn5brise + T6rise + Tn6rise
需要注意单元的单边性(unateness),因为边沿方向在通过单元时可能会改变(上升沿变下降沿,下降沿变上升沿)。
多路径
在任何两点之间,可以有很多路径。最长的路径是花费时间最多的路径,这也称为最差路径、较晚路径或最大路径。最短的路径是花费时间最少的路径,这也称为最佳路径、较早路径或最小路径。
请参见图5-16中时序弧的逻辑和延迟。两个触发器之间的最长路径是通过单元UBUF1、UNOR2和UNAND3,两个触发器之间的最短路径是通过单元UNAND3。
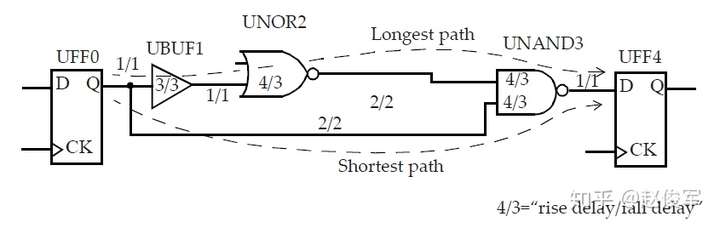
裕量计算
裕量(Slack)是信号需要到达时间(Required Time)与实际到达时间(Arrival Time)之差。在图5-17中,要求数据在7ns时保持稳定才能满足建立时间(setup)要求。但是,数据在1ns时就已稳定。因此,裕量为6ns(= 7ns-1ns)。
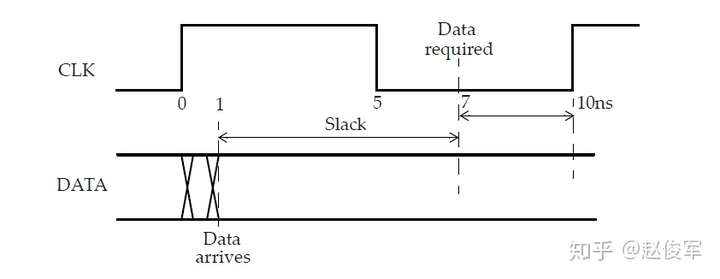
假设数据需要到达的时间是从捕获触发器的建立时间获得的,则计算过程如下:
● 需要到达时间Required_Time = Tperiod - Tsetup = 10 - 3 = 7ns
● 实际到达时间Arrival_Time = 1ns
● 裕量Slack = Required_Time - Arrival_Time = 7 - 1 = 6ns
同样,如果两个信号之间的偏斜(skew)要求为100ps,并且测得的偏斜为60ps,则偏斜的裕量为40ps(= 100ps-60ps)。
串扰噪声
本章节介绍了纳米技术中ASIC的信号完整性(signal integrity)。
● 在深亚微米(submicron)技术中,串扰(crosstalk)在设计的信号完整性中起着重要作用,串扰噪声是指两个或多个信号之间无意间的耦合。相关的噪声和串扰分析技术,即毛刺分析和串扰分析,可用于静态时序分析中,这将在本章中进行介绍。这些技术可用于使ASIC稳定运行。
概述
噪声是指影响芯片正常运行的不良或无意的现象。在纳米技术中,噪声会影响功能或器件的时序。
为什么会有噪声和信号完整性?
噪声在深亚微米技术中起重要作用的原因有以下几个:
● 金属层数量的增加:例如,一个0.25um或0.3um的工艺具有四个或五个金属层,而在65nm和45nm工艺中增加到了十个或更多的金属层。章节四中的图4-1已描绘过了金属互连线的多层结构。
● 垂直占主导地位的金属长宽比:这意味着走线既细又高,与早期工艺几何形状中比较宽不同。因此,较大比例的电容是由侧壁耦合电容组成的,该侧壁耦合电容即为相邻信号线之间的走线间电容。
● 更高的布线密度:由于具有更精细的几何形状,更多的金属线可以在物理上紧密相邻。
● 大量的交互设备和互连线:在同一硅片面积中封装了更多的标准单元和信号走线,从而导致更多的交互。
● 由于频率变高而导致波形切换加快:快速的边沿速率会导致更多的电流尖峰以及对相邻走线和单元的更大耦合效应。
● 较低的电源电压:电源电压的降低使得噪声裕量较小。
在本章中,我们特别研究串扰噪声的影响。串扰噪声是指两个或多个信号之间无意识的耦合。串扰噪声是由芯片上相邻信号之间的电容耦合引起的,这会导致一个网络的高低电平切换,从而对耦合信号产生意外影响。受影响的信号称为受害者(victim),而产生影响的信号称为攻击者(aggressor)。请注意,两个耦合的网络可能会相互影响,并且通常一个网络可能既是受害者又是攻击者。
图6-1给出了几个信号走线耦合在一起的示例,图中描绘了提取得到的耦合互连的分布式RC以及几个驱动单元和扇出单元。在此示例中,网络N1和N2之间的耦合电容为Cc1 + Cc4,而Cc2 + Cc5是网络N2和N3之间的耦合电容。
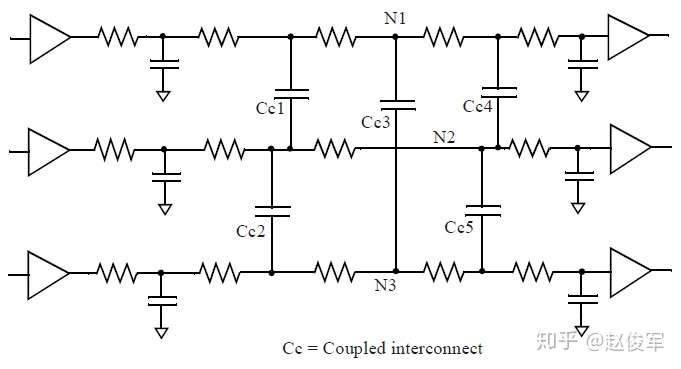
广泛地讲,串扰会带来两种类型的噪声效应:毛刺(glitch)是指由于相邻攻击者电平切换的耦合而在稳定受害者信号上产生的噪声;以及由于受害者电平切换与攻击者电平切换的耦合而导致的时序变化(串扰增量延迟)。接下去的两小节将介绍这两种类型的串扰噪声。
串扰毛刺分析
基础
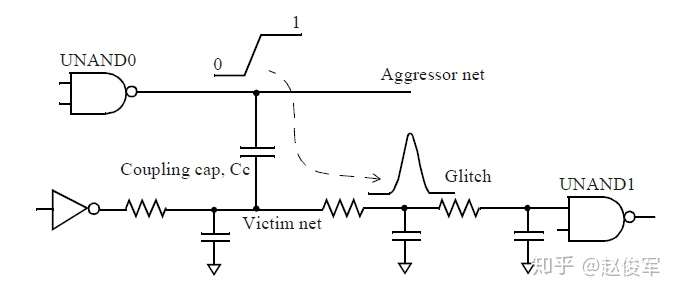
一个稳定的信号网络可能会由于攻击者电平切换时通过耦合电容转移的电荷而产生毛刺(正或负)。图6-2所示为攻击者网络上升沿电平切换的串扰引起的正毛刺。将两个网络之间的耦合电容描绘为一个集总(lumped)电容Cc而不是分布式(distributed)耦合电容,这是为了简化下面的说明,而又不失一般性。在提取所得网表的典型表示中,耦合电容可以分布在多个段中,如之前6.1节中所示。
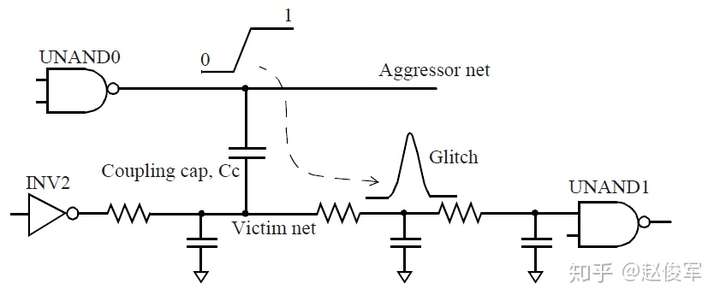
在此示例中,与非门单元UNAND0电平切换并为其输出网络充电(标记为“攻击者”)。一些电荷也通过耦合电容Cc转移到“受害”网络上,并导致正毛刺。转移的电荷量与攻击者和受害者之间的耦合电容Cc直接相关。向受害网络的接地电容上转移的电荷会导致该网络上的毛刺。由于通过驱动单元INV2的下拉(pull-down)结构转移了电荷,因此可以恢复受害网络上的稳定值(在这种情况下为低电平)。
毛刺的幅度取决于多种因素,其中一些因素是:
● 攻击者与受害者之间的耦合电容:耦合电容越大,毛刺的幅度越大。
● 攻击者网络的压摆(slew):攻击者网络上的压摆越快,毛刺的幅度越大。通常,较快的压摆是因为驱动攻击者网络的单元具有较高的输出驱动强度。
● 受害者网络接地电容:受害者网络上的接地电容越小,毛刺的幅度越大。
● 受害者网络驱动强度:驱动受害者网络的单元输出驱动强度越小,毛刺的幅度越大。
总体而言,虽然受害者网络上的稳定值得以恢复,但由于以下原因,毛刺依然可能会影响电路的功能。
● 毛刺幅度可能足够大,以至于扇出单元可以将其视为不同的逻辑值(例如,受害者网络上的逻辑0可能在扇出单元处被视为逻辑1)。 这对于时序逻辑单元(触发器或锁存器)或存储器而言尤其重要,在这些单元中,时钟或异步置位/复位引脚上的毛刺会严重影响设计功能。类似地,锁存器输入端的数据信号出现毛刺会导致锁存不正确的数据,如果在输入数据时发生毛刺也可能造成灾难性的后果。
● 即使受害者网络不驱动时序逻辑单元,但也可能通过受害者网络的扇出传播较大的毛刺,并到达时序逻辑单元的输入,这将对设计造成灾难性的后果。
毛刺种类
毛刺具有许多不同种类:
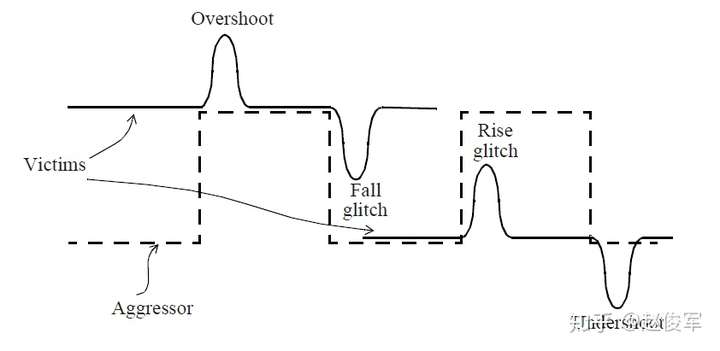
上升和下降毛刺
前面小节中的讨论说明了受害者网络上的上升毛刺(Rise Glitch),该受害者网络一直稳定在低电平。类似的情况是在稳定的高电平信号上出现负毛刺,电平下降切换的攻击者网络会在稳定的高电平信号上引起下降毛刺(Fall Glitch)。
过冲和下冲毛刺
当上升的攻击者网络与稳定高电平的受害者网络耦合时会发生什么呢?仍会有一个毛刺使受害者网络的电压值超过其稳定的高电平,这种毛刺称为过冲毛刺(Overshoot Glitch)。类似地,下降的攻击者网络与稳定低电平的受害者网络耦合时,会在受害者网络上引起下冲毛刺(Undershoot Glitch)。
由串扰引起的所有四种毛刺情况如图6-3所示:
如前面小节所述,毛刺由耦合电容、攻击者的压摆和受害者网络的驱动强度决定。计算毛刺基于的是攻击者网络转移的电流量、受害者网络的RC互连 、以及驱动受害者网络的单元的输出阻抗。详细的毛刺计算是基于库模型的:相关的噪声模型是第3章中描述的标准单元库模型的一部分,3.7节中的输出dc_current模型与单元的输出阻抗有关。
毛刺阈值和传播
如何确定网络上的一个毛刺是否可以通过扇出单元传播?如前面的小节所述,由攻击者网络耦合引起的毛刺是否可以通过扇出单元传播,具体取决于扇出单元和毛刺属性(例如毛刺高度和毛刺宽度)。该分析可以基于直流(DC)或交流(AC)噪声阈值。直流噪声分析仅检查毛刺幅度并且比较保守,而交流噪声分析则检查其他属性,例如毛刺宽度和扇出单元输出负载。下面介绍了毛刺的直流和交流分析中使用的各种阈值标准。
直流阈值
直流噪声裕度(DC noise margin)是对毛刺幅度的一种检查,是指在确保正确逻辑功能的同时输入单元的直流噪声限制。例如,只要反相器单元的输入保持在VIL最大值以下,则输出就可以保持为高电平(高于VOH最小值)。类似地,只要输入保持在VIH最小值以上,反相器单元的输出就可以保持为低电平(低于VOL最大值)。这些限制是基于单元的DC传输特性获得的,并且可以记录在单元库中。
VOH是被视为逻辑1或高电平的输出电压范围,VIL是被视为逻辑0或低电平的输入电压范围,VIH是被视为逻辑1的输入电压范围,VOL是被视为逻辑0的输出电压范围。图6-4给出了一个反相器单元的输入-输出DC传输特性图:
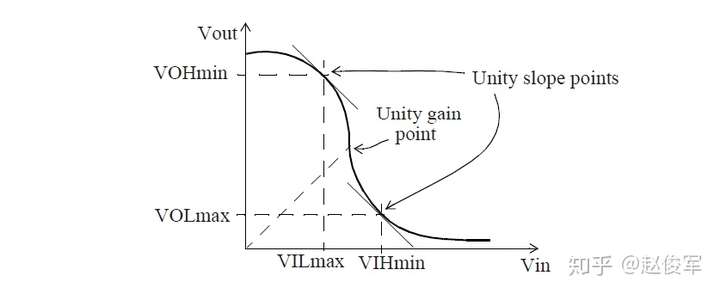
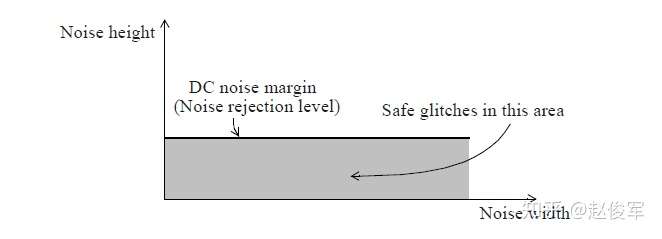
VILmax和VIHmin也称为DC裕度极限,基于VIH和VIL的DC裕度是稳态噪声极限,因此可以用作确定毛刺是否会通过扇出单元传播的判断依据。直流噪声裕量限制适用于单元的每个输入引脚。通常,DC裕度限制对于上升毛刺(输入低电平)和下降毛刺(输入高电平)是分开独立的。直流裕度的模型可以指定为单元库描述的一部分。低于直流裕度极限的毛刺(例如,低于扇出引脚的VILmax的上升毛刺)不能通过扇出传播,无论毛刺的宽度如何。因此,保守的毛刺分析会检查(所有毛刺)峰值电压电平是否满足扇出单元的VIL和VIH电平。即使有任何毛刺产生,只要所有网络都能满足扇出单元的VIL和VIH电平,就可以得出结论:毛刺对设计的功能没有任何影响(因为毛刺不会导致输出发生任何变化)。
图6-5给出了DC裕量极限的示例。对于设计中的所有网络,DC噪声裕量可以固定为相同的极限值。可以设置最大可容忍的噪声(或毛刺)幅值,在此幅值之上,噪声可以通过单元传播到输出引脚。通常,此检查可保证毛刺电平小于VILmax或大于VIHmin。毛刺高度(height)通常表示为电源的百分比。 因此,如果将DC噪声裕量设置为30%,则表明任何高度大于电压摆幅30%的毛刺都将被标识为可能通过单元传播并影响设计功能的潜在毛刺。
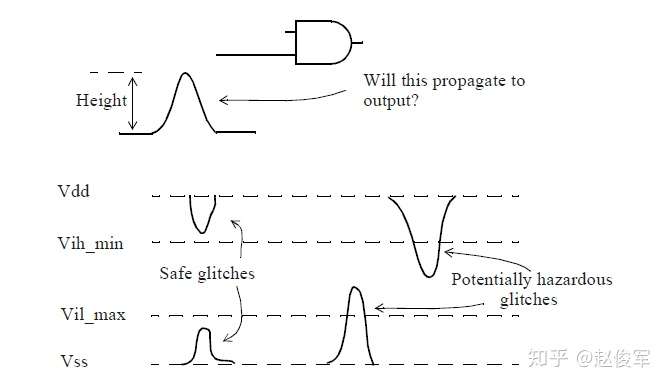
并非所有幅度大于DC噪声裕量的毛刺都能改变单元的输出。毛刺的宽度也是确定毛刺是否会传播到输出的重要考虑因素。单元输入端的窄毛刺通常不会对单元输出产生任何影响。但是,DC噪声裕量仅使用恒定的最差高度值(worst-case value),而与信号噪声宽度无关。如图6-6中的示例提供了噪声抑制水平,该噪声抑制水平是单元噪声容限的非常保守的估计。
交流阈值
如以上小节所述,毛刺分析的DC裕度极限是保守的,因为是在最坏情况下分析设计的。DC裕量极限不检查毛刺宽度,也不会影响设计的正常运行。
在大多数情况下,设计可能无法通过保守的DC噪声分析。因此,必须针对毛刺宽度和单元的输出负载来验证毛刺的影响。通常,如果毛刺很窄或扇出单元的输出电容较大,则毛刺不会影响正常的功能运行。毛刺宽度和输出电容的影响都可以用扇出单元的惯性(inertia)来解释。通常,单级(single stage)的单元将阻止任何比通过该单元的延迟还要窄得多的输入毛刺。这是因为在毛刺较窄的情况下,毛刺会在扇出单元可以响应之前就结束了,因此,非常窄的毛刺对单元没有任何影响。由于输出负载会增加通过单元的延迟,因此增加输出负载的作用是使输入端的毛刺影响最小化,尽管这会增加单元延迟。
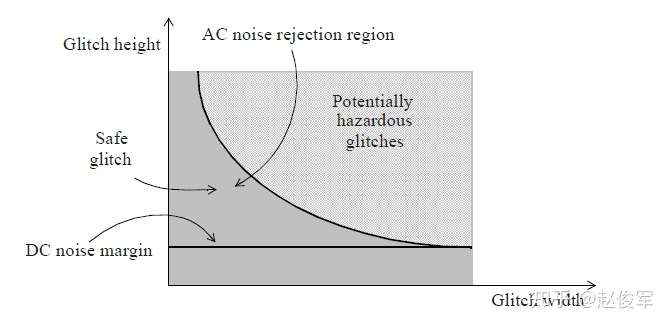
交流噪声抑制如图6-7所示(对于固定的输出电容)。黑色阴影区域表示良好或可接受的毛刺,因为这些毛刺太窄或太矮,或既窄又矮,因此对单元的功能行为没有影响。浅阴影区域表示不良或不可接受的毛刺,因为这些毛刺太宽或太高,或既宽又高,因此在单元输入端的这种毛刺会影响单元的输出。在毛刺较宽的极限情况下,毛刺阈值对应于DC噪声裕量,如图6-7所示。
对于给定的单元,增加输出负载会增加噪声容限,因为这会增加惯性延迟和可以通过单元的毛刺宽度,下面的示例说明了这种现象。图6-8(a)所示为一个未加负载的反相器单元,其输入端具有正毛刺。输入毛刺高于单元的直流裕量,因此会在其输出端引起毛刺。图6-8(b)中为相同的反相器单元,其输出端有一定负载。此时输入端相同的输入毛刺会导致输出端的毛刺小很多。如果反相器单元的输出负载更高,如图6-8(c)所示,则反相器单元的输出将没有任何毛刺。因此,增加输出端的负载可使单元更加能够抵抗从输入端传播到输出端的噪声。

如上所述,可以忽略低于AC阈值的毛刺(图6-7中的AC噪声抑制区域),或者可以认为扇出单元不受这种毛刺的影响。AC阈值区域是取决于输出负载和毛刺宽度的。如第3章中所述,抗扰度模型(noise immunity model)包括上述AC噪声抑制的影响,3.7节中介绍的propagated_noise模型除了对通过单元的传播进行建模外,还包括了AC噪声阈值的影响。
如果毛刺大于AC阈值会怎么样?在毛刺幅度超过AC阈值的情况下,单元输入处的毛刺会在单元输出处产生另一种毛刺。输出毛刺的高度和宽度是输入毛刺的宽度、高度以及输出负载的函数。该信息在单元库中进行了表征,该单元库中包含了有关输出毛刺幅度和宽度的详细表格或函数,并且这些函数是输入引脚的毛刺幅度、毛刺宽度和输出引脚负载的函数。毛刺传播会在库中的propagated_noise模型进行描述,第3章中已详细介绍了propagated_noise模型。
我们在上述内容中,对扇出单元输出处的毛刺(以及毛刺的传播)进行了计算,并在扇出网络上进行了相同的检查,依此类推。
尽管我们在上面的讨论中使用了通用术语“毛刺”,但应注意,这分别适用于前一小节中提到的所有类型的毛刺:上升毛刺(由早期模型中的propagated_noise_high或noise_immunity_high建模),下降毛刺(由早期模型中的propagated_noise_low或noise_immunity_low建模),过冲毛刺(由noise_immunity_above_high建模)和下冲毛刺(由noise_immunity_below_low建模)。
总而言之,单元的不同输入对毛刺阈值有不同的限制,这是毛刺宽度和输出电容的函数,对于输入高电平(向低电平过渡的毛刺)和输入低电平(向高电平过渡的毛刺),这些限制是独立的。噪声分析检查毛刺峰值以及宽度,并分析是否可以忽略或是否可以传播到扇出。
多攻击者的噪声累积
图6-9介绍了由于单个攻击者网络电平切换而在受害者网络上引入串扰毛刺的耦合。通常,受害者网络可以电容耦合到许多网络。当多个网络同时电平切换时,由于有多个攻击者,对受害者网络的串扰耦合噪声影响会更加严重。
大多数由多个攻击者网络引起的耦合分析都考虑了每个攻击者网络引起的毛刺效应,并计算了对受害者网络的累积效应,这看起来很保守,但这确实表明了受害者网络的最坏情况。另一种方法是使用RMS(均方根)方法,使用RMS方法时,是通过单个攻击者网络引起的毛刺的均方根来计算受害者网络的毛刺幅度的。
多攻击者的时序相关性
对于由多个攻击者引起的串扰,分析时必须考虑攻击者网络的时序相关性,并确定多个攻击者是否可以同时电平切换。STA会从攻击者网络的时序窗口获取此信息。在时序分析过程中,将获得网络的最早(earliest)和最迟(latest)电平切换时间,这些时间表示网络可以在一个时钟周期内切换的时序窗口。电平切换窗口(上升和下降)提供了有关攻击者网络是否可以一起切换的必要信息。
根据多个攻击者是否可以同时电平切换,将决定是否要合并单个攻击者对受害者网络带来的毛刺。第一步,毛刺分析为每个潜在的攻击者分别计算四种毛刺(上升、下降、下冲和过冲)。下一步将来自各个单独攻击者的毛刺带来的影响合并在一起,多个攻击者可以针对每种不同类型的毛刺分别进行组合。例如,考虑与攻击者网络A1、A2、A3和A4耦合的受害者网络V。在分析过程中,可能A1、A2和A4会引起上升和过冲毛刺,而只有A2和A3会造成下冲和下降毛刺。
考虑另一个示例,当四个攻击者网络中任何一个电平切换时,都会引起上升毛刺。如图6-10所示为时序窗口和每个攻击者网络引起的毛刺幅度。基于时序窗口,毛刺分析确定了可能导致最大毛刺的最坏情况的攻击者组合。在此示例中,电平切换窗口可分为四个区域,其中每个区域都显示了可能进行电平切换的攻击者网络,每个攻击者所引起的毛刺幅度也如图6-10所示。区域1中攻击者网络A1和A2会进行电平切换,这可能导致毛刺幅度为0.21(= 0.11 + 0.10)。区域2中攻击者网络A1、A2和A3会进行电平切换,这可能导致毛刺幅度为0.30(= 0.11 + 0.10 + 0.09)。区域3中攻击者网络A1和A3会进行电平切换,这可能导致毛刺幅度为0.20(= 0.11 + 0.09)。区域4中攻击者网络A3和A4会进行电平切换,可导致0.32(= 0.09 + 0.23)的毛刺幅度。
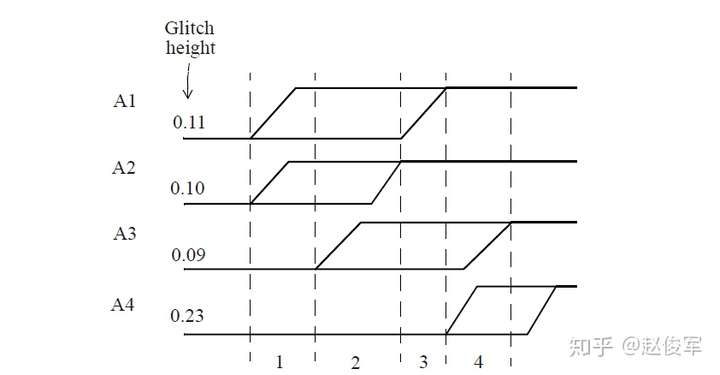
因此,区域4具有0.32这个情况最差的毛刺幅度。请注意,不使用时序窗口进行的分析将预测总毛刺幅度为0.53(= 0.11 + 0.10 + 0.09 + 0.23),这可能过于悲观。
多攻击者的功能相关性
对于多个攻击者,时序窗口通过考虑不同网络可能进行电平切换的不同时间段来减少分析中的悲观度。另外,要考虑的另一个因素是各种信号之间的功能相关性。例如,扫描控制(scan control)信号仅在扫描模式(scan mode)下电平切换,并且在执行设计的正常功能或任务模式时保持稳定。因此,在功能模式期间,扫描控制信号不会在其它任何信号上引起毛刺,扫描控制信号只有在扫描模式期间才可能成为攻击者。在某些情况下,测试时钟和功能时钟是互斥的,因此只有在关闭功能时钟时,测试时钟才可以在测试期间处于有效状态。在这些设计中,由测试时钟控制的逻辑和由功能时钟控制的逻辑创建了两组独立且互不相干的攻击者。在这种情况下,测试时钟控制的攻击者无法与功能时钟控制的其它攻击者结合使用,以进行最坏情况的噪声计算。功能相关性的另一个示例是两个攻击者彼此互补(逻辑相反)。在这种情况下,信号及其互补信号不可能在同一方向上进行电平切换以进行串扰噪声计算。
图6-11中所示为网络N1与其它三个网络N2、N3和N4耦合的示例。在功能相关性分析中,需要考虑网络的功能。假设网络N4是一个常数(例如,一个模式设置网络),因此尽管其与网络N1耦合但不能成为网络N1的攻击者。假设网络N2是调试总线(debug bus)的一部分,其在功能模式时处于稳定状态。因此,网络N2也不可能成为网络N1的攻击者。假设网络N3传输功能数据,则只能将网络N3视为网络N1的潜在攻击者。
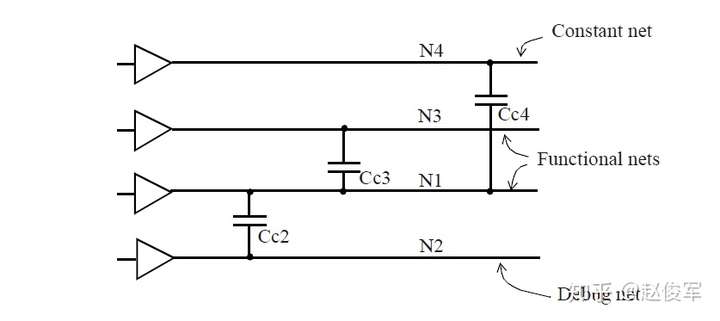
串扰延迟分析
基础
纳米设计中典型网络的电容提取包括许多相邻网络的影响,其中一些是接地电容,而其它一些则来自其它信号网络的一部分走线。接地电容和信号间电容如图6-1所示。在基本延迟计算时(不考虑任何串扰),所有这些电容均被视为网络总电容的一部分。当相邻网络稳定(或电平不切换)时,信号间电容也可以视为接地电容。当一个相邻网络电平切换时,通过耦合电容的充电电流会影响该网络的时序。网络间的等效电容会根据攻击者网络电平切换的方向而变大或变小,下面的一个简单示例对此进行了说明。
从图6-12中可以看出,网络N1通过电容Cc耦合到相邻的网络(标记为攻击者网络),并通过电容Cg接地。此示例假定网络N1在输出端具有上升电平过渡,并根据攻击者网络是否同时进行电平切换来考虑不同的情况。
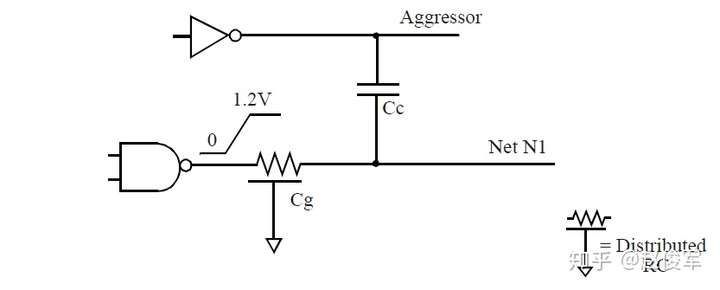
各种情况下,驱动单元所需的电容电荷可能会有所不同,如下所述。
● 攻击者网络处于稳定状态:在这种情况下,网络N1的驱动单元将提供电荷使Cg和Cc充电至Vdd。因此,该网络的驱动单元提供的总电荷为(Cg + Cc)* Vdd。这种情况可以进行基本的延迟计算,因为在这种情况下未考虑来自攻击者网络的串扰。表6-13中为此情况下在网络N1电平切换前后Cg和Cc中的电荷量:
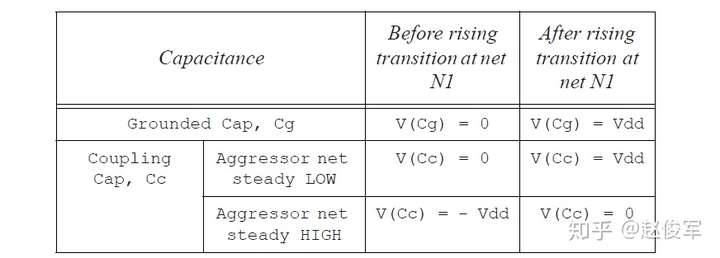
● 攻击者网络朝同方向切换电平: 在这种情况下,往同方向电平切换的攻击者网络可以起辅助驱动单元的作用。如果攻击者网络同时以相同的压摆(相同的过渡时间)进行电平切换,则驱动单元提供的总电荷仅为(Cg * Vdd )。如果攻击者网络的压摆比N1网络压摆更快,则所需的实际电荷可能甚至小于(Cg * Vdd),因为攻击者网络也可以为Cg提供充电电流。因此,在攻击者朝相同方向切换电平时,来自驱动单元的所需电荷会小于表6-13中描述的攻击者处于稳定状态时的所需电荷。因此,当攻击者网络朝相同方向切换电平时会导致网络N1切换电平的延迟更短, 延迟的减少被标记为负串扰延迟(negative crosstalk delay)。这种情况请参见表6-14,通常会在进行最小路径分析时考虑此情况。

● 攻击者网络朝相反方向切换电平:在这种情况下,耦合电容需要从-Vdd充电到Vdd。因此在电平切换前后,耦合电容上的电荷变化量为(2 * Cc * Vdd),网络N1的驱动单元以及攻击者网络均需要提供额外的电荷。这种情况会导致网络N1切换电平的延迟更大,延迟的增加被标记为正串扰延迟(positive crosstalk delay)。这种情况请参阅表6-15,通常会在进行最大路径分析时考虑此情况。
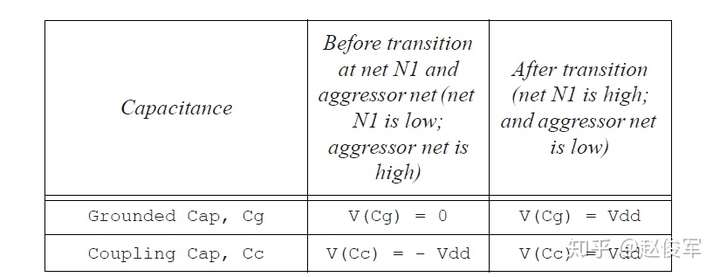
上面的示例说明了在各种情况下电容Cc的充电以及它如何影响网络N1切换电平的延迟。该示例仅考虑了网络N1处的上升过渡,但是类似的分析也适用于下降过渡。
正负串扰
基本延迟计算(不考虑任何串扰)假定驱动单元为网络总电容Ctotal(= Cground + Cc)的轨到轨(rail-to-rail)过渡提供了所有必要的电荷。如前一小节所述,当耦合(攻击者)网络和受害者网络朝相反方向切换电平时,耦合电容Cc所需的电荷会更大。朝相反方向电平切换的攻击者网络增加了来自受害者网络驱动单元的所需电荷量,并且增加了驱动单元和受害者网络互连的延迟。
类似地,当耦合(攻击者)网络和受害者网络朝相同方向切换电平时,Cc上的电荷在受害者和攻击者切换电平前后都保持不变。这减少了来自受害者网络驱动单元的所需电荷,并且减少了驱动单元和受害者网络互连的延迟。
综上所述,同时切换受害者和攻击者的电平会影响受害者网络过渡的时序。根据攻击者网络电平切换方向的不同,串扰延迟影响可能为正(减慢受害者网络过渡时间)或为负(加快受害者网络过渡时间)。
正串扰延迟影响的示例如图6-16所示。受害者网络在下降的同时,攻击者网络却在上升。攻击者网络向相反方向的电平切换会增加受害者网络的延迟。正串扰(positive crosstalk)会影响驱动单元以及互连线,这两者的延迟都会增加。
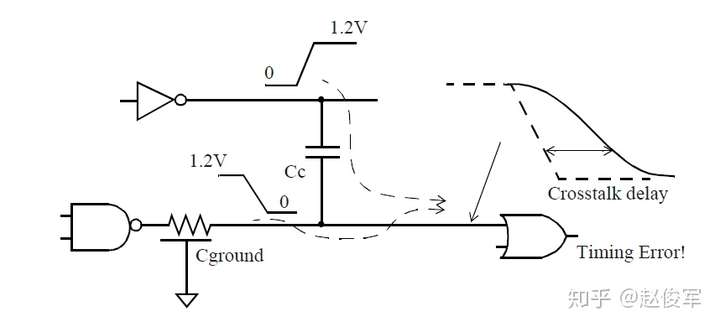
串扰延迟为负的情况如图6-17所示。攻击者网络与受害者网络同时上升,攻击者网络与受害者网络朝相同方向的电平切换可减少受害者网络的延迟。如前所述,负串扰(negative crosstalk)会影响驱动单元和互连线的时序,两者的延迟都会减小。
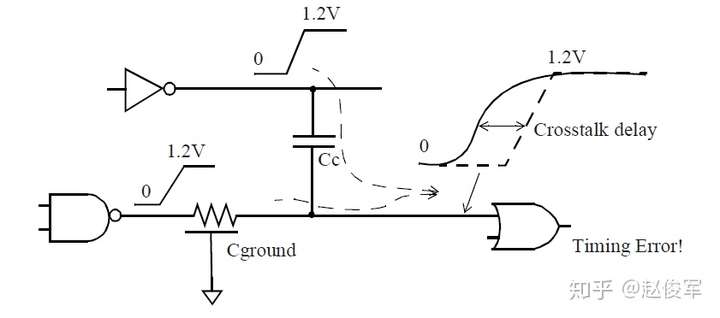
注意,最差的正串扰延迟和最差的负串扰延迟会分别针对上升和下降延迟进行计算。一般来说,由于串扰而导致的最大上升时间、最小上升时间、最大下降时间、最大下降时间延迟的攻击者是不同的,这将在下面的小节中进行介绍。
多攻击者的累积效应
在多攻击者的串扰延迟分析中将累积由每个攻击者串扰带来的影响,这类似于6.2节中介绍的串扰毛刺分析。当多个网络同时进行电平切换时,对受害者网络的串扰延迟影响将由于多攻击者而变得更加复杂。
大多数由于多攻击者而导致的耦合分析都增加了每个攻击者的增量影响,并计算了对受害者网络的累积影响。这可能看起来很保守,但是它确实表明了受害者网络最差情况的串扰延迟。
与多攻击者时的串扰毛刺分析相似,也可以使用均方根(RMS)法,这种方法的悲观度不如直接累加每个攻击者带来的影响。
攻击者与受害者网络的时序相关性
串扰延迟分析时序相关的处理在概念上类似于6.2节中介绍的串扰毛刺分析时序相关内容。只有当攻击者可以与受害者网络同时切换电平时,串扰才会影响受害者的延迟,这是使用攻击者和受害者网络的时序窗口确定的。如6.2节所述,时序窗口表示网络可以在一个时钟周期内切换的最早(earliest)和最迟(latest)时间。如果攻击者和受害者网络的时序窗口重叠,则可以计算出串扰对延迟的影响。对于多攻击者,也将类似地分析多个攻击者的时序窗口。计算各种时序区域的可能影响,并考虑串扰延迟影响最严重的时序区域,以进行延迟分析。
考虑下面的示例,其中三个攻击者网络可能会影响受害者网络的时序。攻击者网络(A1,A2,A3)与受害者网络(V)电容耦合,并且它们的时序窗口与受害者网络的时序窗口有重叠部分。图6-18中为时序窗口以及每个攻击者可能造成的串扰延迟影响。基于时序窗口,串扰延迟分析可以确定引起最大串扰延迟影响的攻击者组合。在此示例中,时序窗口可分为三个重叠区域,每个区域中都有不同的攻击者进行电平切换。区域1中A1和A2进行电平切换,这可能导致串扰延迟影响为0.26(= 0.12 + 0.14)。区域2中仅A1进行电平切换,带来的串扰延迟影响为0.14。区域3中仅A3进行电平切换,带来的串扰延迟影响为0.23。因此,区域1的串扰延迟影响0.26为最坏的情况。
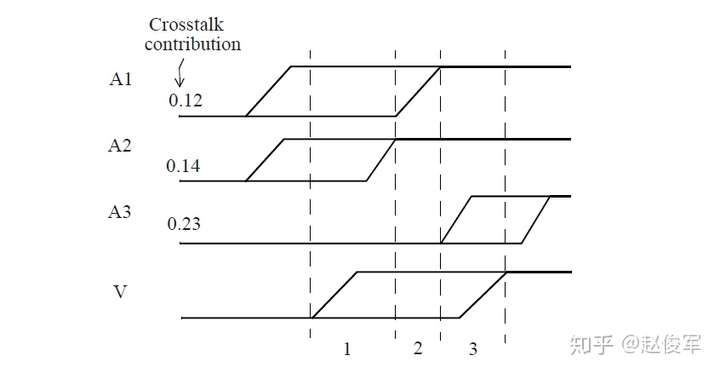
如前所述,串扰延迟分析将分别计算四种类型的串扰延迟。串扰延迟的四种类型是:正上升延迟(上升沿提前到达)、负上升延迟(上升沿滞后到达)、正下降延迟和负下降延迟。通常,在这四种情况下,网络可以具有不同的攻击者组合。例如,受害者网络具有攻击者网络A1、A2、A3和A4。在串扰延迟分析过程中,A1、A2、A4可能对正上升和负下降延迟有影响,而A2和A3对负上升和正下降延迟有影响。
攻击者与受害者网络的功能相关性
除时序窗口外,串扰延迟计算还会考虑各种信号之间的功能相关性。例如,扫描控制信号仅在扫描模式期间进行电平切换,并且在执行设计的功能或任务模式期间保持稳定。因此,在功能模式期间,扫描控制信号不可能成为攻击者。扫描控制信号只能在扫描模式期间成为攻击者,在这种情况下,扫描控制信号不能与其他功能信号组合在一起,以进行最差情况的噪声计算。
功能相关性的另一个示例是两个攻击者互补(逻辑相反)的情况。在这种情况下,信号及其互补信号永远都不可能朝相同方向上切换电平以进行串扰噪声计算。可以利用这种类型的功能相关性信息,来确保仅实际上可以一起切换电平的信号作为攻击者,从而使串扰分析结果不会过于悲观。
使用串扰延迟进行时序检查
需要为设计中的每个单元和互连线计算以下四种类型的串扰延迟影响:
● 正上升延迟(Positive rise delay):上升沿提前到达
● 负上升延迟(Negative rise delay):上升沿滞后到达
● 正下降延迟(Positive fall delay):下降沿提前到达
● 负下降延迟(Negative fall delay):下降沿滞后到达
然后,在时序分析时将串扰延迟影响用于最大和最小路径的时序检查(建立时间和保持时间检查),对数据发起和捕获触发器的时钟路径处理方式是不同的。本节将介绍建立时间和保持时间检查时对数据路径和时钟路径的详细分析。
建立时间分析
带有串扰分析的STA可以通过最差情况下数据路径和时钟路径的串扰延迟来验证设计的时序。考虑图6-19所示的逻辑电路,其中串扰可能会沿着数据路径和时钟路径在各种网络处发生。建立时间检查的最差条件是发起时钟(launch clock)路径和数据路径都具有正串扰,而捕获时钟(capture clock)路径具有负串扰。发起时钟路径和数据路径上的正串扰影响会延迟数据到达捕获触发器的时间。此外,捕获时钟路径上的负串扰影响会导致捕获触发器的时钟有效沿过早地到达。
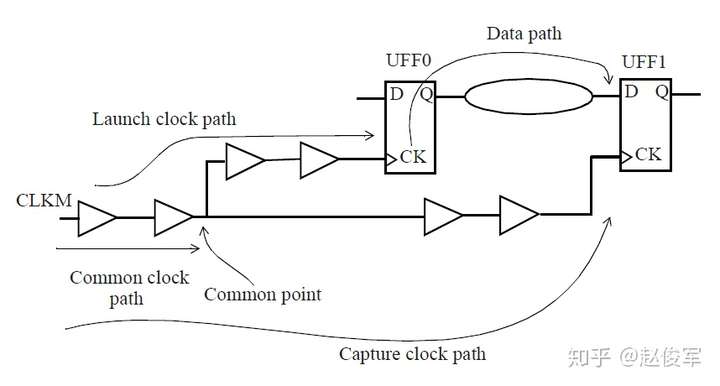
基于上述介绍,建立时间(或最大路径)分析将假定:
● 发起时钟路径出现正串扰延迟,因此发起数据较迟;
● 数据路径出现正串扰延迟,因此数据到达目的地需要更长的时间;
● 捕获时钟路径的串扰延迟为负,因此捕获触发器会更早捕获数据。
由于建立时间检查的发起和捕获时钟沿是不同的(通常间隔一个时钟周期),所以公共时钟路径(common clock path)对于发起和捕获时钟沿可能具有不同的串扰影响。
保持时间分析
STA的最差情况保持时间(或最小路径)分析类似于前面小节中介绍的最差情况建立时间分析。根据图6-19所示的逻辑电路,当发起时钟路径和数据路径均具有负串扰且捕获时钟路径具有正串扰时,会发生最差的保持时间检查条件。发起时钟路径和数据路径上的负串扰影响导致数据提前到达捕获触发器。此外,捕获时钟路径上的正串扰会导致捕获触发器的时钟有效沿延迟到达。
保持时间分析与建立时间分析对公共时钟路径上的串扰分析存在一个重要的区别:在保持时间分析中,发起和捕获时钟边沿通常是同一个边沿,通过公共时钟路径部分的时钟沿不会对发起时钟路径和捕获时钟路径具有不同的串扰影响,因此,最差情况的保持时间分析会从公共时钟路径中消除串扰影响。
因此,具有串扰的STA最差情况保持时间(或最小路径)分析将假定:
● 发起时钟(不包括公共时钟路径部分)的串扰延迟影响为负,因此可以较早地发起数据;
● 数据路径的串扰延迟影响为负,因此数据会较早到达目的地;
● 捕获时钟(不包括公共时钟路径部分)的串扰延迟影响为正,因此捕获触发器会较迟地捕获数据。
如上所述,在保持时间分析中不考虑对时钟树公共路径部分的串扰影响,仅针对时钟树的非公共路径部分计算发起时钟的正串扰影响和捕获时钟的负串扰影响。在用于保持时间分析的STA报告中,公共时钟路径可能会显示发起时钟路径和捕获时钟路径具有不同的串扰影响。但是,来自公共时钟路径的串扰影响会被作为公共路径悲观度单独减去。10.1节中将介绍一个STA报告中常见的减去路径悲观度的示例。
如前面小节所述,建立时间分析涉及时钟的两个不同边沿,这些边沿可能会在时序上受到不同影响。因此,在建立时间分析中,发起和捕获时钟路径均考虑了公共路径的串扰影响。
时钟信号至关重要,因为时钟树上的任何串扰都直接转化为时钟抖动(jitter)并影响设计的性能。因此,应该采取特殊的方法来减少时钟信号上的串扰。常见的避免噪声的方法是时钟树的屏蔽(shield),这将在6.6节中进行详细讨论。
计算复杂度
大型的纳米级设计通常过于复杂,以至于无法在合理的时间内对每个耦合电容进行分析。典型网络的寄生参数提取包含了许多相邻信号的耦合电容。大型设计通常需要对寄生参数提取、串扰延迟分析和串扰毛刺分析进行适当的设置。选择这些设置可为分析提供可以接受的准确度,同时确保对CPU的要求仍然可行。本节介绍了可用于分析大型纳米级设计的一些技术。
分层设计与分析
4.5节已介绍了可用于验证大型设计的分层方法(Hierarchical Methodology),类似的方法也可用于降低提取寄生参数和进行分析的复杂性。
对于大型设计,运行(run)一次通常无法实现寄生参数的提取。每个层级模块的寄生参数可以分别提取,这又需要在设计实现的时候使用了分层设计方法。这意味着在分层模块内部的信号与模块外部的信号之间不存在耦合,这可以通过不在模块边界上布线或通过在模块上添加屏蔽层来实现。另外,信号网络不应该布在靠近模块边界的地方,并且任何布线网络都应在靠近模块边界的地方进行屏蔽保护,这样可以避免与其他模块的网络耦合。
耦合电容的过滤
即使对于中等规模的模块,寄生参数通常也会包括大量非常小的耦合电容。小耦合电容可以在提取过程中或在分析过程中过滤掉。
这样的过滤是基于以下原则的:
● 较小的值:在串扰或噪声分析中,可以忽略非常小的耦合电容,例如低于1fF。在提取过程中,数值较小的耦合电容可以视为接地电容。
● 耦合比:耦合对受害者网络的影响是基于耦合电容相对于受害者网络总电容的相对值。具有较小耦合比(例如低于0.001)的攻击者网络可以从串扰延迟分析或串扰毛刺分析中排除。
● 合并小型攻击者:可以将影响很小的多个攻击者映射为一个较大的虚拟攻击者。这可能有点悲观,但可以简化分析。可以通过切换攻击者的子集来缓解一些悲观度,攻击者的确切子集可以通过统计方法来确定。
噪声避免技术
前面的小节介绍了串扰效应的影响和分析。在本小节中,我们将介绍一些可以在物理设计阶段使用的噪声避免技术。
● 屏蔽(Shielding):此方法要求将屏蔽线放在关键信号的两侧,屏蔽线已连接到了电源或地。关键信号的屏蔽确保了关键信号没有有效的攻击者,因为在同一金属层中最相邻的走线是处于固定电位的屏蔽走线。尽管在不同的金属层中可能存在来自布线的某些耦合,但是大多数耦合电容还是由于同一层中的电容耦合引起的。由于不同金属层(上方和下方)通常会正交走线,这样跨层的电容耦合会最小化。因此,将屏蔽线放置在同一金属层中可确保关键信号的耦合最小。如果由于布线拥塞而无法使用接地或电源线进行屏蔽,则可以把在功能模式下保持不变、电平切换不频繁的信号(如扫描控制信号)布线为关键信号的直接相邻信号。这些屏蔽方法可确保不会由于相邻网络的电容耦合而产生串扰。
● 线距(Wire spacing):这减少了与相邻网络的耦合。
● 快速压摆(Fast slew rate):网络上的压摆较快表示该网络不易受到串扰的影响。
● 保持良好的稳定电源(Maintain good stable supply):这对于串扰而言并不重要,但对于最大程度地减少由于电源变化而引起的抖动至关重要。由于电源上的噪声,可能会在时钟信号上引入大量噪声。应该添加足够的去耦电容,以最大程度地减少电源上的噪声。
● 保护环(Guard ring):衬底(substrate)上的保护环(或双重保护环)有助于将关键的模拟电路与数字噪声隔离开来。
● 深n阱(Deep n-well):与上面类似,因为在模拟部分具有深n阱,有助于防止噪声耦合到数字部分。
● 隔离块(Isolating a block):在分层设计流程中,可以将布线晕圈(halos)添加到块的边界;此外,还可以将隔离缓冲器(isolation buffers)添加到块的每个IO中。
配置STA环境
本章节介绍了如何为静态时序分析配置环境。
● 正确的约束对于分析STA结果很重要,只有准确指定设计环境,STA分析才能够识别出设计中的所有时序问题。STA的准备工作包括设置时钟、指定IO时序特性以及指定伪路径和多周期路径。在继续学习下一章的时序验证之前,请务必全面了解本章节。
什么是STA环境
大部分数字设计是同步的,从前一个时钟周期计算出的数据在时钟有效沿上被锁存在触发器中。请考虑图7-1所示的典型同步设计,假定待分析设计(DUA)会与其它同步设计交互。这意味着DUA从触发器接收数据,并将数据输出到DUA外部的另一个触发器。
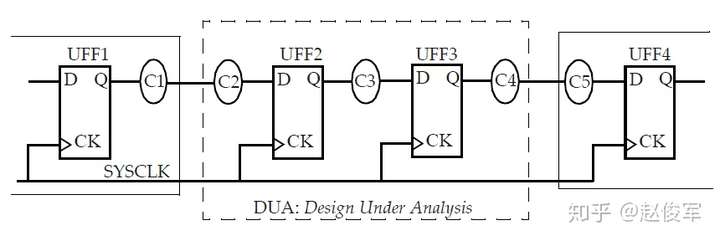
为了对这种设计执行STA,需要指定触发器的时钟、以及进入设计和退出设计的所有路径的时序约束。
图7-1中的例子假定只有一个时钟,并且C1、C2、C3、C4和C5代表组合逻辑块,其中C1和C5在待分析设计之外。
在典型的设计中,可能存在多个时钟,且许多路径都会从一个时钟域到另一个时钟域。以下各小节将介绍在这种情况下如何配置环境。
指定时钟
要定义时钟,我们需要提供以下信息:
● 时钟源(Clock source):它可以是设计的端口,也可以是设计内部单元的引脚(通常是时钟生成逻辑的一部分)。
● 周期(Period):时钟的周期。
● 占空比(Duty cycle):高电平持续时间(正相位)和低电平持续时间(负相位)。
● 边沿时间(Edge times):上升沿和下降沿的时刻。
基本定义如图7-2所示。通过定义时钟,所有内部时序路径(触发器到触发器路径)都将受到约束,这意味着可以仅使用时钟约束来分析所有内部路径。时钟约束指定触发器到触发器的路径必须占用一个周期,稍后我们将介绍如何放宽这一要求(一个周期时间)。
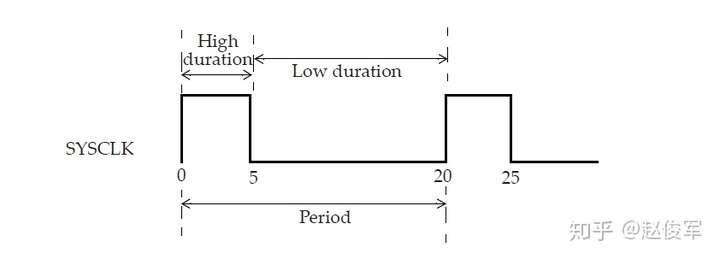
以下是一个基本的时钟约束规范:
● create_clock -name SYSCLK -period 20 -waveform {0 5} [get_ports SCLK]
该时钟名为SYSCLK,并在端口SCLK上定义。SYSCLK的周期指定为20个单位,如果未指定,默认时间单位为纳秒(通常,时间单位会在技术库中进行指定)。waveform中的第一个自变量指定出现上升沿的时刻,第二个自变量指定出现下降沿的时刻。
waveform选项中可以指定任意数量的边沿。但是,所有边沿必须在一个周期内。边沿时刻从零时刻之后的第一个上升沿开始,然后是下降沿,然后再是上升沿,以此类推,这意味着waveform列表中的所有时刻值必须单调增加。
● -waveform {time_rise time_fall time_rise time_fall ...}
另外,必须指定偶数个边沿时刻。waveform选项将指定一个时钟周期内的波形,然后不断重复。
如果未指定任何waveform选项,则默认值为:
● -waveform {0,period/2}
以下是一个没有使用waveform选项的时钟约束示例(见图7-3)。
● create_clock -period 5 [get_ports SCAN_CLK]
在此约束中,由于未指定-name选项,因此时钟的名称与端口的名称相同,即SCAN_CLK。

以下是时钟约束的另一个示例,其中波形的边沿在一个周期的中间位置(见图7-4)。
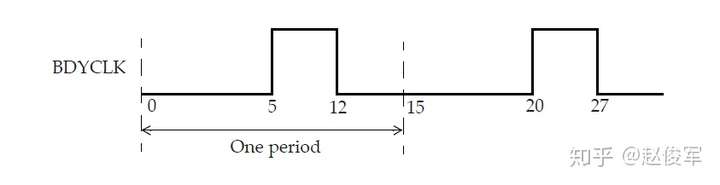
● create_clock -name BDYCLK -period 15 -waveform {5 12} [get_ports GBLCLK]
时钟的名称为BDYCLK,并且在端口GBLCLK上定义。实际上,最好将时钟名称与端口名称保持一致。
以下是另一些时钟约束示例:
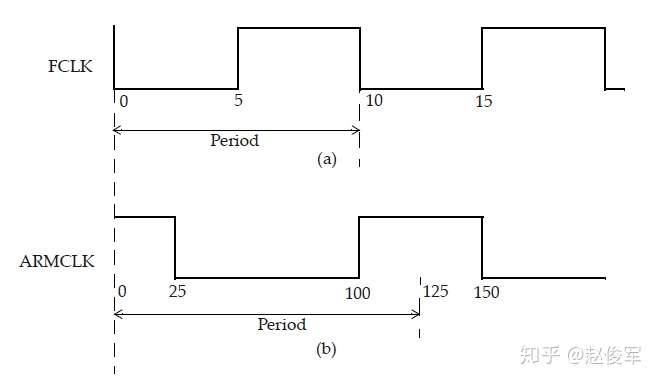
上图7-5(a)中的时钟约束为:
● create_clock -period 10 -waveform {5 10} [get_ports FCLK]
上图7-5(b)中的时钟约束为:
● create_clock -period 125 -waveform {100 150} [get_ports ARMCLK]
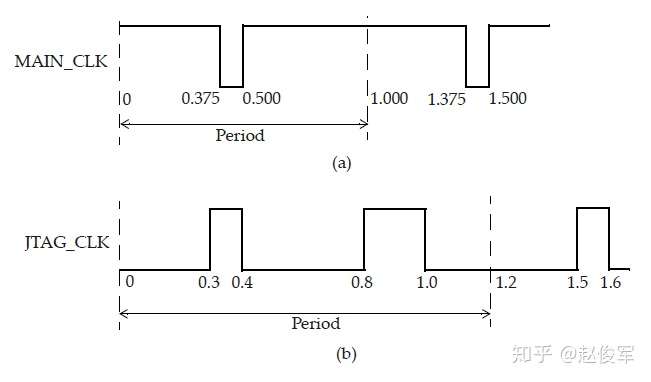
上图7-6(a)中的时钟约束为:
● create_clock -period 1.0 -waveform {0.5 1.375} [get_ports MAIN_CLK]
上图7-6(b)中的时钟约束为:
● create_clock -period 1.2 -waveform {0.3 0.4 0.8 1.0} [get_ports JTAG_CLK]
还有一些时钟约束如下:
● create_clock -period 1.27 -waveform {0 0.635} [get_ports clk_core]
● create_clock -name TEST_CLK -period 17 -waveform {0 8.5} -add [get_ports ip_io_clk[0]]
除了上述属性外,还可以在时钟源处指定过渡时间(压摆)。在某些情况下,例如顶层的输入端口或某些PLL的输出端口,工具无法自动计算出过渡时间。在这种情况下,在时钟源处显式地指定过渡时间很有用,这可以使用set_clock_transition命令来指定。
● set_clock_transition -rise 0.1 [get_clocks CLK_CONFIG]
● set_clock_transition -fall 0.12 [get_clocks CLK_CONFIG]
这个约束仅适用于理想时钟,一旦构建了时钟树就将其忽略,因为此时将会使用时钟引脚上的实际过渡时间。如果在输入端口上定义了时钟,也可以使用set_input_transition命令(参见7.7节)来约束时钟的压摆。
时钟不确定度
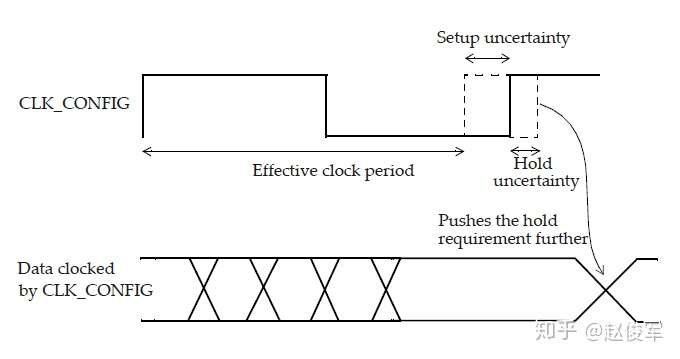
可以使用set_clock_uncertainty约束来指定时钟周期的时序不确定度(uncertainty),该不确定度可用于对可能会减少有效时钟周期的各种因素进行建模。 这些因素可能是时钟抖动(jitter)以及可能需要在时序分析中考虑的任何其它悲观度。
● set_clock_uncertainty -setup 0.2 [get_clocks CLK_CONFIG]
● set_clock_uncertainty -hold 0.05 [get_clocks CLK_CONFIG]
注意,建立时间检查的时钟不确定度将减少可用的有效时钟周期,如图7-7所示。对于保持时间检查,时钟不确定度将用作需要满足的额外时序裕量。
以下命令可用于指定跨时钟边界路径上的时钟不确定度,称为时钟间不确定度(inter-clock uncertainty)。
● set_clock_uncertainty -from VIRTUAL_SYS_CLK -to SYSCLK -hold 0.05
● set_clock_uncertainty -from VIRTUAL_SYS_CLK -to SYSCLK -setup 0.3
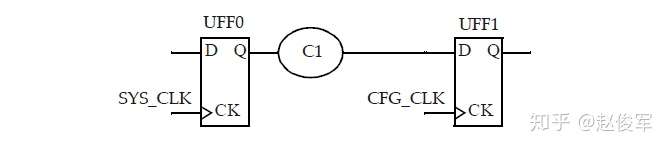
● set_clock_uncertainty -from SYS_CLK -to CFG_CLK -hold 0.05
● set_clock_uncertainty -from SYS_CLK -to CFG_CLK -setup 0.1
图7-8中为两个不同时钟域SYS_CLK和CFG_CLK之间的路径。根据上述时钟间不确定度的约束,将100ps用作建立时间检查的不确定度,将50ps用作保持时间检查的不确定度。
时钟延迟
可以使用set_clock_latency命令指定时钟的延迟。
● set_clock_latency 1.8 -rise [get_clocks MAIN_CLK]
● set_clock_latency 2.1 -fall [all_clocks]
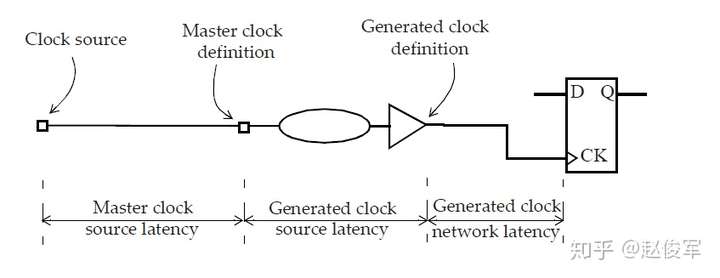
时钟延迟有两种类型:网络延迟(network latency)和源延迟(source latency)。网络延迟是指从时钟定义点(create_clock)到触发器时钟引脚的延迟。源延迟,也称为插入延迟(insertion delay),是指从时钟源到时钟定义点的延迟,源延迟可能代表片上或片外延迟,图7-9展示了这两种情况。触发器时钟引脚上的总时钟延迟是源延迟和网络延迟之和。
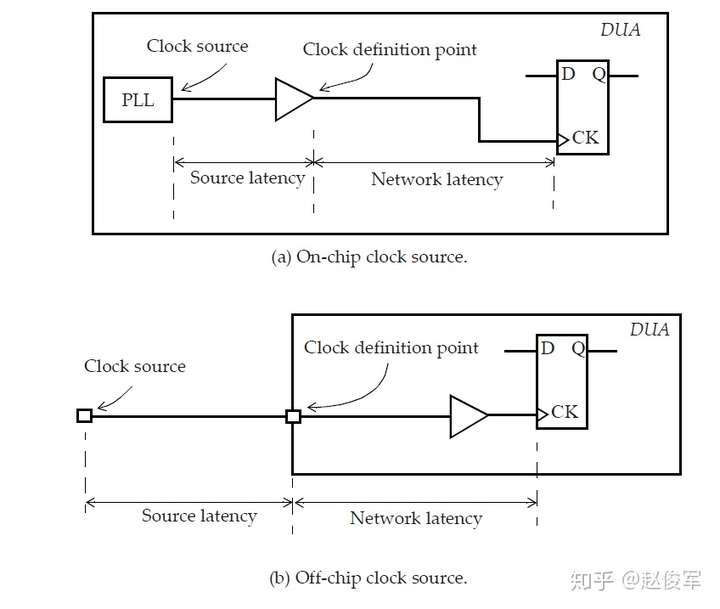
以下是一些指定源延迟和网络延迟的命令示例:
● set_clock_latency 0.8 [get_clocks CLK_CONFIG]
● set_clock_latency 1.9 -source [get_clocks SYS_CLK]
● set_clock_latency 0.851 -source -min [get_clocks CFG_CLK]
● set_clock_latency 1.322 -source -max [get_clocks CFG_CLK]
源延迟和网络延迟之间的一个重要区别是:一旦为设计建立了时钟树,就可以忽略网络延迟(假设指定了set_propagated_clock命令)。但是,即使在建立时钟树之后,源延迟也会保留。网络延迟是在进行时钟树综合(Clock Tree Synthesis)之前对时钟树延迟的估计值。在时钟树综合完成后,从时钟源到触发器时钟引脚的总时钟延迟是源延迟加上时钟树从时钟定义点到触发器的实际延迟。
下一节将介绍衍生时钟(generated clocks),7.9节将介绍虚拟时钟(virtual clocks)。
衍生时钟
衍生时钟是从主时钟(master clock)派生而来的时钟,主时钟是指使用create_clock命令定义的时钟。
在基于主时钟的设计中生成一个新时钟时,可以将这个新时钟定义为衍生时钟。例如,如果有一个时钟的三分频电路,则将在该电路的输出处定义一个衍生时钟。由于STA不知道分频逻辑输出的时钟周期已更改,更重要的是新的时钟周期是多少,因此需要定义衍生时钟。图7-10给出了衍生时钟示例,该时钟是主时钟CLKP的2分频。
● create_clock -name CLKP 10 [get_pins UPLL0/CLKOUT]
● create_generated_clock -name CLKPDIV2 -source UPPL0/CLKOUT -divide_by 2 [get_pins UFF0/Q]
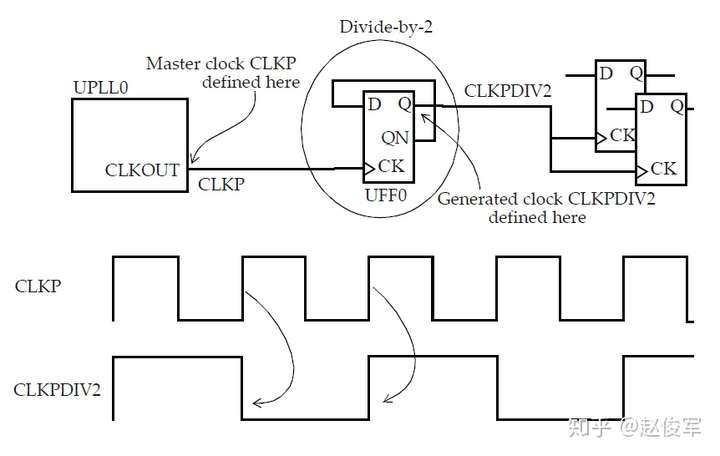
可以在触发器的输出端口定义一个新时钟是主时钟,而非衍生时钟吗?答案是肯定的,这确实是可能的,但是它也有一些缺点。定义主时钟而不是衍生时钟会创建一个新的时钟域。通常这不是问题,除了在设置STA约束时需要处理更多的时钟域外。相反,将新时钟定义为衍生时钟不会创建新的时钟域,并且衍生时钟会被认为与其主时钟同相,衍生时钟不需要进行额外的约束。因此,尽量将内部新生成的时钟定义为衍生时钟,而不是将其声明为另一个主时钟。
主时钟和衍生时钟之间的另一个重要区别是时钟源的概念。在主时钟中,时钟源位于主时钟的定义点。而在衍生时钟中,时钟源是主时钟的源而不是衍生时钟的源。这意味着在时钟路径报告中,时钟路径的起点始终是主时钟的定义点。这样一来,与定义新的主时钟相比,衍生时钟具有很大优势,因为对于新的主时钟,是不会自动考虑源延迟的。
图7-11给出了一个在两个输入端都有时钟的多路复用器示例,在这种情况下,不必在多路复用器的输出端定义时钟。如果选择信号设置为常数,则多路复用器的输出会自动获取正确的时钟传播。而如果多路复用器的选择端不受约束,则出于STA的目的,两个时钟都将通过多路复用器传播。在这样的情况下,STA会报告出TCLK和TCLKDIV5之间的路径。注意,这样的路径是不可能存在的,因为选择信号只能选择一个多路复用器的时钟输入。在这种情况下,可能需要设置伪路径或指定这两个时钟之间的互斥(exclusive)关系,以避免报告出错误的路径。当然,这假定设计中其它部分的TCLK和TCLKDIV5之间没有路径。
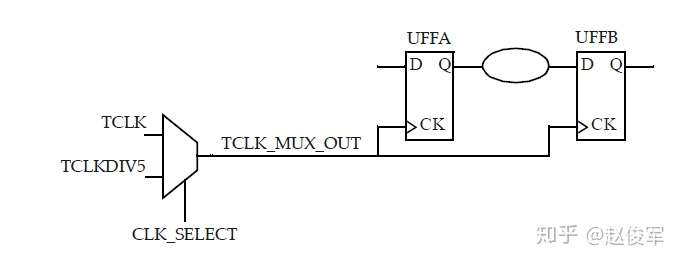
如果多路复用器选择信号不是静态不变的并且在运行期间会发生变化,这样会发生什么呢? 在这种情况下,会对多路复用器输入端进行时钟门控(clock gating)检查,时钟门控检查将在第10章中介绍,这些检查可确保多路复用器输入端的时钟相对于多路复用器选择信号能够安全地切换。
图7-12给出了一个示例,其中时钟SYS_CLK由触发器的输出进行门控。由于触发器的输出可能不是恒定的,因此处理这种情况的一种方法是在与门单元的输出处定义一个衍生时钟,该时钟与输入时钟相同。
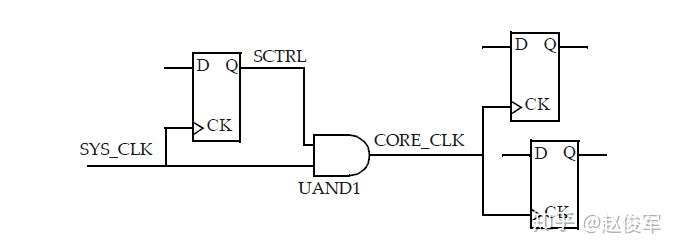
● create_clock 0.1 [get_ports SYS_CLK]
● create_generated_clock -name CORE_CLK -divide_by 1 -source SYS_CLK [get_pins UAND1/Z]
下一个示例是一个衍生时钟,其频率高于源时钟的频率。波形如图7-13所示:
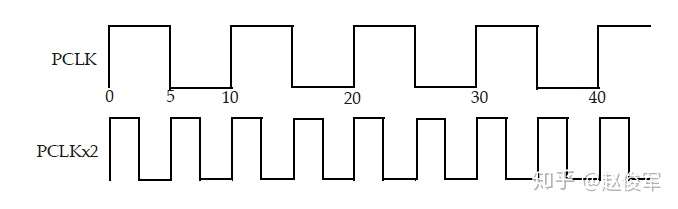
● create_clock -period 10 -waveform {0 5} [get_ports PCLK]
● create_generated_clock -name PCLK×2 -source [get_ports PCLK] -multiply_by 2 [get_pins UCLKMULTREG/Q]
请注意,在主时钟定义中指定了主时钟周期,然后-multiply_by和-divide_by选项指定了衍生时钟的频率。
时钟门控单元输出端的主时钟示例
考虑图7-14中所示的时钟门控示例,两个时钟分别输入进一个与门单元中,问题是与门单元的输出是什么呢?如果与门单元的输入均为时钟,则可以安全地在与门单元的输出端定义一个新的主时钟,因为该单元的输出与任何一个输入时钟都没有相位关系的可能性很小。
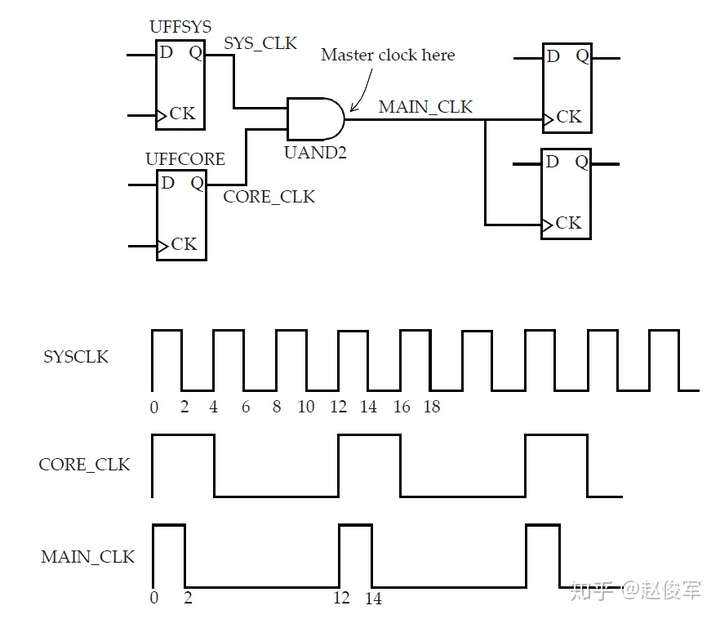
● create_clock -name SYS_CLK -period 4 -waveform {0 2} [get_pins UFFSYS/Q]
● create_clock -name CORE_CLK -period 12 -waveform {0 4} [get_pins UFFCORE/Q]
● create_clock -name MAIN_CLK -period 12 -waveform {0 2} [get_pins UAND2/Z]
在内部引脚上创建时钟的一个缺点是:它会影响路径延迟计算,并迫使设计人员手动计算源延迟。
使用Edge和Edge_shift选项生成时钟
图7-15给出了一个衍生时钟的示例,除两个不同相的时钟外,还会生成一个二分频时钟。各时钟的波形也显示在图中。
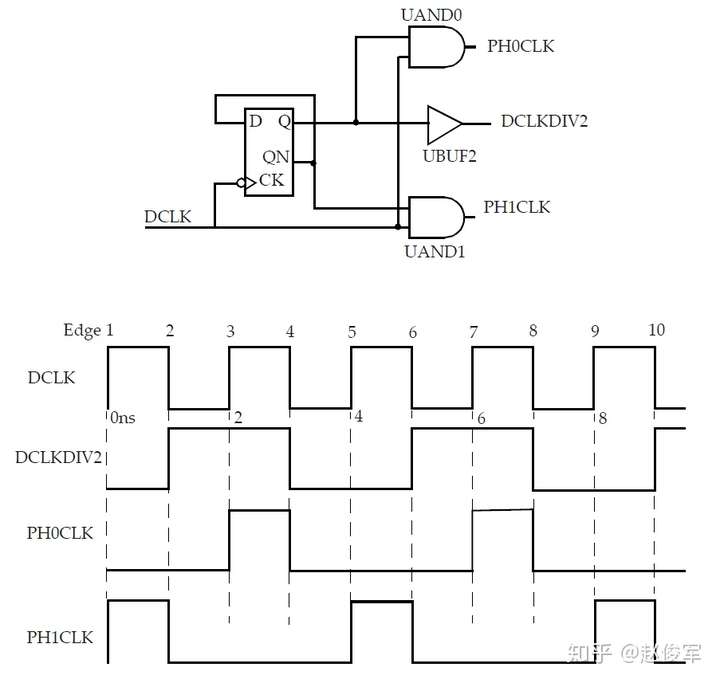
下面给出了该示例中所有时钟的定义。衍生时钟的定义使用了-edges选项,这是定义衍生时钟的另一种方法。该选项采用源主时钟{上升,下降,上升}的边沿列表,以形成新的衍生时钟。主时钟的第一个上升沿是沿1,第一个下降沿是沿2,下一个上升沿是沿3,依此类推。
● create_clock -period 2 [get_ports DCLK]
● create_generated_clock -name DCLKDIV2 -edge {2 4 6} -source DCLK [get_pins UBUF2/Z]
● create_generated_clock -name PH0CLK -edges {3 4 7} -source DCLK [get_pins UAND0/Z]
● create_generated_clock -name PH1CLK -edges {1 2 5} -source DCLK [get_pins UAND1/Z]
如果衍生时钟的第一个边沿是下降沿怎么办?考虑如图7-16所示的衍生时钟G3CLK。可以通过指定边沿5、7和10来定义这种衍生时钟,如以下时钟约束所示。注意,1ns时刻的下降沿将被自动推断出来。
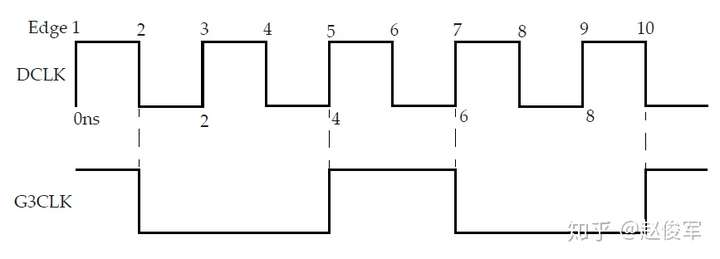
● create_generated_clock -name G3CLK -edge {5 7 10} -source DCLK [get_pins UAND0/Z]
-edge_shift选项可与-edges选项一起使用,以指定相应边沿的任何偏移以形成新的衍生波形。它指定边沿列表中每个边沿的偏移量(以时间单位)。以下是使用此选项的示例:
● create_clock -period 10 -waveform {0 5} [get_ports MIICLK]
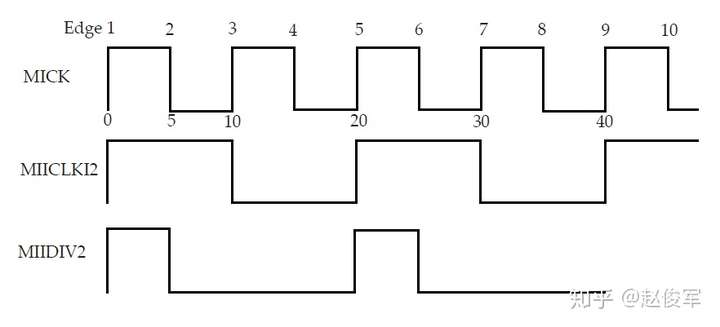
● create_generated_clock -name MIICLKDIV2 -source MIICLK -edges {1 3 5} [get_pins UMIICLKREG/Q]
● create_generated_clock -name MIIDIV2 -source MIICLK -edges {1 1 5} -edge_shift {0 5 0} [get_pins UMIIDIV/Q]
边沿列表中的边沿序列必须以非降序排列,但是同一边沿可重复使用,以指示不同于源时钟占空比的时钟脉冲。上例中的-edge_shift选项通过将源时钟的边沿1移位0ns获得了衍生时钟的第一个边沿,通过将源时钟的边沿1偏移5ns获得了衍生时钟的第二个边沿,而通过将源时钟的边沿5移位0ns获得了衍生时钟的第三个边沿。下图7-17显示了上述波形:
使用Invert选项生成时钟
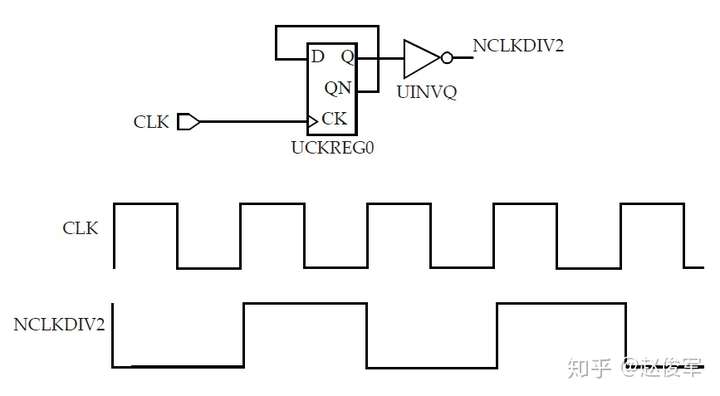
这是衍生时钟的另一个示例,这个示例使用了-invert选项:
● create_clock -period 10 [get_ports CLK]
● create_generated_clock -name NCLKDIV2 -divide_by 2 -invert -source CLK [get_pins UINVQ/Z]
在所有其它衍生时钟选项都被使用后,-invert选项将会对衍生时钟进行反相。图7-18给出了产生这种反相时钟的原理图:
衍生时钟的时钟延迟
也可以为衍生时钟指定时钟延迟,在衍生时钟上指定的源延迟还包括了从主时钟定义点到衍生时钟定义点的延迟。因此,由衍生时钟驱动的触发器的时钟引脚的总时钟延迟是主时钟源延迟、衍生时钟源延迟和衍生时钟网络延迟的总和。如下图7-19所示:
衍生时钟可以将另一个衍生时钟作为其时钟源,即一个衍生时钟也可以具有衍生时钟,以此类推。但是,衍生时钟只能有一个主时钟。在后面的章节中将介绍更多衍生时钟的示例。
典型的时钟生成方案
图7-20给出了在典型ASIC设计中如何进行时钟分配(clock distribution)的情形。晶振(Oscillator)在芯片外部产生低频(典型值为10-50 MHz)时钟,片上PLL将其用作参考时钟,以生成高频低抖动时钟(典型值为200-800 MHz)。然后,该PLL的输出时钟被输入到时钟分频器逻辑中,该逻辑产生ASIC所需的时钟。
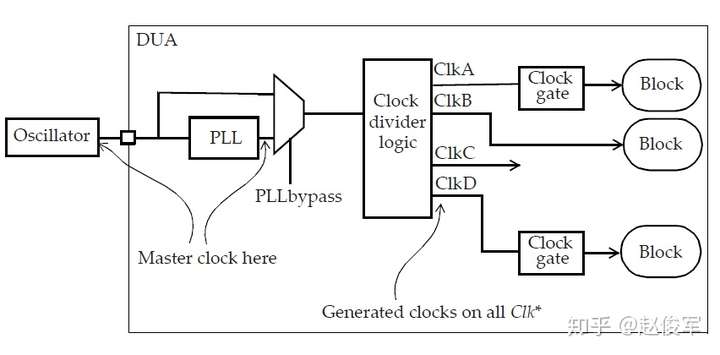
在时钟分配的某些分支上,可能有时钟门控(clock gates)用于在设计的无效部分关闭时钟,以在必要时节省功耗。在PLL的输出端也可以接一个多路复用器,以便在必要时可以绕过PLL。
在进入设计的芯片输入端口处为参考时钟定义了一个主时钟,在PLL的输出处定义了第二个主时钟。PLL的输出时钟与参考时钟没有任何相位关系。因此,PLL的输出时钟不应是参考时钟的衍生时钟。很有可能的是,由时钟分频器逻辑生成的所有时钟都将被指定为PLL输出处主时钟的衍生时钟。
约束输入路径
本节将介绍输入路径的约束。这里需要注意的一点是,STA无法检查不受约束的路径上的任何时序,因此需要约束所有路径以进行时序分析。在后面的章节中会介绍一些示例,其中一些示例可能并不关心某些逻辑,因而这些输入路径可能可以不用约束。例如,设计人员可能并不在乎一些输入控制信号的时序,因此可能并不需要进行本节中将要介绍的时序检查。但是,本节假定我们要约束全部的输入路径。
图7-21中为待分析设计(DUA)的输入路径。触发器UFF0在设计的外部,并向设计内部的触发器UFF1提供数据。数据通过输入端口INP1连接两个触发器。
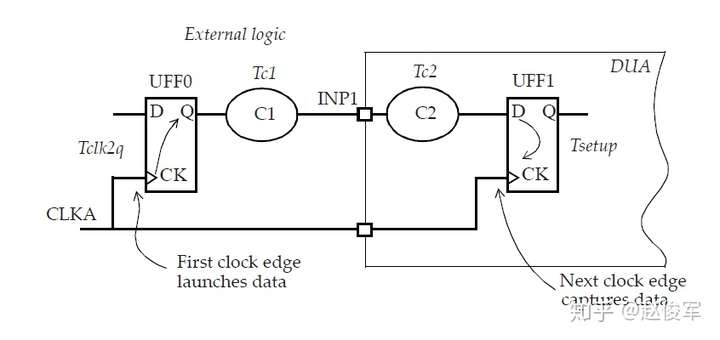
CLKA的时钟定义指定了时钟周期,这是两个触发器UFF0和UFF1之间可用的总时间。外部逻辑所需的时间为Tclk2q(数据发起触发器UFF0的CK至Q延迟)加上Tc1(通过外部组合逻辑的延迟),因此输入引脚INP1上的延迟定义指定了Tclk2q加上Tc1的外部延迟。并且这个外部延迟是相对于一个时钟指定的,在本示例中为时钟CLKA。
以下是输入延迟的约束:
● set Tclk2q 0.9
● set Tc1 0.6
● set_input_delay -clock CLKA -max [expr Tclk2q + Tc1] [get_ports INP1]
该约束指定输入端口INP1的外部延迟为1.5ns,且这是相对于时钟CLKA而言的。假设CLKA的时钟周期为2ns,则INP1引脚的逻辑只有500ps(= 2ns-1.5ns)可以在设计内部中传播。此输入延迟定义意味着输入约束为:Tc2加上触发器UFF1的Tsetup必须小于500ps,才可以确保可靠地捕获到触发器UFF0发起的数据。请注意,上述外部延迟值被指定为了最大值(max)。
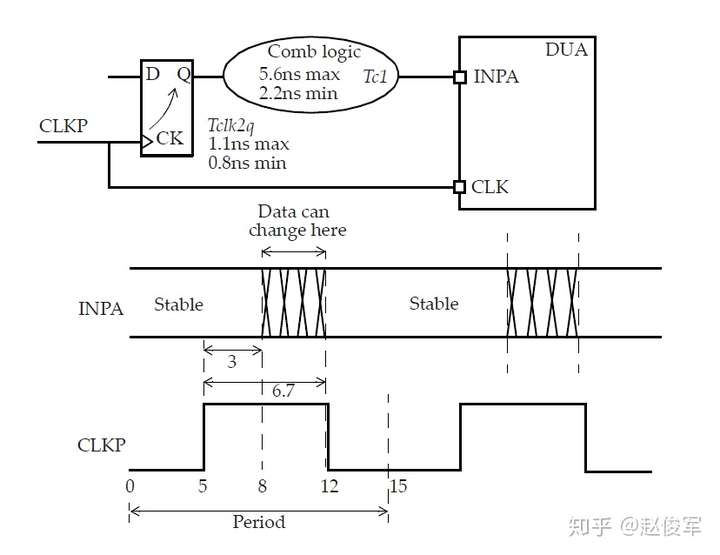
让我们同时考虑最大和最小延迟情况,如图7-22所示。以下是此示例的约束:
● create_clock -period 15 -waveform {5 12} [get_ports CLKP]
● set_input_delay -clock CLKP -max 6.7 [get_ports INPA]
● set_input_delay -clock CLKP -min 3.0 [get_ports INPA]
INPA的最大和最小延迟是从CLKP到INPA的延迟中得出的,最大和最小延迟分别是最长和最短路径延迟,这些通常也可以对应于最坏情况(worst-case)下的慢速(最大时序工艺角)和最佳情况(best-case)下的快速(最小时序工艺角)。因此,最大延迟对应于最大时序工艺角下的最长路径延迟,最小延迟对应于最小时序工艺角下的最短路径延迟。在我们的示例中,1.1ns和0.8ns是Tck2q的最大和最小延迟值。组合逻辑路径延迟Tc1的最大延迟为5.6ns,最小延迟为2.2ns。INPA上的波形显示了数据到达设计输入端的时间窗口,以及预计达到稳定状态的时间。从CLKP到INPA的最大延迟为6.7ns(= 1.1ns + 5.6ns),最小延迟为3ns(= 0.8ns + 2.2ns),这些延迟是相对于时钟有效沿指定的。在给定外部输入延迟的情况下,设计内部的可用建立时间是慢角(slow corner)下的8.3ns(= 15ns-6.7ns)和快角(fast corner)下的12ns(= 15ns-3.0ns)中的最小值。因此,8.3ns是用来可靠地捕获DUA内部数据的可用时间。
以下是输入约束的更多示例:
● set_input_delay -clock clk_core 0.5 [get_ports bist_mode]
● set_input_delay -clock clk_core 0.5 [get_ports sad_state]
由于未指定max或min选项,因此500ps这个值将同时用于最大延迟和最小延迟。此外部输入延迟是相对于时钟clk_core的上升沿指定的(如果输入延迟是相对于时钟的下降沿指定的,则必须使用-clock_fall选项)。
约束输出路径
本节将借助下面的三个例子来介绍输出路径的约束。
例子A
图7-23为一条通过待分析设计输出端口的路径示例,其中Tc1和Tc2是通过组合逻辑的延迟。
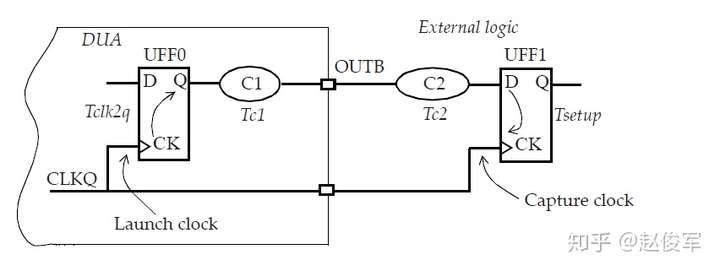
时钟CLKQ的周期定义了触发器UFF0和UFF1之间的总可用时间。外部逻辑的总延迟为Tc2加上Tsetup,此总延迟Tc2 + Tsetup必须作为输出延迟约束的一部分来指定。注意,输出延迟是相对于捕获时钟指定的,数据必须及时到达外部触发器UFF1才能满足其建立时间要求。
● set Tc2 3.9
● set Tsetup 1.1
● set_output_delay -clock CLKQ -max [expr Tc2 + Tsetup] [get_ports OUTB]
这指定了相对于时钟边沿的最大外部延迟为Tc2加上Tsetup,即5ns的延迟。最小延迟可以类似地指定。
例子B
图7-24给出了同时具有最小和最大延迟的示例。最大路径延迟为7.4ns(=Tc2最大值加上Tsetup = 7 + 0.4),最小路径延迟为-0.2ns(=Tc2最小值减去Thold = 0-0.2)。因此,输出约束为:
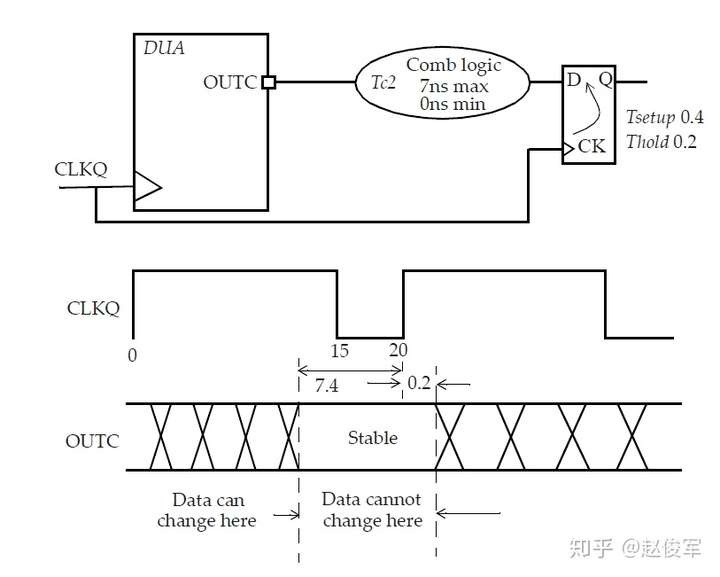
● create_clock -period 20 -waveform {0 15} [get_ports CLKQ]
● set_output_delay -clock CLKQ -min -0.2 [get_ports OUTC]
● set_output_delay -clock CLKQ -max 7.4 [get_ports OUTC]
图7-24中的波形显示了OUTC必须保持稳定状态的时间,以确保外部触发器能够可靠地捕获它。这说明在所需的稳定区域开始之前,数据就必须在输出端口准备就绪,并且必须保持稳定,直到稳定区域结束为止。这同样反映了DUA内部对输出端口OUTC逻辑的时序要求。
例子C
这是另一个输入约束和输出约束的示例。该模块具有两个输入端口DATAIN和MCLK,以及一个输出端口DATAOUT。图7-25显示了预期的波形。
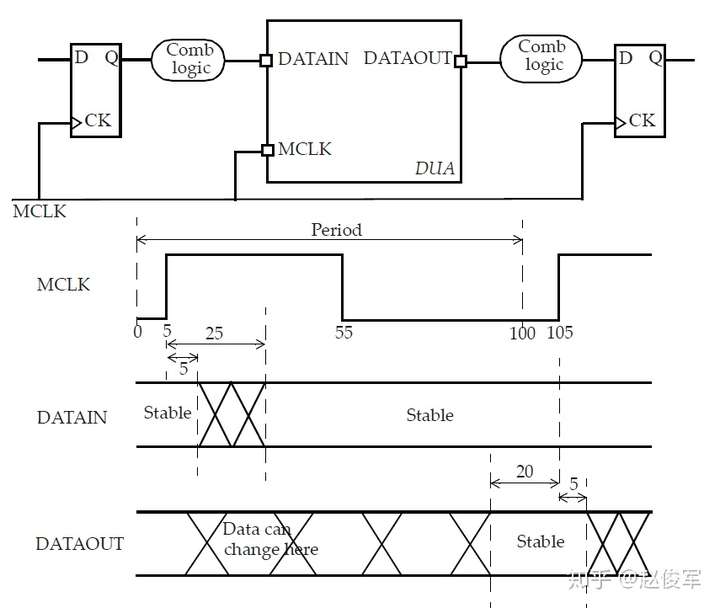
● create_clock -period 100 -waveform {5 55} [get_ports MCLK]
● set_input_delay 25 -max -clock MCLK [get_ports DATAIN]
● set_input_delay 5 -min -clock MCLK [get_ports DATAIN]
● set_output_delay 20 -max -clock MCLK [get_ports DATAOUT]
● set_output_delay -5 -min -clock MCLK [get_ports DATAOUT]
时序路径组
设计中的时序路径可以视为路径的集合,每个路径都有一个起点和一个终点。时序路径的示例如下图7-26所示:
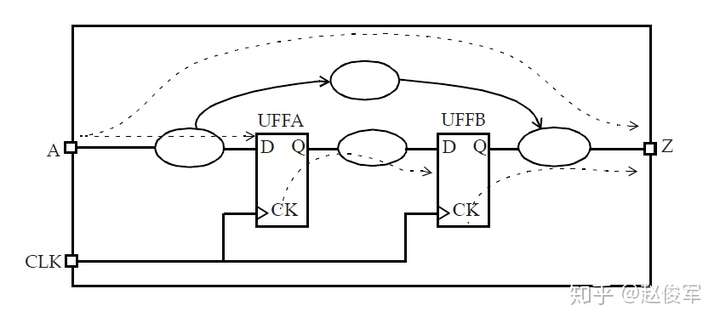
在STA中,时序路径是根据有效的起点和终点来划分的。有效的起点包括:输入端口或者同步器件(如触发器和存储器)的时钟引脚。有效的终点包括:输出端口或者同步器件的数据输入引脚。因此,有效的时序路径包括:
● 从输入端口到输出端口
● 从输入端口到触发器或存储器的数据输入引脚
● 从一个触发器或存储器的时钟引脚到另一个触发器或存储器的数据输入引脚
● 从一个触发器或存储器的时钟引脚到输出端口
图7-26中的有效时序路径包括:
● 输入端口A到输出端口Z
● 输入端口A到触发器UFFA的D引脚
● 触发器UFFA的CK引脚到触发器UFFB的D引脚
● 触发器UFFB的CK引脚到输出端口Z
时序路径可以根据与路径终点相关的时钟分类为不同时序路径组(path groups)。因此,每个时钟都有一组与之相关的时序路径。还有一个默认时序路径组,其中包括了所有非时钟(异步)路径。
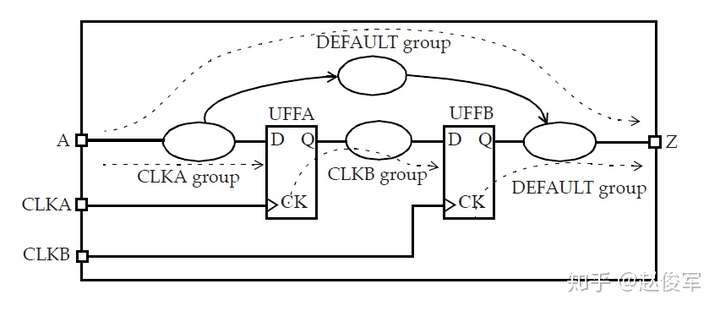
在图7-27的示例中,时序路径分组为:
● CLKA组:输入端口A到触发器UFFA的D引脚
● CLKB组:触发器UFFA的CK引脚到触发器UFFB的D引脚
● 默认组:输入端口A到输出端口Z、触发器UFFB的CK引脚到输出端口Z
静态时序分析和报告通常分别在每个时序路径组中单独执行。
外部属性建模
尽管create_clock、set_input_delay和set_output_delay足以约束设计中用于执行时序分析的所有路径,但这些并不足以获取该模块IO引脚上的准确时序。为了准确地对设计环境进行建模,还需要以下属性。对于输入,需要在输入端口处指定压摆。可以使用以下方式提供此信息:
● set_drive
● set_driving_cell
● set_input_transition
对于输出,需要指定输出引脚的负载电容。可以使用以下命令来指定:
● set_load
驱动强度建模
set_drive和set_driving_cell约束用于对驱动模块输入端口的外部单元的驱动强度进行建模。在没有这些约束的默认情况下,假定所有输入都具有无限的驱动强度,即输入引脚的过渡时间为0。
set_drive明确指定了DUA输入引脚上的驱动电阻值,该电阻值越小,驱动强度越高,电阻值为0表示无限的驱动强度。
● set_drive 100 UCLK
● set_drive -rise 3 [all_inputs]
● set_drive -fall 2 [all_inputs]
输入端口的驱动强度用于计算第一个单元的过渡时间。指定的驱动强度还可用于计算在任何RC互连情况下从输入端口到第一个单元的延迟值,计算公式如下:
● 延迟值 = (驱动强度 * 网络负载) + 互连线延迟
set_driving_cell约束提供了一种更方便、更准确的方法来描述端口的驱动能力。set_driving_cell可用于指定驱动输入端口的单元类型。
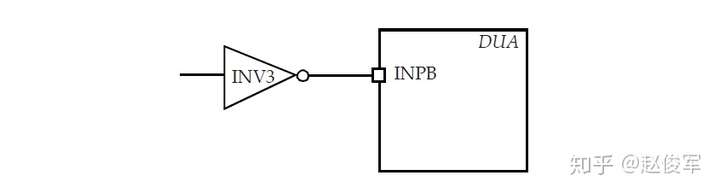
● set_driving_cell -lib_cell INV3 -library slow [get_ports INPB]
● set_driving_cell -lib_cell INV2 -library tech13g [all_inputs]
● set_driving_cell -lib_cell BUFFD4 -library tech90gwc [get_ports {testmode[3]}]
与set_drive约束一样,set_driving_cell也可用于计算第一个单元的过渡时间,并在任何互连情况下计算从输入端口到第一个单元的延迟值。
使用set_driving_cell约束的一个注意点是:由于输入端口上的电容性负载而导致驱动单元的增量延迟被视作为输入上的附加延迟被包括在内。
作为上述方法的替代方法,set_input_transition约束提供了一种在输入端口表示过渡时间的便捷方法,并且可以指定参考时钟。以下是图7-30中示例的约束以及其它约束示例:
● set_input_transition 0.85 [get_ports INPC]
● set_input_transition 0.6 [all_inputs]
● set_input_transition 0.25 [get_ports SD_DIN*]
总之,设计人员需要指定输入端的压摆值来确定输入路径中第一个单元的延迟。在没有该约束的情况下,将假设为理想过渡值0,这显然是不现实的。
电容负载建模
set_load约束在输出端口上设置了电容性负载,以模拟由输出端口驱动的外部负载。默认情况下,端口上的电容性负载为0。可以将负载显式地指定为电容值或某个单元的输入引脚电容。
● set_load 5 [get_ports OUTX]
● set_load 25 [all_outputs]
● set_load -pin_load 0.007 [get_ports {shift_write[31]}]
指定输出上的负载很重要,因为该值会影响驱动输出的单元的延迟。在没有该约束的情况下,将假定负载为0,这显然是不现实的。
set_load约束还可用于在设计中指定内部网络上的负载,以下是一个例子:
● set_load 0.25 [get_nets UCNT5/NET6]
设计规则检查
STA中两个常用的设计规则是最大过渡时间-max_transition和最大电容-max_capacitance。这些规则将会检查设计中的所有端口和引脚是否满足过渡时间和电容的规定约束。这些规则可以使用以下命令指定:
● set_max_transition
● set_max_capacitance
作为STA的一部分,任何设计规则的违例(violation)均以裕量(slack)的形式报告。以下是些例子:
● set_max_transition 0.6 IOBANK
● set_max_capacitance 0.5 [current_design]
网络上的电容是通过将所有引脚电容加上任何IO负载再加上网络上的任何互连电容的总和计算得出的。下图7-32为一个示例:
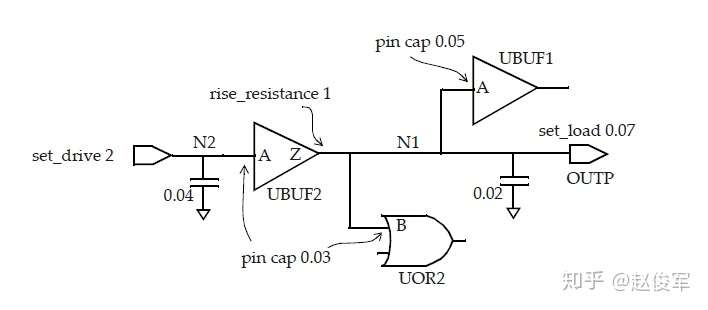
● 网络N1的总电容 = UBUF1的A引脚电容 + UOR2的B引脚电容 + OUTP的输出负载电容 + 走线互连电容
= 0.05 + 0.03 + 0.07 + 0.02 = 0.17 pF
● 网络N2的总电容 = UBUF2的A引脚电容 + 走线互连电容
= 0.03 + 0.04 = 0.07 pF
过渡时间是延迟计算的一部分。对于图7-32中的示例(假设UBUF2单元使用线性延迟模型):
● UBUF2的A引脚过渡时间 = 2 * 网络N2的总电容 = 2 * 0.07 = 0.14ns = 140ps
● 输出端口OUTP过渡时间 = UBUF2的Z引脚的驱动电阻 * 网络N1的总电容
= 1 * 0.17 = 0.17ns = 170ps
还可以为设计指定其他设计规则检查,比如:set_max_fanout(指定设计中所有引脚的扇出约束),set_max_area(用于设计)。但是,这些检查适用于综合(synthesis)而非STA。
虚拟时钟
虚拟时钟(virtual clock)是存在的时钟,但与设计中的任何引脚或端口均不相关。在STA中仅用作参考,以指定相对于时钟的输入延迟和输出延迟。虚拟时钟的示例如图7-33所示。 待分析设计的时钟端为CLK_CORE,但输入端口ROW_IN的驱动时钟为CLK_SAD。在这种情况下,如何指定输入端口ROW_IN的IO约束呢?同样,在输出端口STATE_O上也会出现同样的问题。
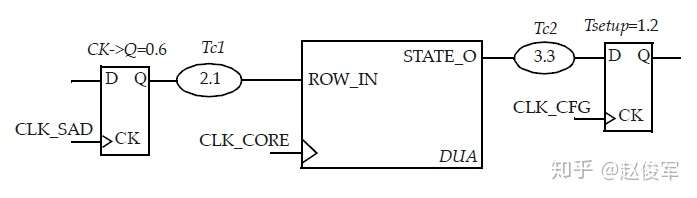
为了处理这种情况,可以在不指定源端口或引脚的情况下来定义虚拟时钟。对于图7-33中的示例,为CLK_SAD和CLK_CFG定义了虚拟时钟。
● create_clock -name VIRTUAL_CLK_SAD -period 10 -waveform {2 8}
● create_clock -name VIRTUAL_CLK_CFG -period 8 -waveform {0 4}
● create_clock -period 10 [get_ports CLK_CORE]
定义了这些虚拟时钟后,就可以相对于该虚拟时钟来指定IO约束。
● set_input_delay -clock VIRTUAL_CLK_SAD -max 2.7 [get_ports ROW_IN]
● set_output_delay -clock VIRTUAL_CLK_CFG -max 4.5 [get_ports STATE_O]
图7-34显示了输入路径上的时序关系。这将待分析设计中的输入路径限制为了5.3ns或更短。
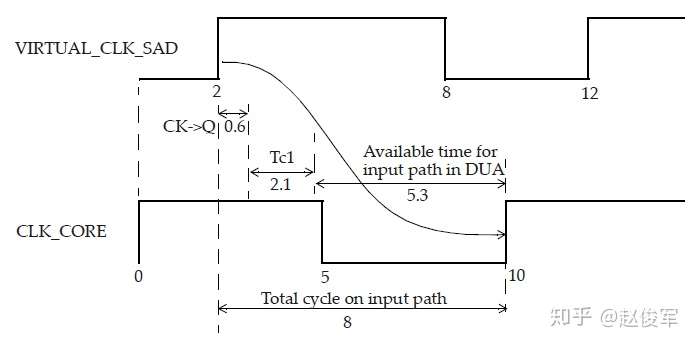
图7-35显示了输出路径上的时序关系。这将待分析设计中的输出路径限制为了3.5ns或更短。
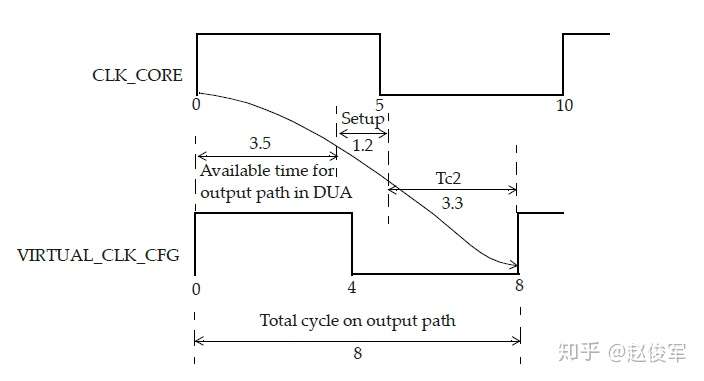
-min选项在set_input_delay和set_output_delay约束中指定时,可用于检查最小时序路径。使用虚拟时钟只是约束输入和输出(IO)的一种方法,设计人员还可以选择其它方法来约束IO。
完善时序分析
用于约束分析的四个常用命令是:
● set_case_analysis :在单元的引脚或输入端口上指定常量值。
● set_disable_timing :中断单元的时序弧。
● set_false_path :指定实际不存在的路径,这意味着在STA中不需要检查这些路径。
● set_multicycle_path :指定可能花费超过一个时钟周期的路径。
第8章将详细讨论set_false_path和set_multicycle_path约束。
指定无效信号
在设计中,某些信号在芯片的特定模式下会具有恒定值。例如,如果芯片中具有DFT(可测性设计)逻辑,则在正常功能模式下,芯片的TEST引脚将一直为0。为STA指定这样的常量值通常很有用,除了不必报告任何不相关的路径之外,这还有助于减少分析空间。例如,如果未将TEST引脚设置为常数,则可能会存在一些奇怪的长路径,而这些长路径在功能模式下永远不会存在。通过使用set_case_analysis约束来指定此类常数信号。
● set_case_analysis 0 TEST
● set_case_analysis 0 [get_ports {testmode[3]}]
● set_case_analysis 0 [get_ports {testmode[2]}]
● set_case_analysis 0 [get_ports {testmode[1]}]
● set_case_analysis 0 [get_ports {testmode[0]}]
如果设计具有多种功能模式,而只需要分析其中一种功能模式,则可以使用set_case_analysis来指定要分析的模式。
● set_case_analysis 1 func_mode[0]
● set_case_analysis 0 func_mode[1]
● set_case_analysis 1 func_mode[2]
注意,可以在设计中的任何引脚上指定set_case_analysis,这个命令的另一个常见应用是可以在多个时钟上运行的设计,并且时钟的适当选择由多路复用器控制。为了使STA分析更容易并减少CPU运行时间,对每个选择的时钟分别进行STA是十分有用的。图7-36给出了一个多路复用器选择不同时钟的示例:
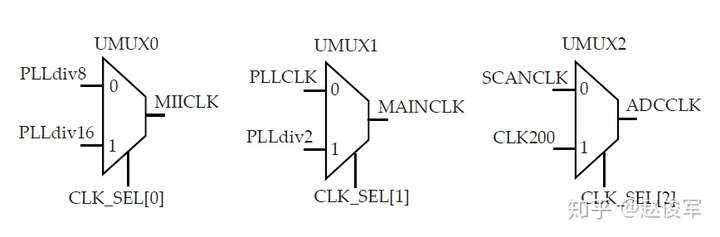
● set_case_analysis 1 UCORE/UMUX0/CLK_SEL[0]
● set_case_analysis 1 UCORE/UMUX1/CLK_SEL[1]
● set_case_analysis 0 UCORE/UMUX2/CLK_SEL[2]
第一个set_case_analysis选择了PLLdiv16被用于MIICLK,PLLdiv8的时钟路径被阻塞并且不会通过多路复用器传播。因此,没有使用时钟PLLdiv8分析任何时序路径(假设时钟在多路复用器之前不驱动任何触发器)。类似地,最后一个set_case_analysis选择了SCANCLK 被用于ADCCLK,并阻塞了CLK200的时钟路径。
中断单元内的时序弧
每个单元都有从其输入到输出的时序弧,并且时序路径可能会通过这些时序弧中的其中一个。在某些情况下,单元中的一条路径可能无法发生。例如可能有这样一种情况,其中时钟连接到多路复用器的选择端,而多路复用器的输出是数据路径的一部分。在这种情况下,中断多路复用器选择引脚和输出引脚之间的时序弧可能很有用。图7-37为一个示例,通过多路复用器选择端的路径不是有效的数据路径。可以使用set_disable_timing命令来中断这种时序弧。
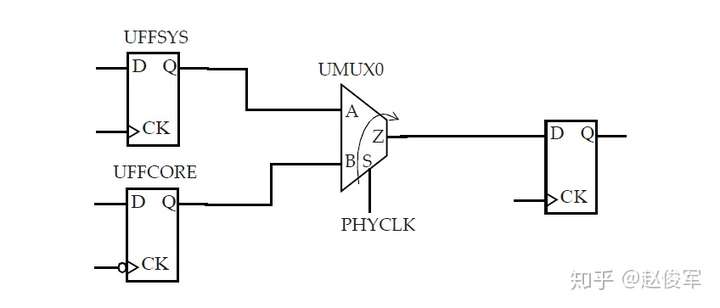
● set_disable_timing -from S -to Z [get_cells UMUX0]
由于时序弧不再存在,因此需要分析的时序路径更少。类似用法的另一个示例是取消触发器的最小时钟脉冲宽度检查。
使用set_disable_timing命令需要格外小心,因为它会删除通过指定引脚的所有时序路径。在可能的情况下,最好使用set_false_path和set_case_analysis命令。
点对点约束
可以通过使用set_min_delay和set_max_delay命令来约束点对点路径,这将引脚到引脚之间的路径延迟限制在了命令指定值内。该约束将覆盖所有默认的单周期时序路径以及此类路径的任何多周期路径约束。set_max_delay约束了指定路径的最大延迟,而set_min_delay约束了指定路径的最小延迟。
● set_max_delay 5.0 -to UFF0/D
● set_max_delay 0.6 -from UFF2/Q -to UFF3/D
● set_max_delay 0.45 -from UMUX0/Z -through UAND1/A -to UOR0/Z
● set_min_delay 0.15 -from {UAND0/A UXOR1/B} -to {UMUX2/SEL}
在上述示例中,需要注意的是,使用非标准的内部引脚将迫使它们成为起点和终点,并在这些点处分割路径。
还可以类似地指定从一个时钟到另一个时钟的点对点约束。
● set_max_delay 1.2 -from [get_clocks SYS_CLK] -to [get_clocks CFG_CLK]
● set_min_delay 0.4 -from [get_clocks SYS_CLK] -to [get_clocks CFG_CLK]
如果路径上有多个时序约束,例如时钟频率约束、set_max_delay和set_min_delay,则最严格的那个约束是始终用于检查的约束。多个时序约束可能是先应用某些全局(global)约束,然后再应用某些局部(local)约束。
路径分段
路径分段(path segmentation)是指将时序路径分解为可以进行时序分析的较小路径。
时序路径具有起点和终点,可以使用set_input_delay和set_output_delay命令在时序路径上创建其它起点和终点。通常在单元的输出引脚上指定set_input_delay来定义新起点,而通常在单元的输入引脚上指定set_output_delay来定义新终点。这些约束定义了新的时序路径,它是原始时序路径的子集。
考虑图7-38中所示的路径。为SYSCLK定义时钟后,待分析的时序路径即为从UFF0 / CK到UFF1 / D。如果仅对报告从UAND2 / Z到UAND6 / A的路径延迟感兴趣,则可以使用以下两个命令:
● set STARTPOINT [get_pins UAND2/Z]
● set ENDPOINT [get_pins UAND6/A]
● set_input_delay 0 $STARTPOINT
● set_output_delay 0 $ENDPOINT
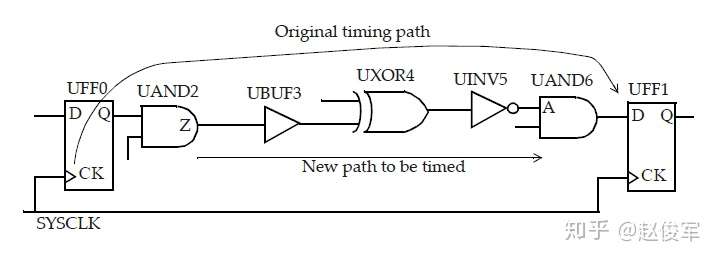
定义这些约束会导致从UFF0 / CK到UFF1 / D的原始时序路径被分段,并分别在UAND2 / Z和UAND6 / A处创建内部起点和内部终点。现在,时序报告将明确显示此新路径。请注意,还会自动创建另外两条时序路径,一条从UFF0 / CK到UAND2 / Z,另一条从UAND6 / A到UFF1 / D。因此,原始的时序路径已被分为了三个部分,每个部分分别进行时序分析。
set_disable_timing、set_max_delay和set_min_delay命令也会对时序路径进行分段。
时序检查
本章节将介绍静态时序分析所执行的一部分检查,这些检查旨在详尽地验证待分析设计的时序。
● 两项主要的检查是建立时间和保持时间检查。一旦在触发器的时钟引脚上定义了时钟,便会自动推断出该触发器的建立时间和保持时间检查。时序检查通常会在多个条件下执行,包括最差情况的慢速条件和最佳情况的快速条件。通常,最差情况的慢速条件对于建立时间检查很关键,而最佳情况的快速条件对于保持时间检查很关键(尽管也可以在最差情况的慢速条件下执行保持时间检查)。
● 本章节中的示例假定网络延迟为零,这样做是为了简化说明,并且不会更改所介绍的概念。
建立时间检查
建立时间检查会验证触发器时钟和数据引脚之间的时序关系,从而满足建立时间要求。换句话说,建立时间检查会确保在触发器输入时钟之前,数据在触发器的输入端可用。在时钟的有效沿到达触发器之前,数据应在一定时间内保持稳定,即触发器的建立时间,该要求将确保数据可靠地被捕获到触发器中。图8-1显示了典型触发器的建立时间要求,建立时间检查将验证触发器的建立时间要求。
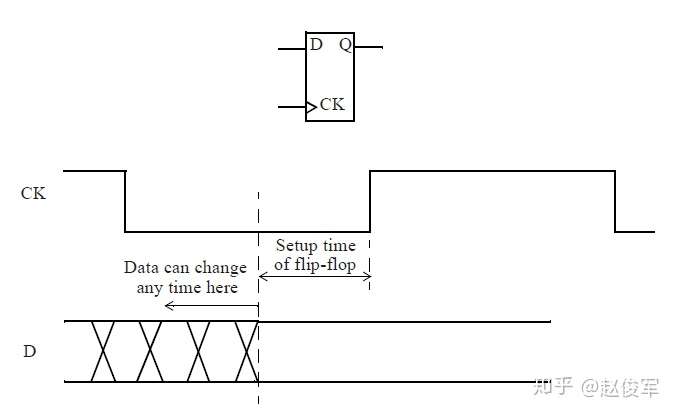
通常,有一个发起触发器(用于发起数据的触发器)和捕获触发器(用于捕获数据的触发器),这个捕获触发器的建立时间要求必须满足。建立时间检查将验证从发起触发器到捕获触发器的最长(或最大)路径,这两个触发器的时钟可以相同也可以不同。建立时间检查是从发起触发器中时钟的第一个有效沿到捕获触发器中时钟后面最接近的那个有效沿。建立时间检查将确保上一个时钟周期发起的数据准备好在一个周期后被捕获。
现在我们研究一个简单的示例,如图8-2所示,其中发起触发器和捕获触发器具有相同的时钟。时钟CLKM的第一个上升沿在Tlaunch时间后出现在发起触发器的时钟引脚上,由该时钟沿发起的数据出现在触发器UFF1的D引脚的所需时间为Tlaunch + Tck2q + Tdp。时钟CLKM的第二个上升沿(通常在一个周期后检查建立时间)出现在捕获触发器UFF1的时钟引脚上的时间为Tcycle + Tcapture。这两个时间之差必须大于触发器UFF1的建立时间要求,以确保触发器UFF1可靠地捕获数据。
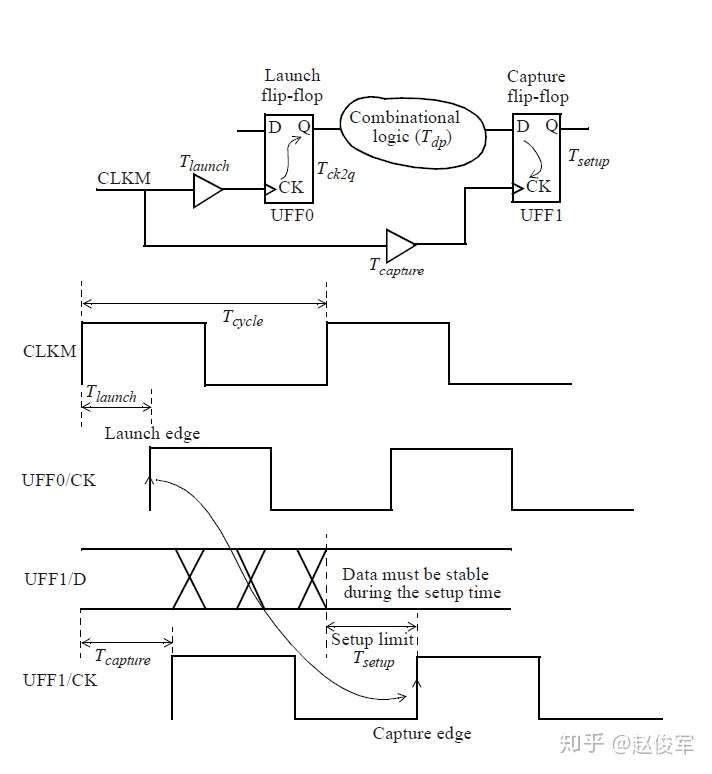
建立时间检查可以用数学公式表示:
● Tlaunch + Tck2q + Tdp < Tcapture + Tcycle - Tsetup
其中Tlaunch是发起触发器UFF0的时钟树延迟,Tdp是组合逻辑数据路径的延迟,Tcycle是时钟周期,Tcapture是捕获触发器UFF1的时钟树延迟。
换句话说,数据到达捕获触发器D引脚所花费的总时间必须小于时钟传输到捕获触发器所花费的时间加上时钟周期再减去建立时间要求。
由于建立时间检查受到-max的约束,因此建立时间检查始终使用最长或最大的时序路径。出于同样的原因,通常在延迟最大的慢工艺角(slow corner)下执行建立时间检查。
触发器到触发器路径
以下是一份建立时间检查的路径报告:
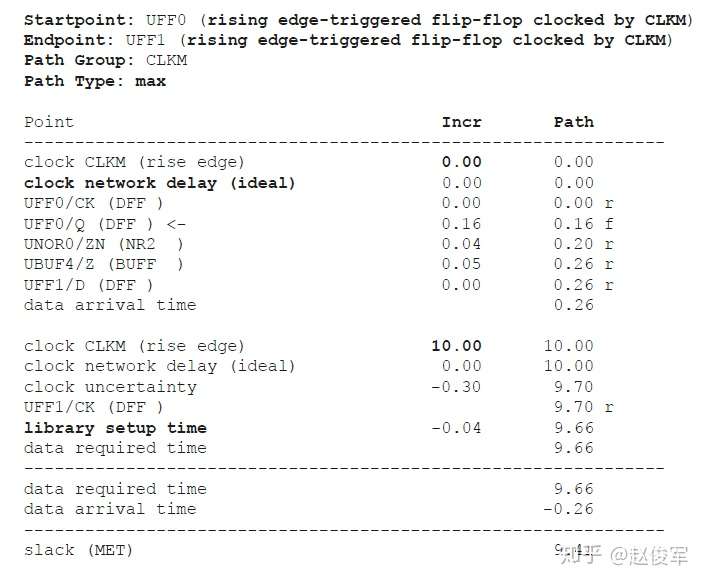
该报告中显示发起触发器(由Startpoint指定)的实例名称为UFF0,由时钟CLKM的上升沿触发。捕获触发器(由Endpoint指定)为UFF1,也由时钟CLKM的上升沿触发。路径组(Path Group)显示它属于路径组CLKM。如上一章所述,设计中的所有路径都基于捕获触发器的时钟归类为路径组。路径类型(Path Type)显示此报告中的延迟均为最大路径延迟,表明这是建立时间检查。这是因为建立时间检查对应于通过逻辑的最大(或最长路径)延迟。注意,保持时间检查对应于通过逻辑的最小(或最短路径)延迟。
Incr列显示了指定端口或引脚的单元或网络延迟增量,Path列显示了数据实际到达和需要到达的路径累积延迟,这是用于此示例的时钟约束:
● create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM]
● set_clock_uncertainty -setup 0.3 [all_clocks]
● set_clock_transition -rise 0.2 [all_clocks]
● set_clock_transition -fall 0.15 [all_clocks]
数据发起路径需要0.26ns的延迟才能到达触发器UFF1的D引脚,这是捕获触发器输入端的到达时间。捕获边沿(建立时间检查时为一个周期)为10ns,为此时钟指定了0.3ns的时钟不确定度(clock uncertainty),因此,有效时钟周期由于不确定度而减少了0.3ns。时钟不确定度包括由于时钟源抖动引起的周期变化以及用于分析的任何其它时序裕量。从总的捕获路径中还要减去触发器的建立时间0.04ns(library setup time),得出数据需要到达的时间为9.66ns。由于数据实际到达时间为0.26ns,因此在此时序路径上有9.41ns的正裕量(slack)。请注意,所需到达时间和实际到达时间之差可能看起来是9.40ns,但是实际值是出现在报告中的9.41ns。之所以存在差异,是因为报表仅显示小数点后两位数字,而内部计算和存储的值比所报告的精度更高。
时序报告中的时钟网络延迟(clock network delay)是什么?为什么将其标记为理想(ideal)?时序报告中的这一行表明时钟树被认为是理想的,时钟路径中的任何缓冲器(buffer)都假定为零延迟。一旦构建了时钟树,就可以将时钟网络标记为“已传播”(propagated),从而使得时钟路径显示实际延迟值,如下一个示例时序报告中所示:0.11ns延迟是发起时钟上的时钟网络延迟,而0.12ns延迟是捕获触发器上的时钟网络延迟。
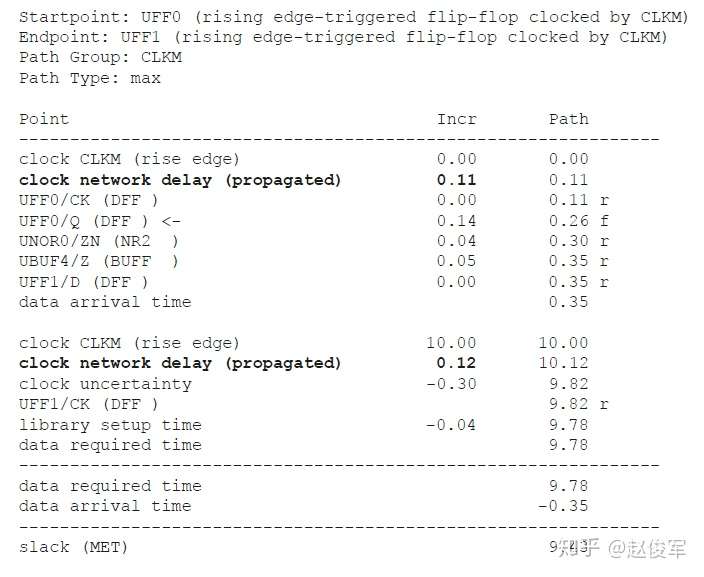
时序路径报告中可以选择包含扩展的时钟路径,即带有明确显示的时钟树。以下是一个例子:
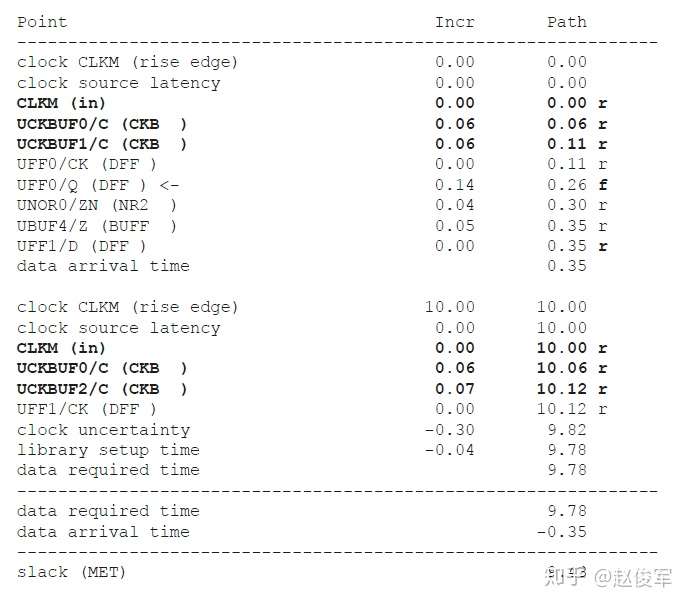
请注意,上述路径报告中的UCKBUF0、UCKBUF1和UCKBUF2都是时钟缓冲器,提供了有关如何计算时钟树延迟的详细信息。
如何计算第一个时钟单元UCKBUF0的延迟呢?如前几章所述,单元延迟是根据单元的输入过渡时间和输出电容来计算的。因此,问题是在时钟树的第一个单元的输入处指定了多大的过渡时间,可以使用set_input_transition命令明确指定第一个时钟单元输入引脚上的过渡时间(或压摆)。
● set_input_transition -rise 0.3 [get_ports CLKM]
● set_input_transition -fall 0.45 [get_ports CLKM]
在上述的set_input_transition命令中,我们将输入上升过渡时间指定为了0.3ns,将下降过渡时间指定为了0.45ns。在没有该命令约束的情况下,将在时钟树的源端假设存在理想的压摆,这意味着上升和下降过渡时间均为0ns。
时序报告中的r和f字符表示时钟或数据信号的上升沿(和下降沿)。上一个时序路径报告中显示了一条从UFF0 / Q的下降沿开始到UFF1 / D的上升沿结束的路径。由于UFF1 / D可以为0或1,因此也可以有一条路径在UFF1 / D的下降沿结束。以下就是这样一条路径:
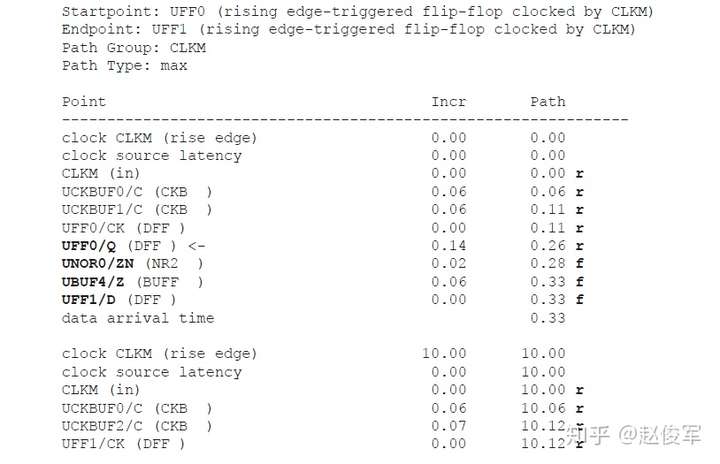

注意,触发器时钟引脚的边沿(称为有效边沿)保持不变。它只能是上升或下降有效沿,具体取决于触发器是由上升沿触发的还是由下降沿触发的。
什么是时钟源延迟(clock source latency)? 这也被称为插入延迟(insertion delay),是时钟从其源端传播到待分析设计的时钟定义点所花费的时间,如图8-3所示,这对应于设计之外的时钟树延迟。例如,如果该设计是较大模块的一部分,则时钟源延迟是指直到待分析设计时钟引脚为止的时钟树延迟。可以使用set_clock_latency命令明确指定此延迟。
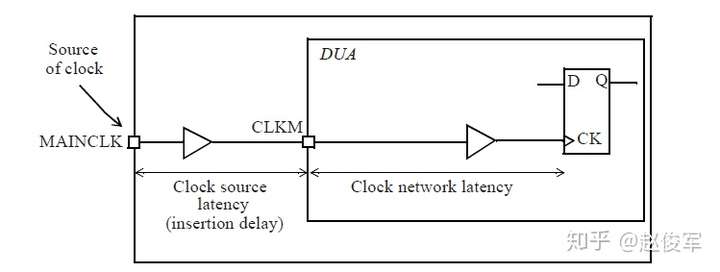
● set_clock_latency -source -rise 0.7 [get_clocks CLKM]
● set_clock_latency -source -fall 0.65 [get_clocks CLKM]
在没有上述命令的情况下,将假定延迟为0,这是早期路径报告中使用的假设。请注意,源延迟不会影响设计内部的路径,并且它们具有相同的发起时钟和捕获时钟,这是因为发起时钟路径和捕获时钟路径都会加上一段相同的延迟。但是,这种延迟确实会影响经过待分析设计输入和输出的时序路径。
如果没有-source选项,则set_clock_latency命令将定义时钟网络延迟,这是从DUA中时钟定义点到触发器的时钟引脚的延迟。时钟网络延迟用于在建立时钟树之前(即在时钟树综合之前)对通过时钟路径的延迟进行建模。一旦建立了时钟树并标记为了“已传播”(propagated),便会忽略此时钟网络延迟约束。set_clock_latency命令也可用于对从主时钟到其衍生时钟的延迟进行建模,如7.3节所述。当时钟生成逻辑不是设计的一部分时,该命令也可用于建模片外时钟延迟。
输入到触发器路径
以下是一个通过输入端口到触发器的路径报告示例,图8-4给出了与输入路径有关的原理图和时钟波形。

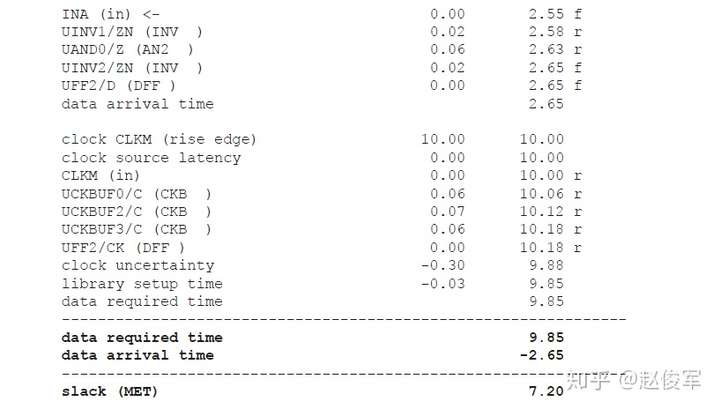
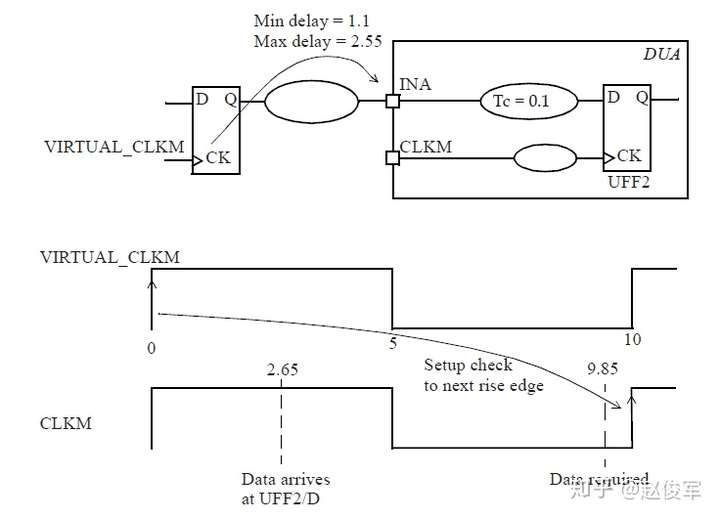
首先要注意的是第一行中的input port clocked by VIRTUAL_CLKM。如7.9节中所述,该时钟可以被认为是驱动设计输入端口INA的虚拟触发器,该虚拟触发器的时钟为VIRTUAL_CLKM。此外,从该虚拟触发器的时钟引脚到输入端口INA的最大延迟指定为2.55ns,在报告中显示为input external delay。可以使用以下SDC命令指定这些参数:
● create_clock -name VIRTUAL_CLKM -period 10 -waveform {0 5}
● set_input_delay -clock VIRTUAL_CLKM -max 2.55 [get_ports INA]
请注意,虚拟时钟VIRTUAL_CLKM的定义没有与设计中任何引脚相关,这是因为它是在设计之外定义的(它是虚拟的)。输入延迟约束set_input_delay指定了相对于虚拟时钟的延迟。
输入路径从端口INA开始,如何计算连接到端口INA的第一个单元UINV1的延迟呢?一种方法是指定输入端口INA的驱动单元,该驱动单元用于确定驱动强度,从而确定端口INA上的压摆,然后用于计算单元UINV1的延迟。在输入端口INA上没有任何压摆约束的情况下,将假定端口上的过渡是理想的,即过渡时间为0ns。
● set_driving_cell -lib_cell BUFF -library lib0131wc [get_ports INA]
图8-4还展示了如何进行建立时间检查。数据必须到达UFF2 / D的时间为9.85ns,但是数据实际到达的时间为2.65ns,因此该报告显示该路径的正裕量为7.2ns。
具有实际时钟的输入路径
输入延迟也可以相对于实际时钟来指定,并不一定必须相对于虚拟时钟来指定。实际时钟可以是设计中的内部引脚或者输入端口上的时钟,图8-5描绘了一个示例,其中相对于输入端口CLKP上的时钟指定了端口CIN上的输入延迟约束。此延迟约束为:
● set_input_delay -clock CLKP -max 4.3 [get_ports CIN]
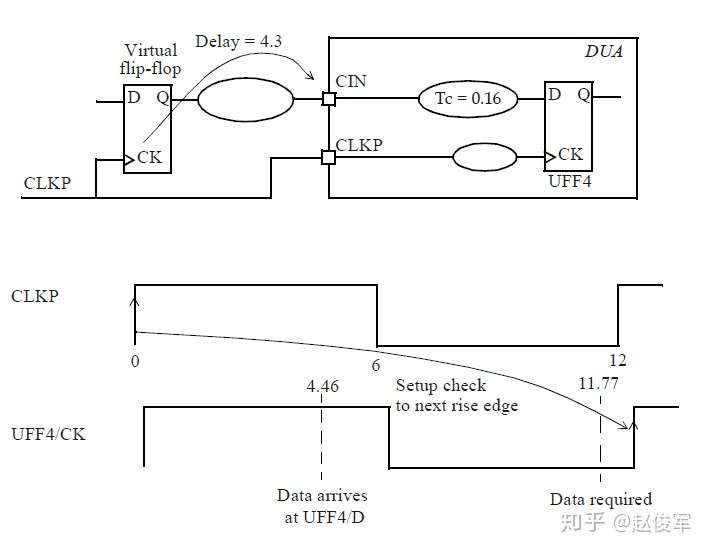
以下是与此约束相对应的输入路径时序报告:
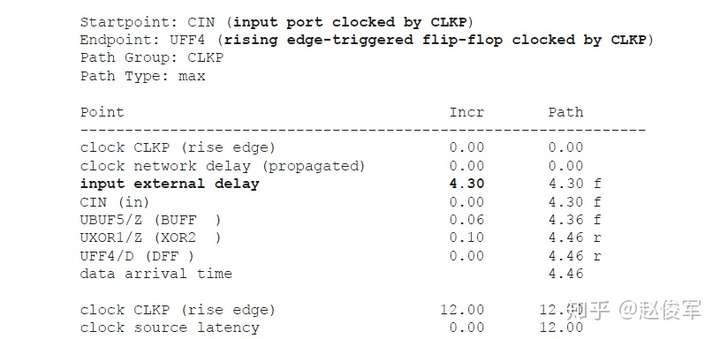

请注意,起始点(Startpoint)与预期一致,将输入端口的延迟参考时钟指定为了CLKP。
触发器到输出路径
与上述输入端口约束类似,可以相对于虚拟时钟或设计中的内部时钟来约束输出端口,或者可以相对于实际的输入时钟端口或输出时钟端口来约束输出端口。以下是一个示例,相对于虚拟时钟约束了输出引脚ROUT,输出约束如下:
● set_output_delay -clock VIRTUAL_CLKP -max 5.1 [get_ports ROUT]
● set_load 0.02 [get_ports ROUT]
为了确定最后一个单元连接到输出端口的延迟,需要指定该端口上的负载,上面使用了set_load命令来指定输出负载。请注意,端口ROUT可能在DUA内部具有负载,而set_load约束指定的是额外的负载,即来自DUA外部的负载。在没有set_load命令约束的情况下,将假定外部负载的值为0(这可能不现实,因为该设计很可能会在其它设计中使用)。下图8-6显示了具有虚拟时钟的虚拟触发器的时序路径:
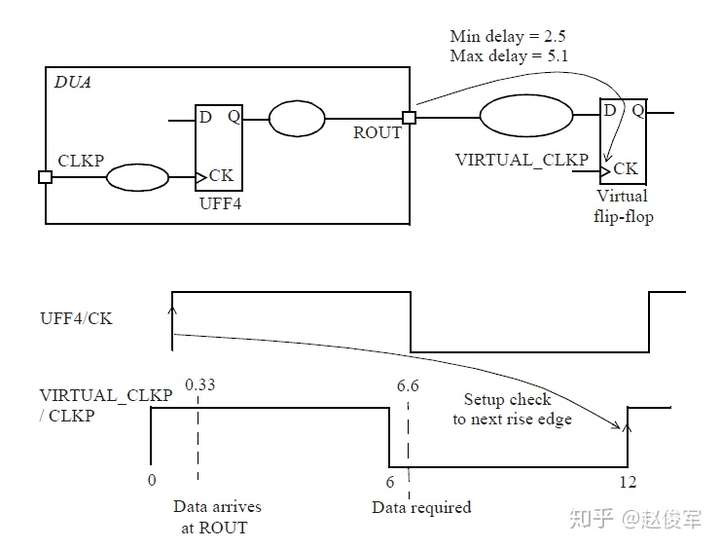
以下是通过该输出端口的时序路径报告:
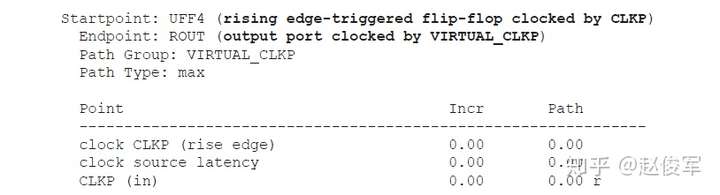


注意,指定的输出延迟在报告中显示为output external delay,其作用类似于虚拟触发器所需的建立时间。
输入到输出路径
设计也可以具有从输入端口到输出端口的纯组合逻辑路径。可以像我们前面看到的输入和输出路径一样,对路径进行约束和时序分析。下图8-7显示了这种路径的一个示例,虚拟时钟同时用于指定输入和输出端口上的约束,以下是输入和输出延迟约束:
● set_input_delay -clock VIRTUAL_CLKM -max 3.6 [get_ports INB]
● set_output_delay -clock VIRTUAL_CLKM -max 5.8 [get_ports POUT]
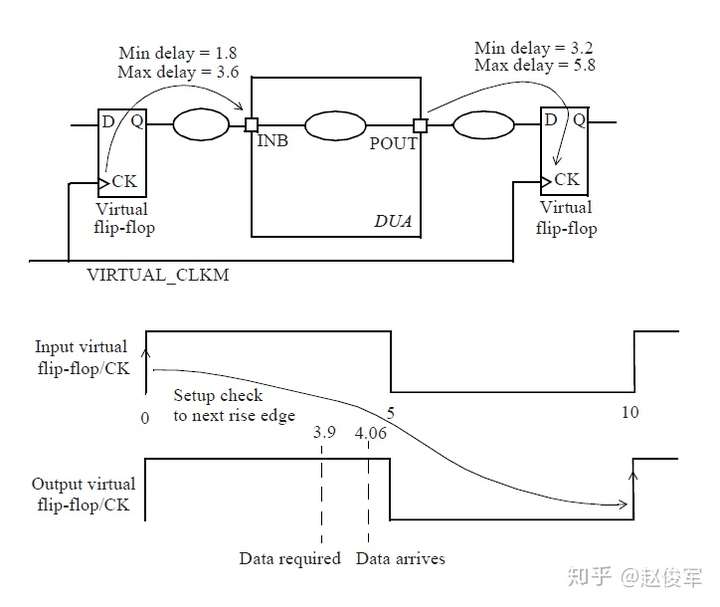
以下是一个时序路径报告,它经过从输入INB到输出POUT的组合逻辑。请注意,任何内部时钟延迟(如果存在)都不会对该路径报告产生影响。



频率直方图
如果要绘制一个典型设计的建立时间裕量与路径数的频率直方图,则如图8-8所示。根据设计的状态(是否进行了优化) ,对于未优化的设计,零裕量(zero slack)线将更靠近右侧,而对于优化后的设计则更趋向于左侧。对于没有时序违例的设计(即没有路径的裕度为负),整个曲线将在零裕量线的右侧。
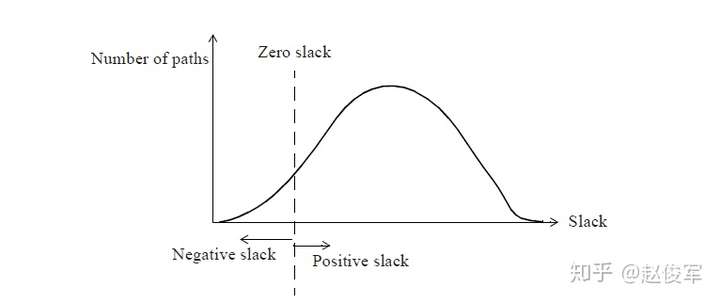
以下是以文本形式显示的直方图,通常可以由静态时序分析工具生成:

前两个索引表示裕量的范围,第三个索引是该裕量范围内的路径数,例如,有941条路径的裕量范围为410ps至415ps。直方图表明该设计没有时序违例的路径,即所有路径均具有正的裕量,而关键路径的裕量值在375ps至380ps之间。
难以满足时序要求的设计会使直方图的驼峰向左偏大,也就是说,许多路径的裕量值接近于零。通过观察频率直方图可以得出的另一结果是:可以进一步优化设计以实现零裕量的可能性,即时序收敛有多困难。如果违例路径的数量少并且负裕量值也很小,则设计相对比较容易满足所需的时序。但是,如果违例路径的数量很大并且负裕量值也很大,则这意味着设计将需要付出很大努力才能满足所需的时序。
保持时间检查
保持时间检查可确保正在变化的触发器输出值不会传递到捕获触发器、并在捕获触发器有机会捕获其原始值之前重写(overwrite)其输出。该检查基于触发器的保持时间要求,触发器的保持时间要求规定在时钟的有效沿之后的指定时间段内,被锁存的数据应保持稳定。图8-9给出了典型触发器的保持时间要求:
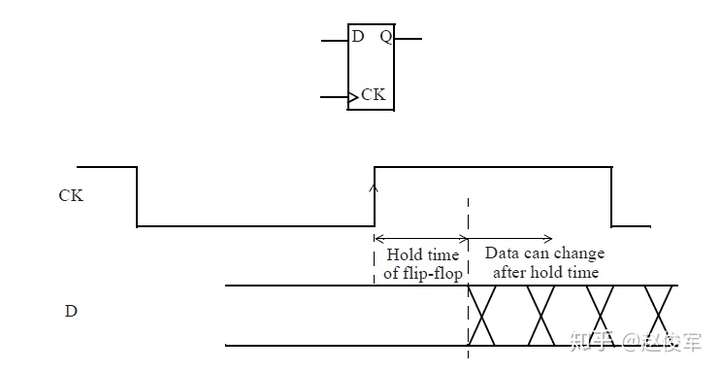
就像建立时间检查一样,是在发起触发器(发起数据的触发器)和捕获触发器(捕获数据的触发器以及必须满足其保持时间要求的触发器)之间进行保持时间检查的。这两个触发器的时钟可以相同也可以不同,保持时间检查从发起触发器时钟的一个有效沿到捕获触发器中相同的时钟沿。因此,保持时间检查与时钟周期无关,保持时间检查会在捕获触发器时钟的每个有效沿上执行。
现在我们来看一个简单的示例,如图8-10所示,其中发起触发器和捕获触发器具有相同的时钟。
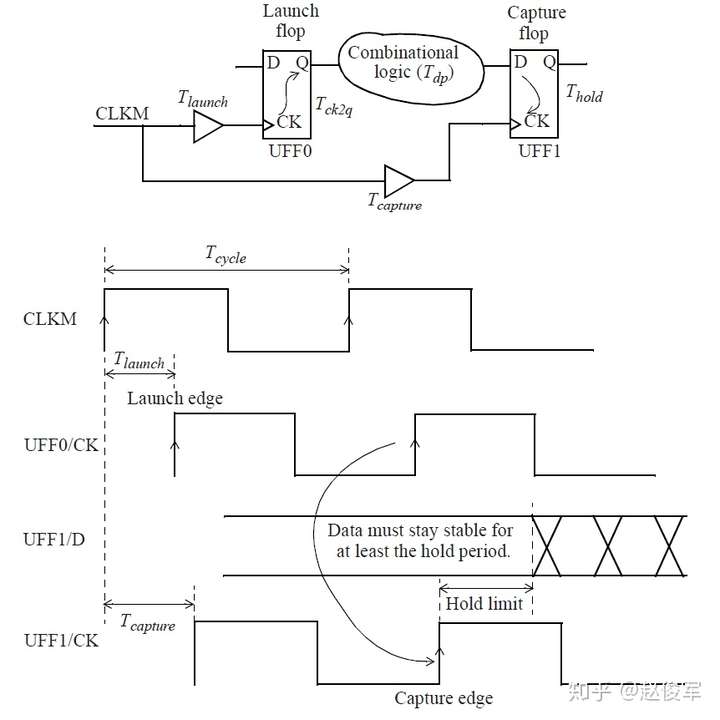
考虑时钟CLKM的第二个上升沿。时钟上升沿发起的数据需要Tlaunch + Tck2q + Tdp时间到达捕获触发器UFF1的D引脚。时钟的同一边沿需要Tcapture时间才能到达捕获触发器的时钟引脚,目的是使捕获触发器在下一个时钟周期捕获来自发起触发器的数据。如果在同一时钟周期内捕获数据,则捕获触发器中的预期数据(来自上一个时钟周期)将被覆盖,因此保持时间检查旨在确保捕获触发器中的目标数据不会被覆盖。保持时间检查可验证这两个时间之差(捕获触发器的数据到达时间和时钟到达时间)必须大于捕获触发器的保持时间,这样触发器上的数据才不会被覆盖,并且捕获到可靠的数据。
保持时间检查可以用数学公式表示为:
● Tlaunch + Tck2q + Tdp > Tcapture + Thold
其中Tlaunch是发起触发器的时钟树延迟,Tdp是组合逻辑数据路径中的延迟,Tcapture是捕获触发器的时钟树延迟。换句话说,由时钟边沿发起的数据到达捕获触发器D引脚所需的总时间必须大于时钟同一边沿到达捕获触发器所需的时间加上保持时间。这样可以确保UFF1 / D保持稳定状态,直到触发器的时钟引脚UFF1 / CK时钟上升沿之后的保持时间为止。
保持时间检查对捕获触发器的数据路径施加了最小值(-min)约束,需要确定到捕获触发器D引脚的最快路径。这意味着将始终使用最短时序路径来进行保持时间检查,同样,通常在快速工艺角下进行保持时间检查。
即使设计中只有一个时钟,时钟树也会导致时钟在发起触发器和捕获触发器处的到达时间大不相同。为了确保可靠的数据捕获,捕获触发器的时钟沿必须在数据可改变之前到达。保持时间检查可确保(见图8-11):
● 当前数据发起时钟沿(Setup launch edge)的下一个(subsequent)时钟沿发起的数据不被当前数据捕获时钟沿(Setup receiving edge)所捕获。
● 当前数据发起时钟沿发起的数据不被当前数据捕获时钟沿的前一个(Preceding)时钟沿所捕获。
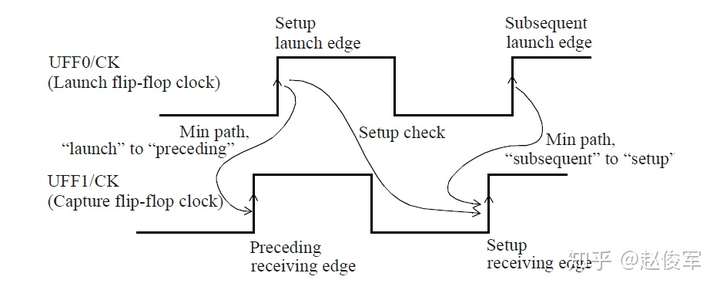
如果发起时钟和捕获时钟都属于同一时钟域,则这两个保持时间检查实质上是相同的。但是,当发起时钟和捕获时钟处于不同频率或处于不同时钟域时,以上两个保持时间检查就有可能是不同的。在这种情况下,最差的保持时间检查就是所要报告的检查。上图8-11说明了这两个保持时间检查。
UFF0是发起触发器,UFF1是捕获触发器。建立时间检查在这一个数据发起时钟沿(Setup launch edge)和这一个数据捕获时钟沿(Setup receiving edge)之间。下一个数据发起时钟沿(Subsequent launch edge)不得以太快的速度传播数据,因为这可能会导致这一个数据捕获时钟沿没有时间可靠地捕获这一个数据。此外,这一个数据发起时钟沿同样不得以太快的速度传播数据,因为这可能会导致前一个数据捕获时钟沿(Preceding receiving edge)没有时间可靠地捕获前一个数据。在上述各种情况中,最差情况的保持时间检查对应于最严格的保持时间检查。
稍后将在8.3节和8.8节中分别讨论更通用的时钟,例如用于多周期路径和多频率路径的时钟。讨论内容将涵盖建立时间检查和保持时间检查之间的关系,尤其是如何从建立时间检查中推断出保持时间检查。虽然建立时间违例会导致设计的工作频率降低,但保持时间违例会“杀死”(kill)设计,即设计在任何频率下都无法运行。因此,了解保持时间检查并解决任何违例行为非常重要。
触发器到触发器路径
本小节将基于图8-2中示例说明触发器到触发器的保持时间路径。以下是一份保持时间检查的路径报告,该示例来自8.1节中的建立时间检查路径。
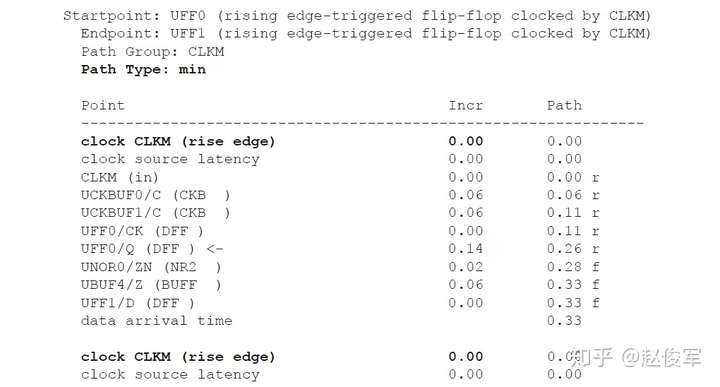

注意,路径类型(Path Type)为最小值(min),表示使用了最短路径的单元延迟值,这对应于保持时间检查。库保持时间(library hold time)指定了触发器UFF1的保持时间。如前3.4节所述,触发器的保持时间也可以为负。请注意,发起和捕获路径都是从时钟CLKM的上升沿(触发器的有效沿)开始计算的。时序报告显示,新数据最早可以到达UFF1、同时又可以安全地捕获上一个时钟周期数据的时间为0.19ns。由于新数据的实际到达时间为0.33ns,因此报告显示正的保持时间裕量(slack)为0.14ns。
图8-12显示了时钟信号到达发起和捕获触发器时钟引脚的时间,以及数据在捕获触发器处的最早允许到达时间和实际到达时间。由于数据实际到达的时间晚于数据所需到达的时间(允许的最早到达时间),因此满足保持时间要求。
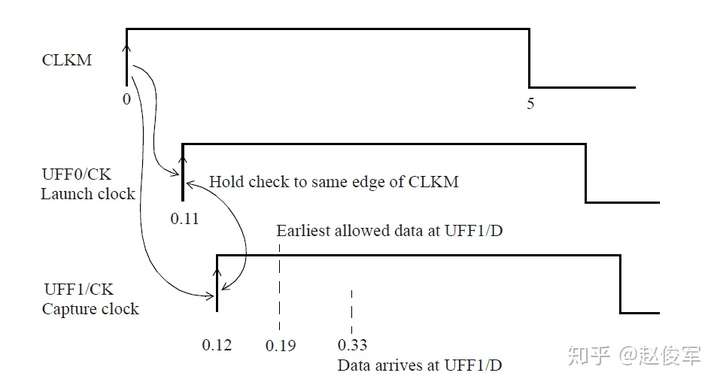
保持时间裕量计算
需要注意的一点是,为建立时间和保持时间的时序报告计算裕量值的方式有所不同。在建立时间报告中,会计算数据实际到达时间和数据需要到达时间,然后将需要到达时间减去实际到达时间,从而得到建立时间的裕量值。但是,在保持时间报告中,当我们把需要到达时间减去实际到达时间后,负的结果将转化为正的裕量值(表示满足保持时间要求),而正的结果将转化为负的裕量值(表示保持时间违例)。
输入到触发器路径
接下来介绍输入端口的保持时间检查。有关示例,请参见图8-4。使用虚拟时钟将输入端口上的最小延迟指定为:
● set_input_delay -clock VIRTUAL_CLKM -min 1.1 [get_ports INA]
以下是一份保持时间检查的路径报告:

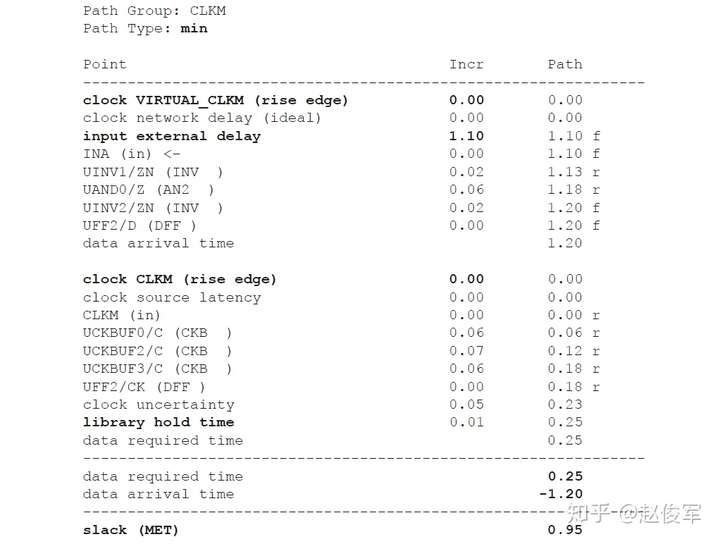
input external delay中的值为输入延迟约束命令中的指定值。在0时刻的VIRTUAL_CLKM上升沿和CLKM上升沿之间进行保持时间检查。UFF2在不违反其保持时间的情况下捕获数据所需的到达时间为0.25ns,这表明数据应在0.25ns之后到达。由于数据实际上在1.2ns才到达,因此显示出0.95ns的正裕量。
触发器到输出路径
这小节将介绍输出端口上的保持时间检查。示例见图8-6,输出端口延迟约束为:
● set_output_delay -clock VIRTUAL_CLKP -min 2.5 [get_ports ROUT]
输出延迟也是相对于虚拟时钟指定的,这是另一份保持时间检查的路径报告:
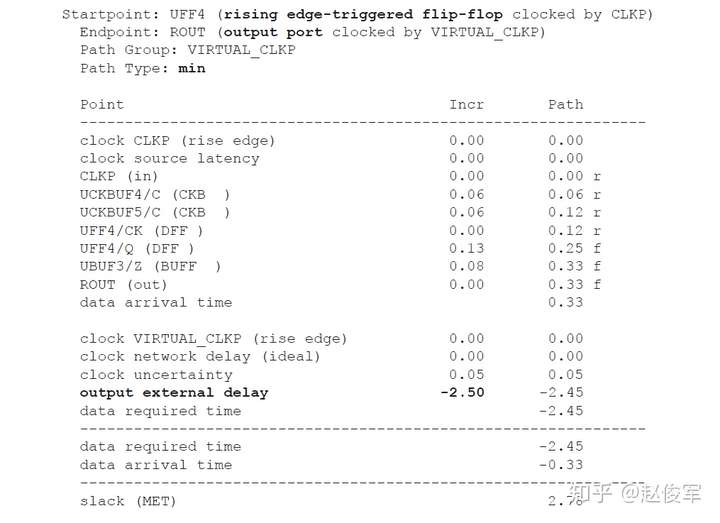
请注意,output external delay中的值为输出延迟约束命令中的指定值。
具有实际时钟的触发器到输出路径
有一条输出端口保持时间检查的路径,如图8-13所示。请注意,最小输出延迟是相对于实际时钟指定的。
● set_output_delay -clock CLKP -min 3.5 [get_ports QOUT]
● set_load 0.55 [get_ports QOUT]
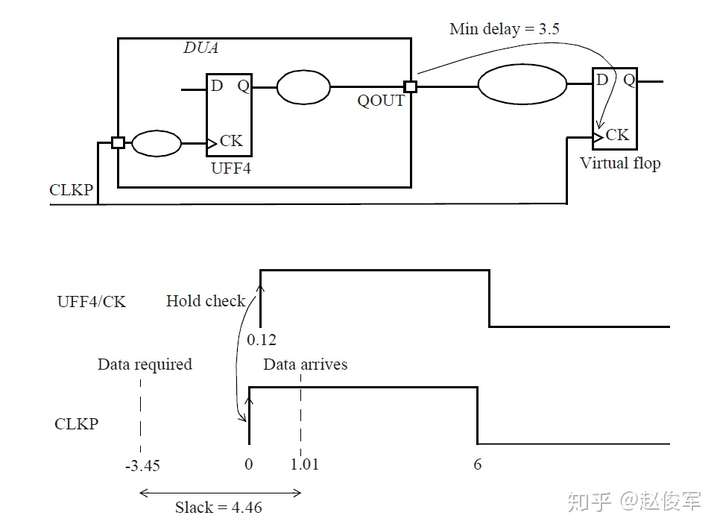
以下是保持时间报告:
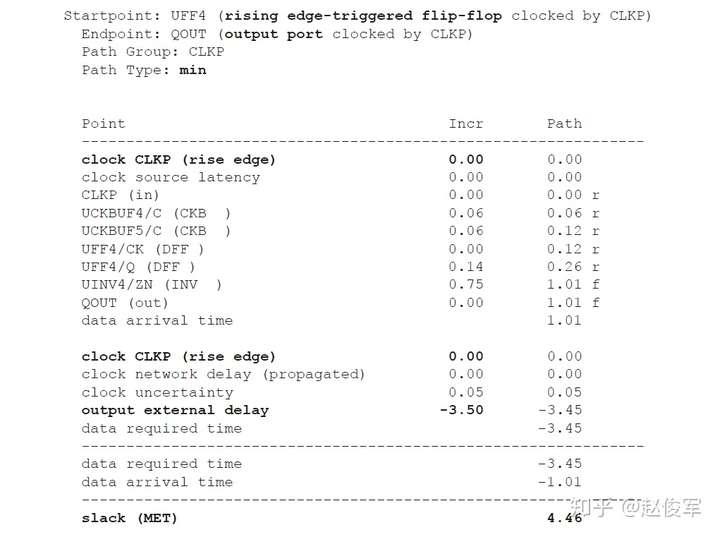
保持时间检查是在时钟CLKP的上升沿(触发器的有效沿)处执行的。以上报告表明,这条触发器到输出的路径保持时间的正裕量为4.46ns。
输入到输出路径
这是对输入到输出路径的保持时间检查,如图8-7所示。端口的约束为:
● set_load -pin_load 0.15 [get_ports POUT]
● set_output_delay -clock VIRTUAL_CLKM -min 3.2 [get_ports POUT]
● set_input_delay -clock VIRTUAL_CLKM -min 1.8 [get_ports INB]
● set_input_transition 0.8 [get_ports INB]
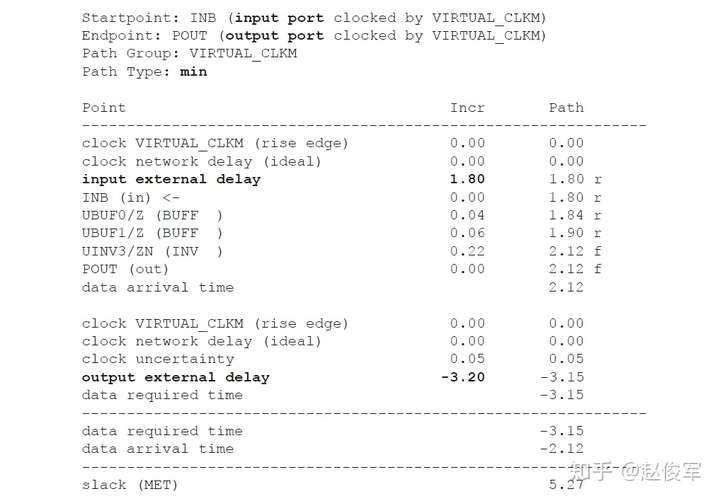
输入端口和输出端口上的延迟约束是相对于虚拟时钟指定的,因此,保持时间检查是在该虚拟时钟的上升沿(有效沿)处执行的。
多周期路径
在某些情况下,两个触发器之间的数据路径可能需要一个以上的时钟周期才能传播通过逻辑。在这种情况下,这条组合逻辑路径会被定义为多周期路径(multicycle path)。虽然数据还是会在每个时钟沿上都被捕获触发器捕获,但我们需要告知STA在指定数量的时钟周期之后才会出现有效的捕获时钟沿。
图8-14是一个示例。由于数据路径最多需要三个时钟周期,因此应指定三个周期的多周期建立时间检查。为此需要指定如下的多周期建立时间约束:
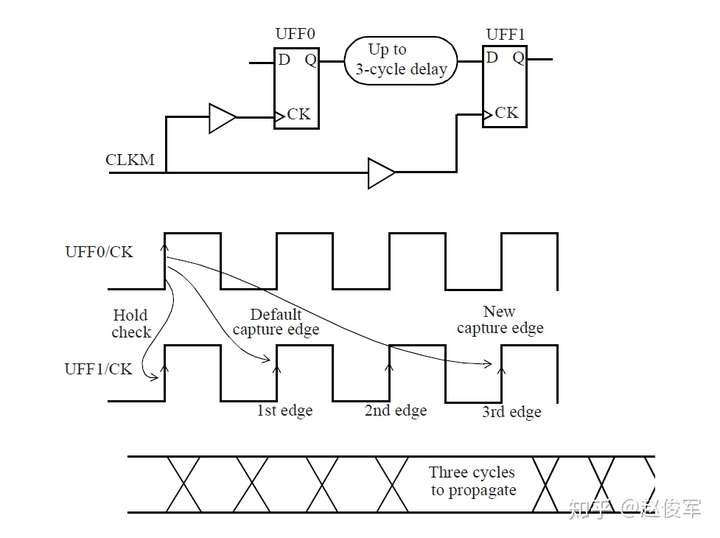
● create_clock -name CLKM -period 10 [get_ports CLKM]
● set_multicycle_path 3 -setup -from [get_pins UFF0/Q] -to [get_pins UFF1/D]
多周期建立时间约束规定,建立时间检查时从UFF0 / CK到UFF1 / D的路径最多可以花费三个时钟周期,这意味着设计每三个周期才会使用一次UFF1 / Q引脚上输出的数据,而不是每个周期都使用。
以下是一份具有多周期约束的建立时间路径报告:



注意,现在捕获触发器的时钟沿距离发起触发器的时钟沿三个时钟周期,为30ns。
现在,我们来检查一下多周期路径上的保持时间检查。在最常见的情况下,我们希望保持时间检查保持不变(与单周期路径一致),如图8-14所示,这样可使数据在三个时钟周期之内任意进行改变。只有指定多周期保持时间为2,才可以获得与单周期建立时间检查情况相同的保持时间检查。这是因为在没有这样的多周期保持时间约束的情况下,默认的保持时间检查是在建立时间捕获沿的前一个有效时钟沿上执行的,这显然不是我们希望的。我们需要将执行保持时间检查的时钟沿移动到默认时钟沿之前的两个周期,因此指定了多周期保持时间为2。预期的检查如图8-15所示,通过多周期保持时间约束,数据路径的最小延迟可以小于一个时钟周期。
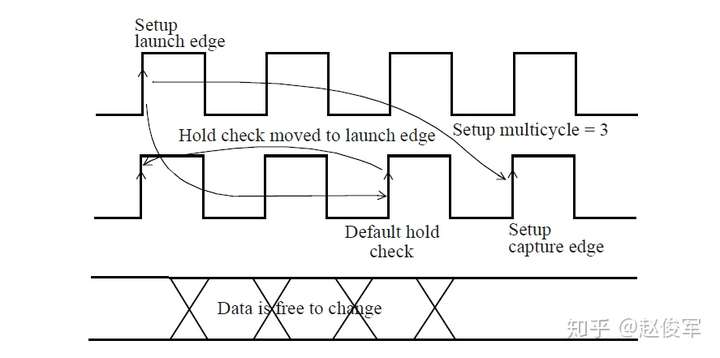
● set_multicycle_path 2 -hold -from [get_pins UFF0/Q] -to [get_pins UFF1/D]
多周期保持时间约束命令中的周期数指定了从默认保持时间检查沿(建立时间捕获沿之前的一个有效沿)需要移回多少个时钟周期。 以下是一份保持时间检查的路径报告:


由于此路径的多周期建立时间约束为3,因此其默认保持时间检查是在建立时间捕获沿之前的有效时钟沿上执行的。在大多数设计中,如果最大路径(或建立时间)需要N个时钟周期,则大于(N-1)个时钟周期的最小路径约束是不可行的。通过指定两个周期的多周期保持时间约束,可以将保持时间检查时钟沿移回到数据发起沿处(即0ns处),如上面的路径报告中所示。
因此在大多数设计中,指定为N(周期)的多周期建立时间约束应伴随着指定为N-1(周期)的多周期保持时间约束。
如果指定了N个周期的多周期建立时间约束,但缺少了相应的N-1个周期的多周期保持时间约束,会发生什么情况呢?在这种情况下,会在建立时间捕获沿之前的一个周期时钟沿上执行保持时间检查。图8-16显示了仅约束多周期建立时间为3个周期时,进行这种保持时间检查的情况。
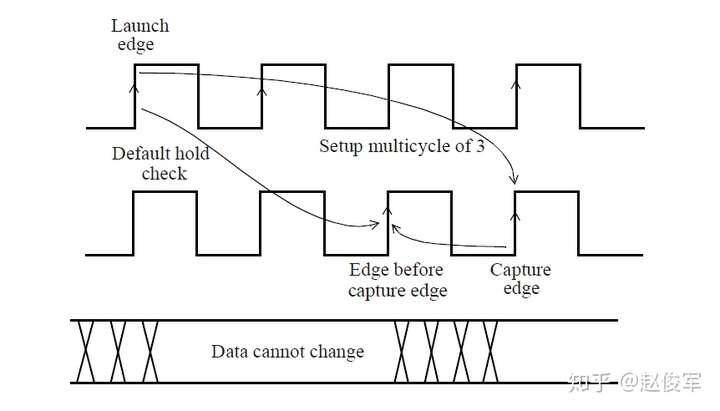
如图所示,这规定了数据只能在建立时间捕获沿之前的一个周期内进行改变。因此,数据路径必须具有至少两个时钟周期的最小延迟才能满足此要求。以下是这种情况的路径报告:


从路径报告中注意到,在捕获沿之前的一个时钟沿对保持时间进行了检查,这导致了较大的保持时间违例。实际上,该保持时间检查将要求组合逻辑中的最小延迟至少为两个时钟周期。
跨时钟域
让我们考虑在周期相同的两个不同时钟之间存在多周期路径的情况。(时钟周期也不同的情况将在本章后面进行介绍)
例子1:
● create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM]
● create_clock -name CLKP -period 10 -waveform {0 5} [get_ports CLKP]
多周期建立时间约束指定了给定路径的时钟周期数,如图8-17所示。默认建立时间捕获沿总是与发起沿相隔一个时钟周期,约束多周期建立时间为2会使建立时间捕获沿与发起沿相隔2个时钟周期。
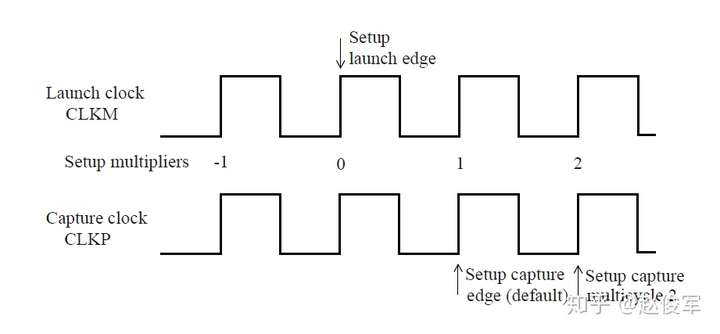
多周期保持时间约束指定了保持时间检查应该在建立时间捕获沿之前几个时钟周期的时钟沿处执行,无论建立时间发起沿在何处,如图8-18所示。默认的保持时间检查是在建立时间捕获沿之前一个周期的时钟沿处执行的。约束多周期保持时间为1会将保持时间检查放置于默认保持时间检查之前一个周期的时钟沿处,因此变为建立时间捕获沿之前两个周期的时钟沿处。
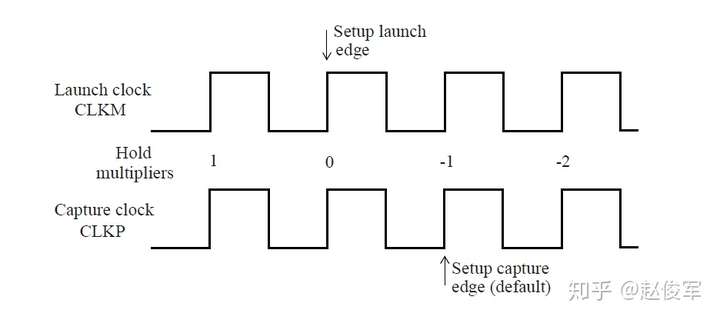
假设有如下多周期路径约束:
● set_multicycle_path 2 -from [get_pins UFF0/CK] -to [get_pins UFF3/D]
由于没有-hold选项,因此将默认为-setup选项。以上约束指定多周期建立时间为2且多周期保持时间为0。对应建立时间检查的路径报告如下所示:
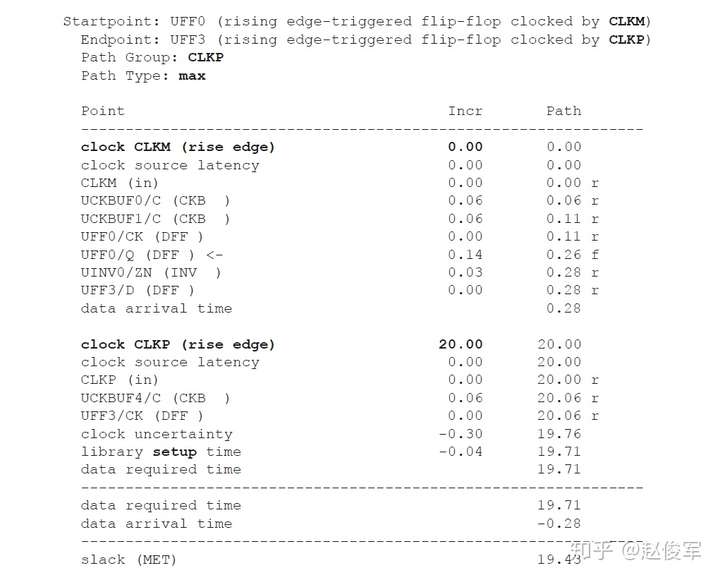
注意,路径报告中所打印出的路径组(Path Group)始终是捕获触发器的路径组,在这种情况下为CLKP。
接下来是保持时间检查的路径报告。由于多周期保持时间约束默认为0,因此将在建立时间捕获沿(20ns)之前一个时钟周期的10ns处进行保持时间检查。
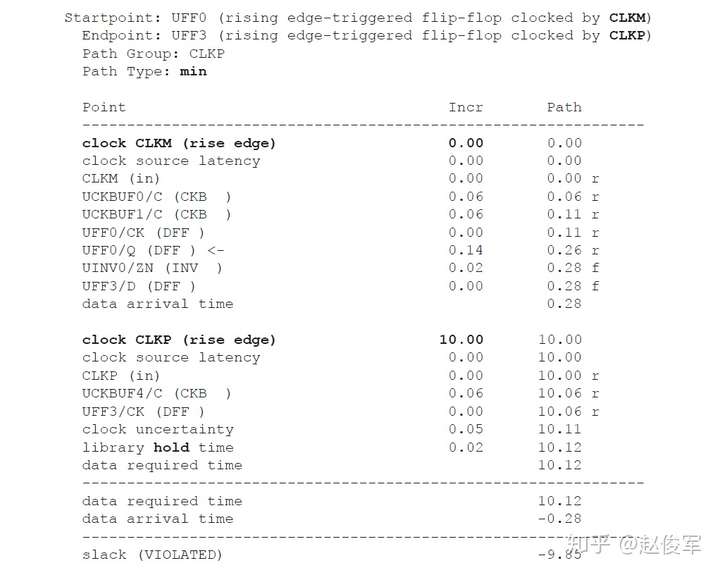
以上报告报出了保持时间违例,这可以通过将多周期保持时间约束指定为1来消除,下面的另一个示例对此进行了说明。
例子2:
● set_multicycle_path 2 -from [get_pins UFF0/CK] -to [get_pins UFF3/D] -setup
● set_multicycle_path 1 -from [get_pins UFF0/CK] -to [get_pins UFF3/D] -hold
以下是多周期建立时间约束为2时建立时间检查的路径报告:
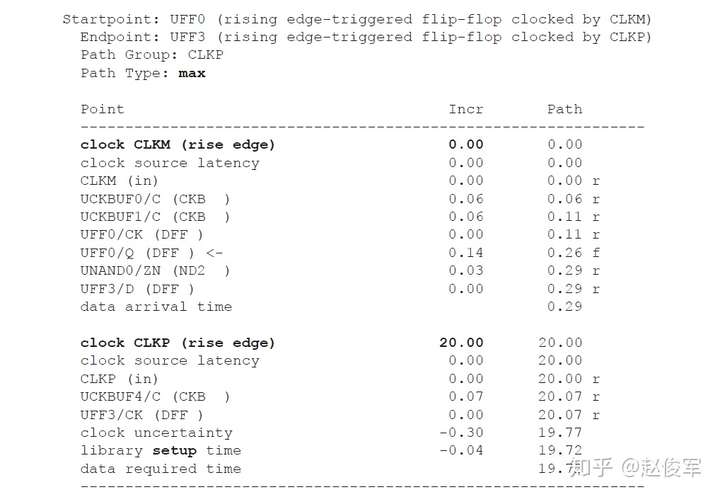

以下是多周期保持时间约束为1时保持时间检查的路径报告:
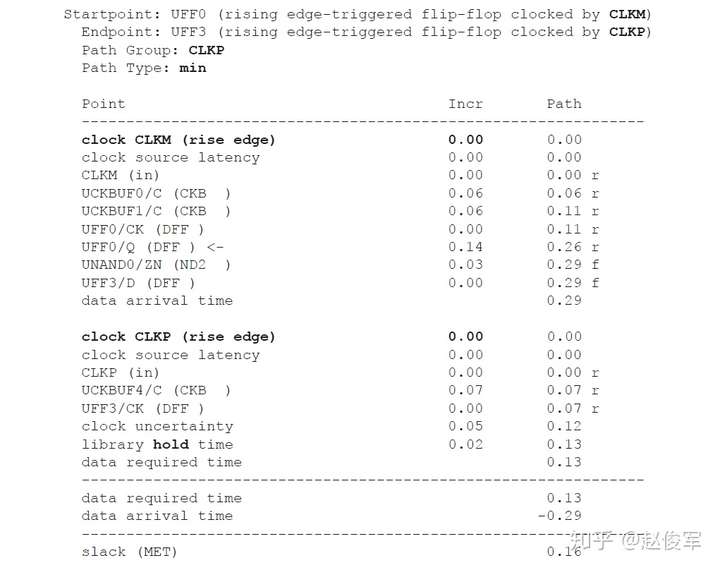
请注意,本节中建立时间检查和保持时间检查的示例报告是针对同一工艺角(corner)的。通常,在最坏情况的慢速工艺角下,建立时间检查最难满足(裕量最小),而在最佳情况的快速工艺角下,保持时间检查最难满足(裕量最小)。
伪路径
当设计的功能运行时,某些时序路径可能不真实(或不可能)存在。在执行STA时可以将这些路径设置为伪路径(false path),这样就可以关闭这些路径,那么STA就不会对这些伪路径去进行分析了。
伪路径可能是从一个时钟域到另一个时钟域、从触发器的时钟引脚到另一触发器的输入引脚、通过一个单元的引脚、通过多个单元的引脚或这些情况的组合 。当通过单元的引脚指定了伪路径后,通过该引脚的所有路径都将被忽略,无需进行时序分析。辨别出伪路径的好处在于减少了分析空间,从而使分析可以专注于真实存在的路径,这同样有助于减少分析时间。但是,过多使用-through选项去指定伪路径同样会降低分析的速度。
可以使用set_false_path命令来约束伪路径,以下是一些例子:
● set_false_path -from [get_clocks SCAN_CLK] -to [get_clocks CORE_CLK]
● set_false_path -through [get_pins UMUX0/S]
● set_false_path -through [get_pins SAD_CORE/RSTN]
● set_false_path -to [get_ports TEST_REG*]
● set_false_path -through UINV/Z -through UAND0/Z
下面给出了一些关于设置伪路径的建议。要在两个时钟域之间设置伪路径,请使用:
● set_false_path -from [get_clocks clockA] -to [get_clocks clockB]
而不要使用:
● set_false_path -from [get_pins {regA_ * }/CK] -to [get_pins {regB_ * }/D]
后者这种方式要慢得多。
另一个建议是尽可能少使用-through选项,因为它增加了运行时不必要的复杂性。仅在绝对有必要且没有替代方法可以指定该伪路径的情况下,才可以使用-through选项。
从优化的角度来看,还有一个建议是不要将一条多周期路径约束为伪路径。如果需要在已知或可预测的时刻对信号进行采样,则无论时间间隔多大,都应使用多周期路径约束,以使路径具有一定的约束条件并进行优化以满足多周期约束。如果把一条许多时钟周期后进行采样的路径指定为了伪路径,则对设计中其余逻辑路径的优化可能会使该路径变长,甚至超出所需的时间。
半周期路径
如果设计中同时具有负边沿触发的触发器(有效时钟沿为下降沿)和正边沿触发的触发器(有效时钟沿为上升沿),则设计中可能存在半周期路径(half-cycle path)。半周期路径可能是从一个触发器的上升沿到另一个触发器的下降沿,或者反过来。图8-19给出了一个示例,其中数据的发起沿在触发器UFF5的时钟下降沿,而数据的捕获沿在触发器UFF3的时钟上升沿。
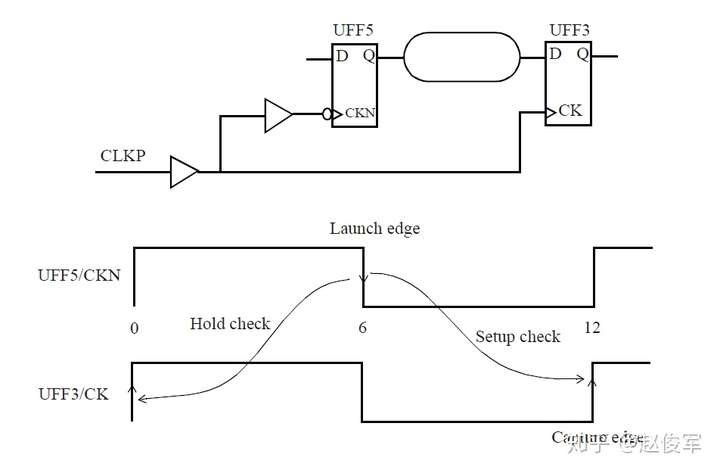
以下是建立时间检查的路径报告:
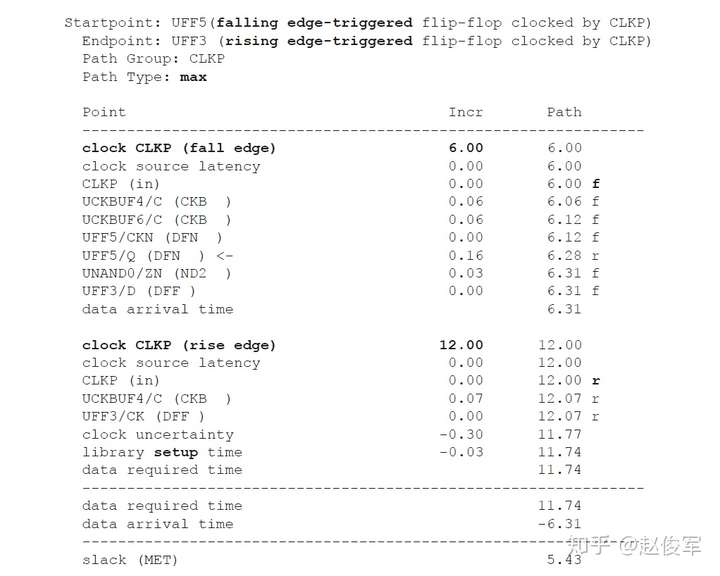
请注意起点(Startpoint)和终点(Endpoint)中的边沿说明。时钟CLKP的下降沿出现在6ns,上升沿出现在12ns。因此,数据需要在半个周期6ns内到达捕获触发器的输入引脚。
虽然在建立时间检查时数据路径仅有半个时钟周期,但额外的半个周期可用于保持时间检查。以下是保持时间检查的路径报告:
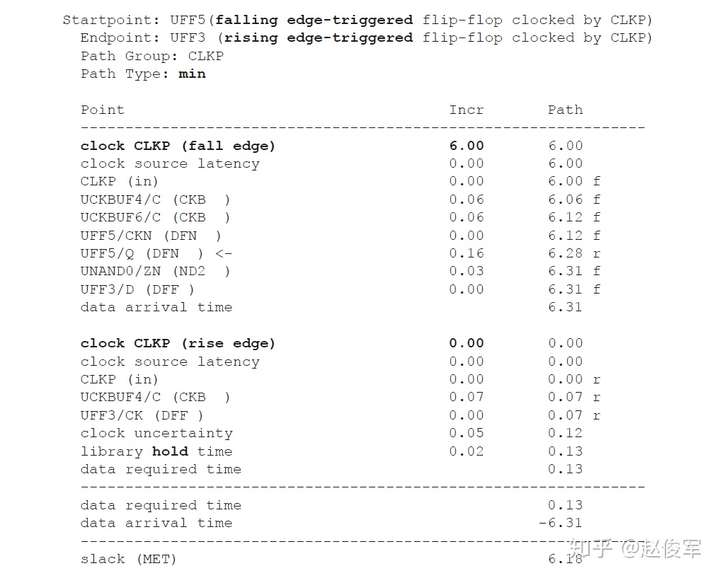
保持时间检查通常是在捕获沿之前一个周期的捕获沿上执行的。由于捕获沿是在12ns处,因此前一个捕获沿在0ns处,故将在0ns处检查保持时间。这为保持时间检查有效地增加了半个时钟周期的裕量,因此可以看见保持时间检查有较大的正裕量(slack)。
撤销时间检查
撤销时间检查(removal timing check)可确保在有效时钟沿与释放异步控制信号之间有足够的时间。该检查可确保有效时钟沿不带来影响,因为异步控制信号将保持有效状态,直到有效时钟沿之后一段撤销时间为止。换句话说,异步控制信号会在有效时钟沿之后被释放(变为无效),因此该时钟沿不会产生任何影响,如图8-20所示。该检查基于的是触发器异步引脚上指定的撤销时间。以下是单元库中与撤销时间检查有关的描述片段:

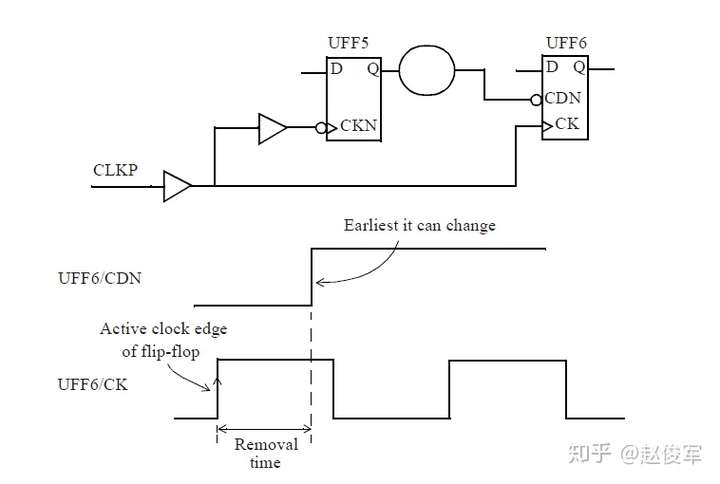
与保持时间检查一样,该检查也是针对最小路径的,不过是在触发器的异步引脚上。
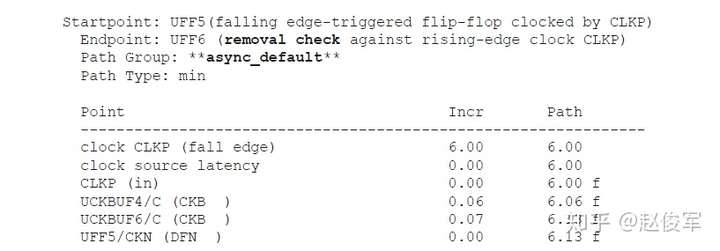


终点(Endpoint)表明这是撤销时间检查,且在触发器UFF6的异步引脚CDN上。该触发器的撤销时间在报告中显示为library removal time,值为0.19ns。
所有异步时序检查均被分配给了async_default路径组。
恢复时间检查
恢复时间检查(recovery timing check)可确保异步信号变为无效状态的时刻与下一个有效时钟沿之间的时间间隔大于一个最小值。换句话说,此检查可确保在异步信号变为无效状态之后,有足够的时间恢复,以便下一个有效时钟沿可以生效。例如,考虑从异步复位变为无效的时刻到触发器有效时钟沿之间的时间间隔。如果该时间间隔太短即有效时钟沿在复位释放后太早出现,则触发器可能进入未知的状态。恢复时间检查如图8-21所示。该检查基于的是触发器异步引脚上指定的恢复时间,单元库文件中与恢复时间有关的描述片段如下:

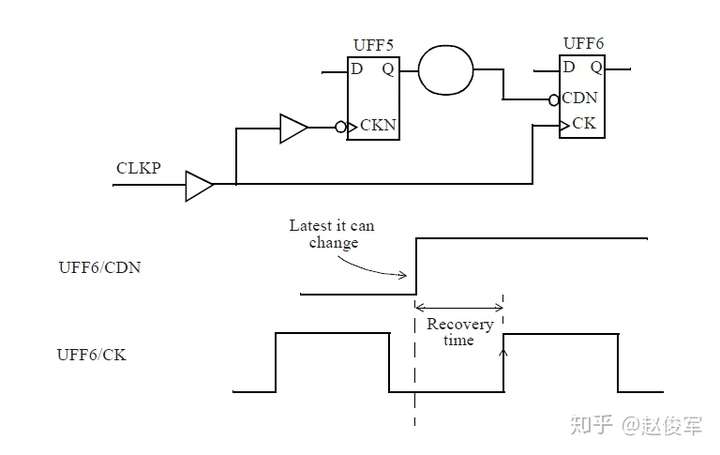
与建立时间检查一样,该检查也是针对最大路径的,不过是在触发器的异步引脚上。
以下是一份恢复时间检查的路径报告:

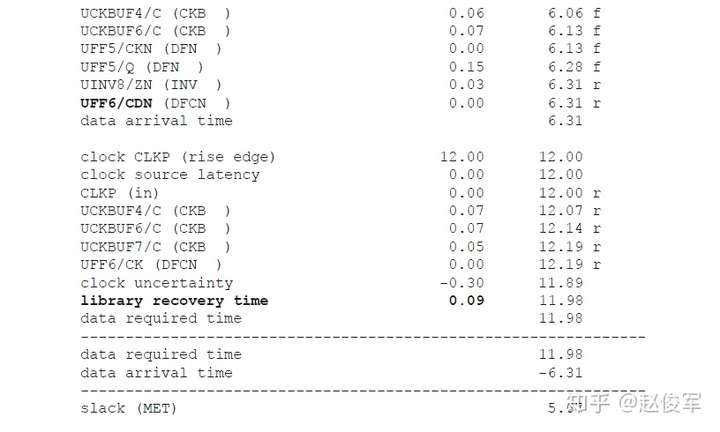
终点(Endpoint)表明这是恢复时间检查,并且触发器UFF6的恢复时间在报告中显示为library recovery time,值为0.09ns。恢复时间检查也属于async_default路径组。
跨时钟域的时序
慢速时钟域到快速时钟域
让我们来对一条从慢速时钟域到快速时钟域的路径来进行建立时间与保持时间检查,如图8-22所示。
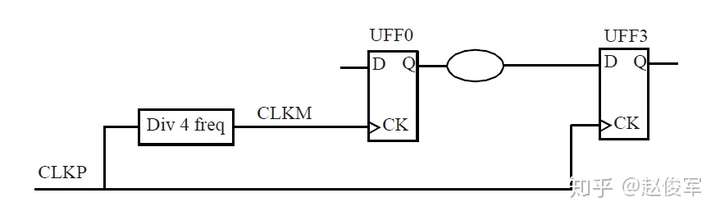
这是以上示例的时钟定义:
● create_clock -name CLKM -period 20 -waveform {0 10} [get_ports CLKM]
● create_clock -name CLKP -period 5 -waveform {0 2.5} [get_ports CLKP]
当数据发起触发器和捕获触发器的时钟频率不同时,STA会首先确定一个公共基本周期(common base period)。下面给出了在具有上述两个时钟的设计中执行STA时打印出的信息。较快的时钟会被延拓,以便获得一个公共周期。

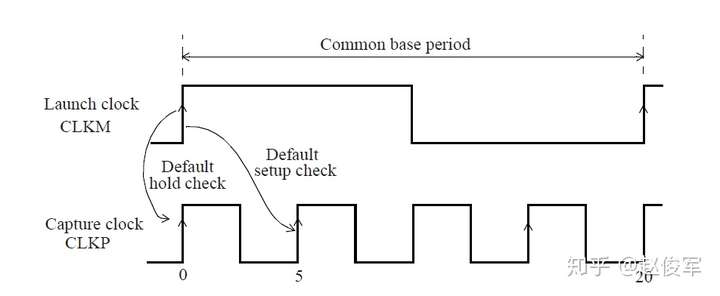
图8-23中为建立时间检查。默认情况下,将使用最严格的建立时间边沿去检查,在本例中为5ns处的时钟沿。以下是此时建立时间检查的路径报告:

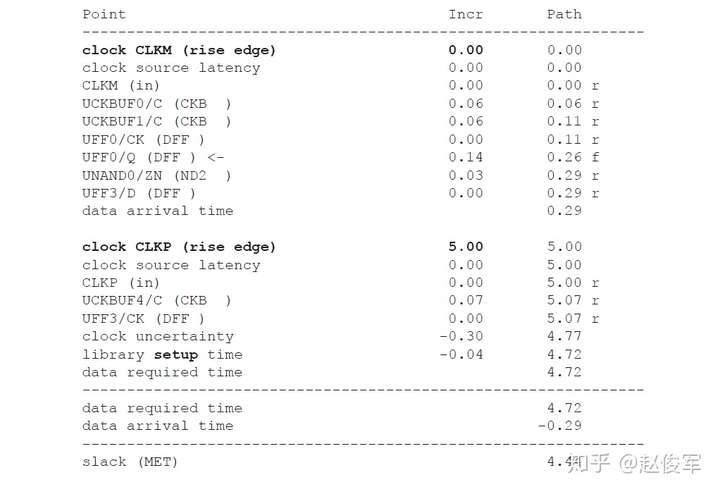
请注意,发起时钟沿为0ns,而捕获时钟沿为5ns。
如前所述,保持时间检查与建立时间检查有关,并确保由当前时钟沿发起的数据不会干扰先前数据的捕获。这是保持时间检查的报告:
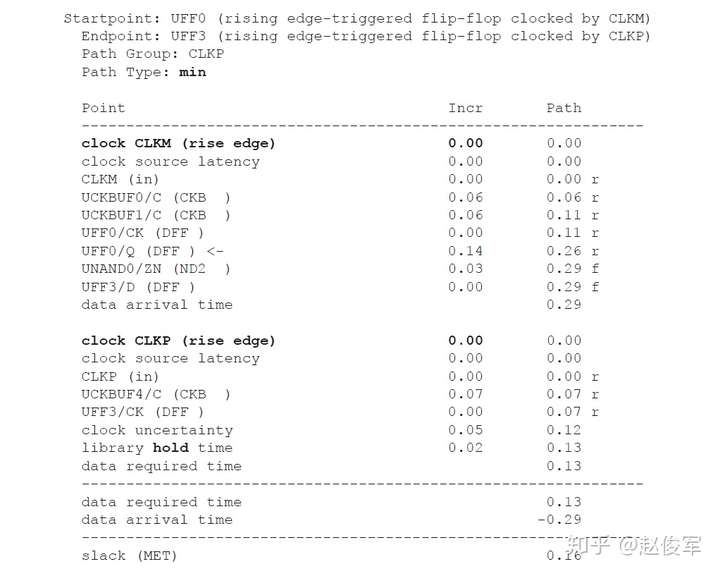
在上面的示例中,我们可以看到发起的数据在捕获时钟的第四个周期可用。让我们假设该设计的目的不是在CLKP的下一个有效沿上就捕获数据,而是在每第4个捕获沿上捕获数据。该假设给触发器之间的组合逻辑路径提供了4个CLKP周期的时间,即20ns。我们可以通过设置以下多周期路径约束来做到这一点:
● set_multicycle_path 4 -setup -from [get_clocks CLKM] -to [get_clocks CLKP] -end
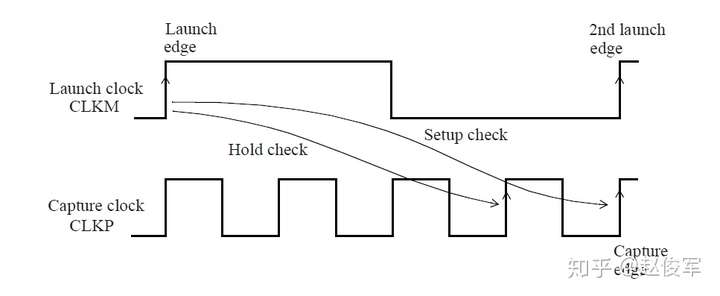 图8-24
图8-24
-end选项指定了多周期4是用于终点(endpoint)或捕获时钟的。此多周期路径约束将建立时间和保持时间检查更改为了图8-24中所示。 以下是这种情况下建立时间检查的路径报告:

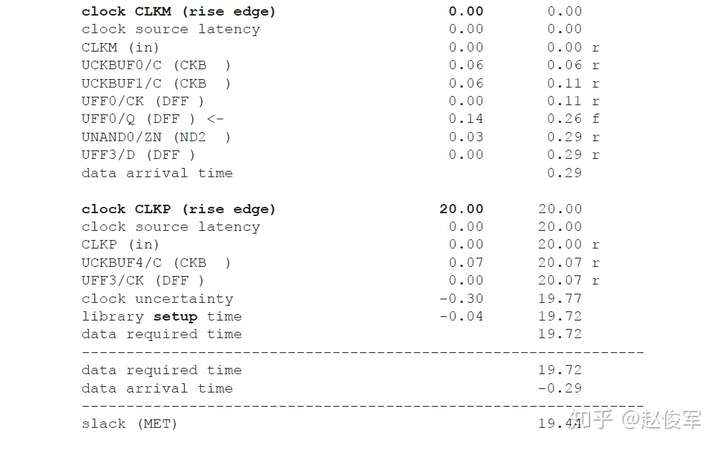
上图8-24中也说明了保持时间检查,请注意,保持时间检查是根据建立时间检查而决定的,默认为当前数据捕获沿之前的一个周期。以下是保持时间检查的路径报告。注意,保持时间捕获沿为15ns,比建立时间捕获沿(20ns)早一个周期(5ns)。

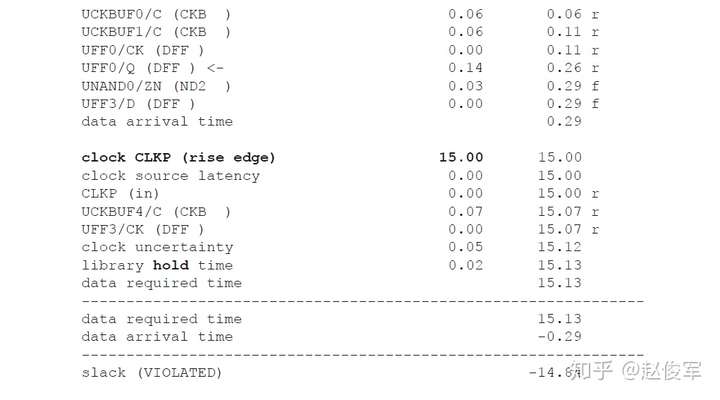
在大多数设计中,这不是理想的时序检查,应将保持时间检查一直移回到数据发起沿所在位置。因此,我们可以约束多周期保持时间为3。
● set_multicycle_path 3 -hold -from [get_clocks CLKM] -to [get_clocks CLKP] -end
3是指将保持时间检查沿向后移三个CLKP时钟周期,即0ns时刻处。与多周期建立时间约束的区别在于:在多周期建立时间约束中,建立时间捕获沿会从默认的建立时间捕获沿向前移动指定的周期数;而在多周期保持时间约束中,保持时间检查沿会从默认的保持时间检查沿向后移动指定的周期数。-end选项意味着我们想将终点(或捕获边沿)移回指定的周期数,即捕获时钟的周期数。代替-end的另一种选项-start指定了要移动的发起时钟周期数,-end选项指定了要移动的捕获时钟周期数。-end是多周期建立时间约束的默认值,-start是多周期保持时间约束的默认值。
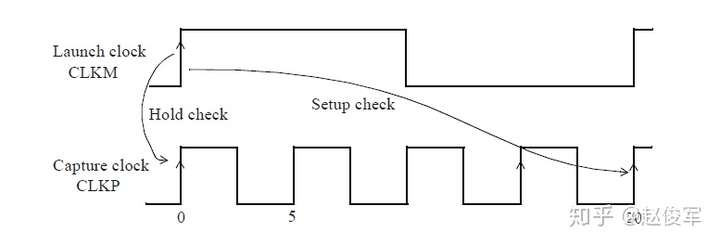
使用多周期保持时间约束,可以将保持时间检查的时钟沿往回移,检查效果如图8-25所示。具有多周期保持时间约束的保持时间检查路径报告如下:
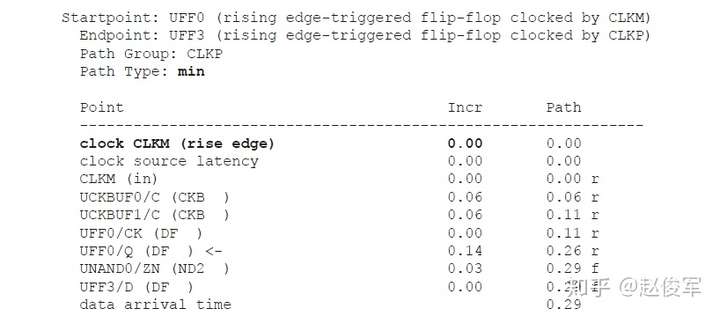
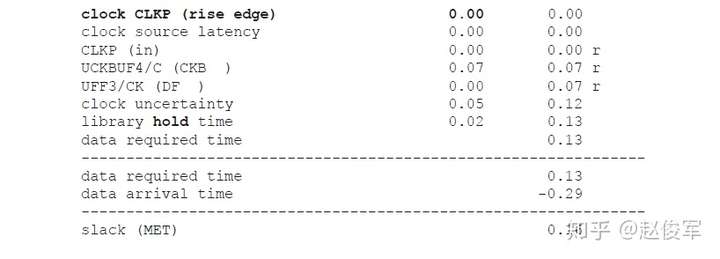
总之,如果指定了N个周期的多周期建立时间,那么很可能还应指定N-1个周期的多周期保持时间。对于慢速到快速时钟域之间的路径,多周期路径约束的一个好经验是使用-end选项。使用此选项,可以根据快速时钟的时钟周期来调整建立时间和保持时间检查。
快速时钟域到慢速时钟域
在本小节中,我们考虑数据路径从快速时钟域到慢速时钟域的示例。使用以下时钟定义时,默认的建立时间和保持时间检查如图8-26所示。
● create_clock -name CLKM -period 20 -waveform {0 10} [get_ports CLKM]
● create_clock -name CLKP -period 5 -waveform {0 2.5} [get_ports CLKP]
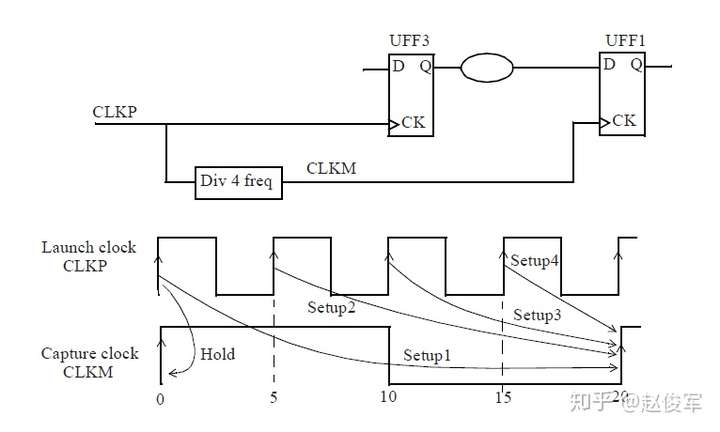
总共可能有四种建立时间检查,请参阅图8-26中的Setup1,Setup2,Setup3和Setup4。其中,最严格的是Setup4检查。以下是此最严格检查的路径报告。请注意,数据发起时钟沿为15ns,捕获时钟沿为20ns。

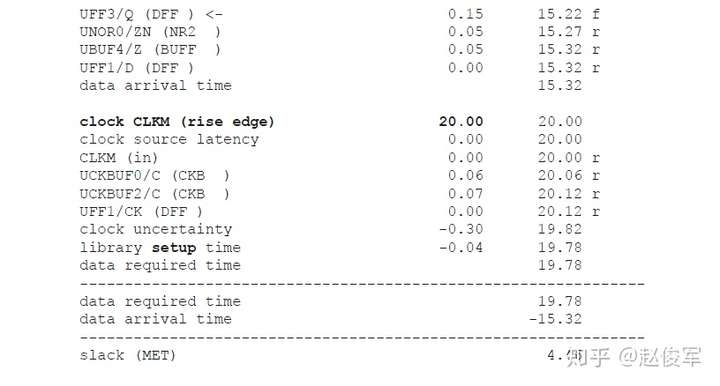
与建立时间检查类似,总共也可能有四种保持时间检查。图8-26中所示为最严格的保持时间检查,该检查可确保0ns处的捕获沿不捕获0ns处正在发起的数据。以下是这种情况下保持时间检查的路径报告:
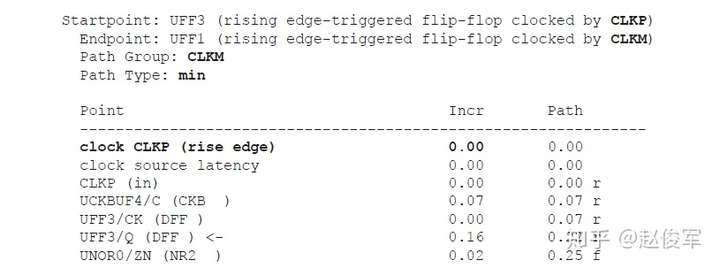

通常,设计人员可以将从快时钟域到慢时钟域的数据路径指定为多周期路径。如果想要放宽建立时间检查,比如为数据路径提供两个快时钟周期,则此多周期路径约束如下:
● set_multicycle_path 2 -setup -from [get_clocks CLKP] -to [get_clocks CLKM] -start
● set_multicycle_path 1 -hold -from [get_clocks CLKP] -to [get_clocks CLKM] -start
在这种情况下,图8-27中为用于建立时间和保持时间检查的时钟沿。-start选项指定周期数的单位(在这种情况下为2)是发起时钟周期(在这种情况下为CLKP)。约束多周期建立时间为2会将发起沿移动到默认发起沿之前的一个时钟沿,即在10ns而不是默认的15ns处。多周期保持时间约束确保了在0ns处发起沿发起的数据,不会被0ns处的捕获沿捕获到。
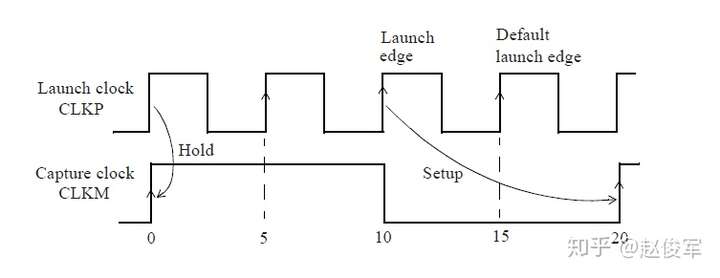
以下是建立时间检查的路径报告。与预期一样,发起时钟沿为10ns,捕获时钟沿为20ns。
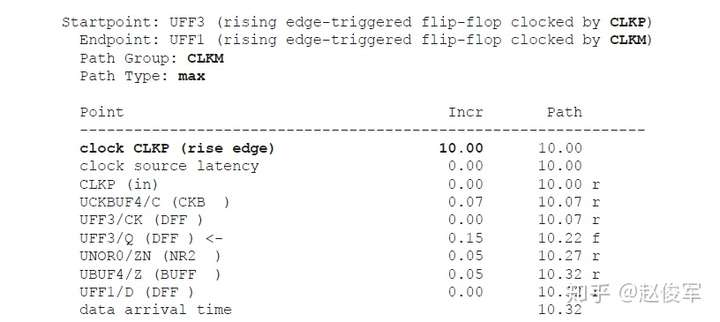
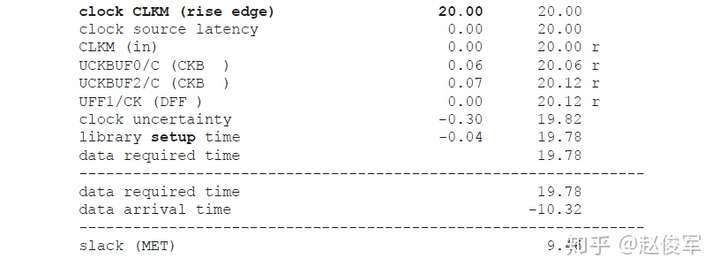
以下是保持时间检查的路径报告。保持时间检查是在0ns处执行的,此时捕获时钟和发起时钟均为上升沿。
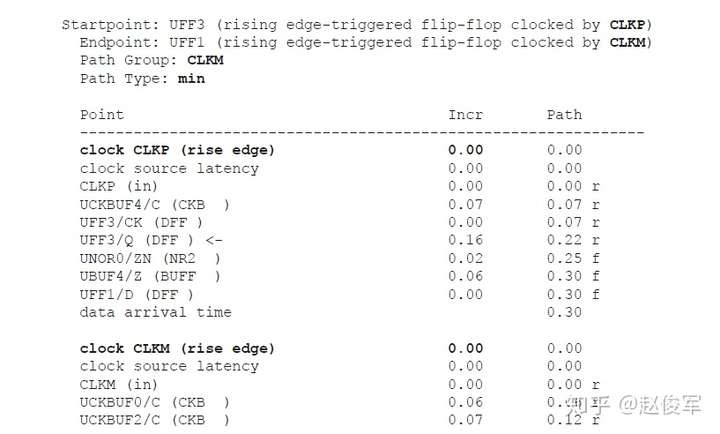

与从慢速时钟域到快速时钟域的路径不同,在从快速时钟域到慢速时钟域的路径中,多周期路径约束的一个好经验是使用-start选项,然后再根据快速时钟调整建立时间和保持时间检查。
举例
在本节中,我们将介绍发起和捕获时钟的不同情况,并分别说明如何执行建立时间和保持时间检查。图8-28为所举例子的示意图:
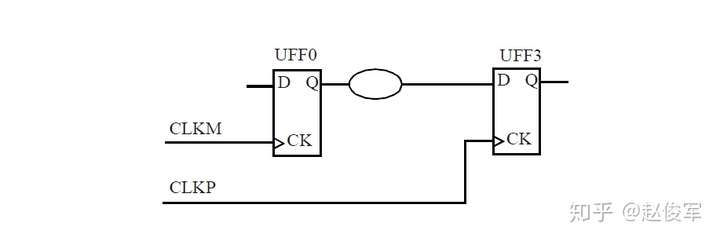
半周期路径——情况1
在此示例中,两个时钟具有相同的周期,但相位相反。以下是时钟定义,其波形如图8-29所示。
● create_clock -name CLKM -period 20 -waveform {0 10} [get_ports CLKM]
● create_clock -name CLKP -period 20 -waveform {10 20} [get_ports CLKP]
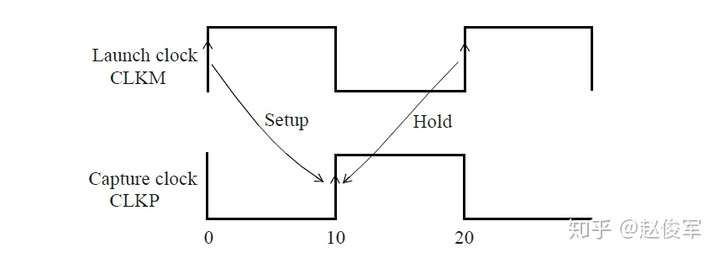
建立时间检查是从发起沿(0ns)到下一个捕获沿(10ns)的。半个时钟周期的裕量可用于保持时间检查,以验证在20ns处发起的数据是否在10ns处未被捕获沿所捕获。以下是建立时间检查的路径报告:


以下是保持时间检查的路径报告:
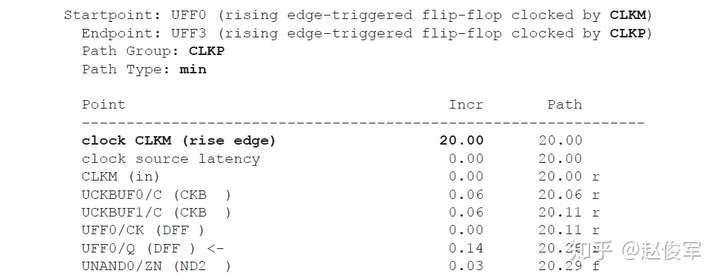

半周期路径——情况2
此示例与情况1类似,不过发起时钟和捕获时钟的相位相反。以下是时钟定义,其波形如图8-30所示。
● create_clock -name CLKM -period 10 -waveform {5 10} [get_ports CLKM]
● create_clock -name CLKP -period 10 -waveform {0 5} [get_ports CLKP]
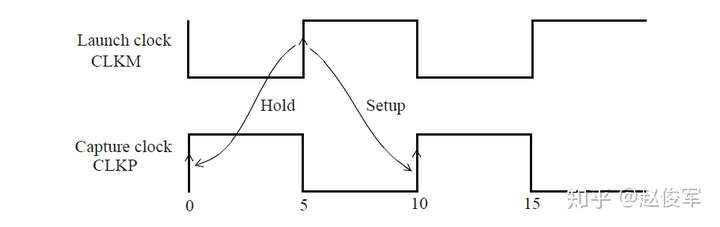
建立时间检查从5ns的发起时钟沿到10ns的下一个捕获时钟沿。保持时间检查从5ns的发起时钟沿到0ns的捕获时钟沿。以下是建立时间检查的路径报告:
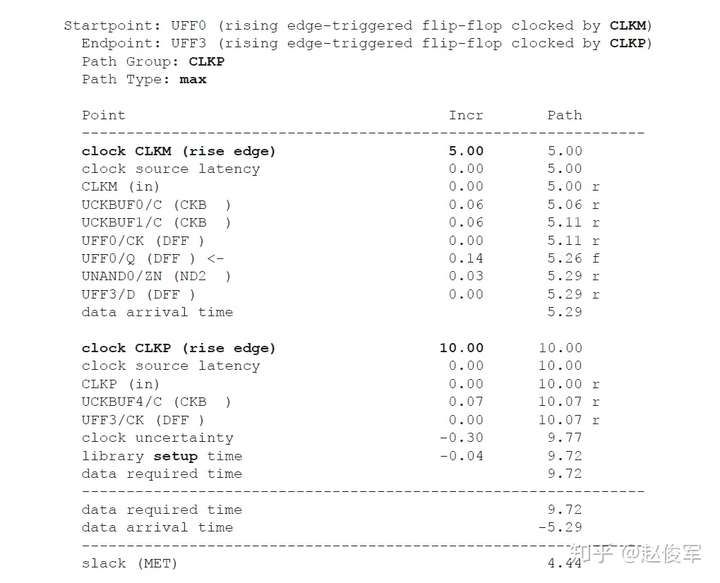
以下是保持时间检查的路径报告:
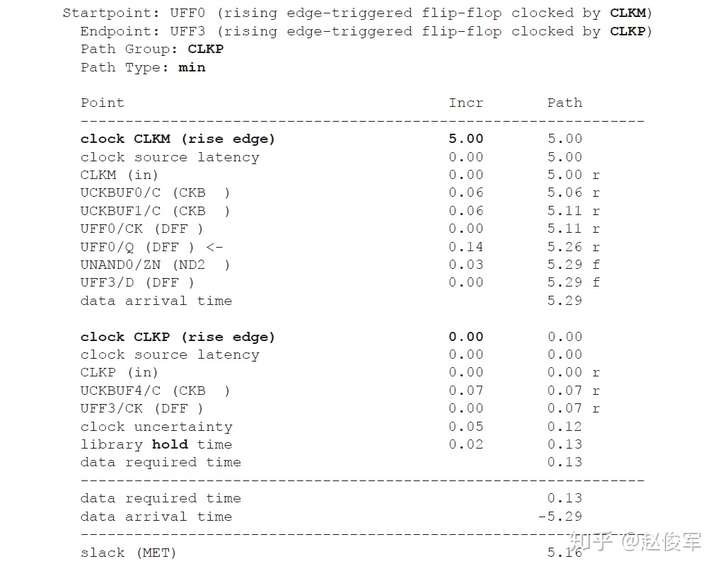
快速时钟域到慢速时钟域
在此示例中,捕获时钟是发起时钟的二分频。以下是时钟定义:
● create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM]
● create_clock -name CLKP -period 20 -waveform {0 10} [get_ports CLKP]
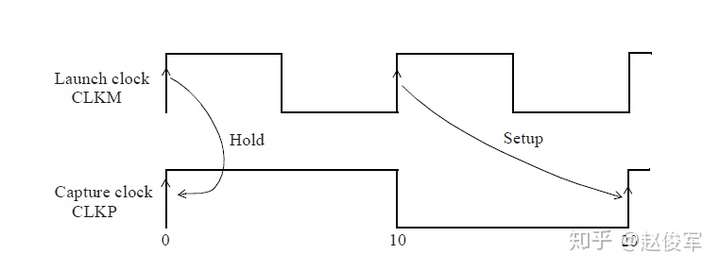
波形如图8-31所示。建立时间检查是从10ns的发起沿到20ns的捕获沿,保持时间检查是从0ns的发起沿到0ns的捕获沿。以下是建立时间检查的路径报告:

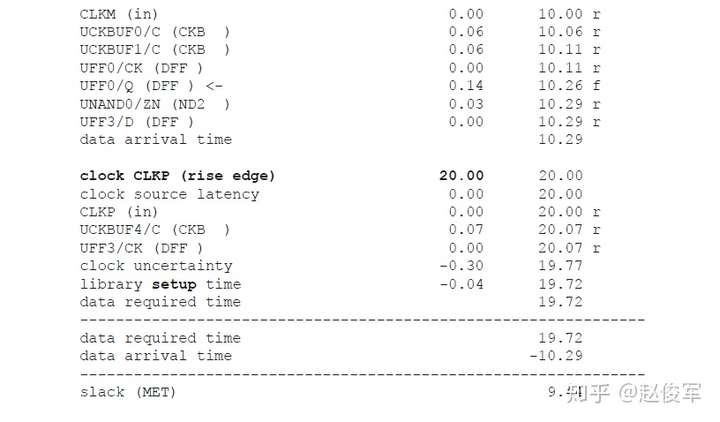
以下是保持时间检查的路径报告:
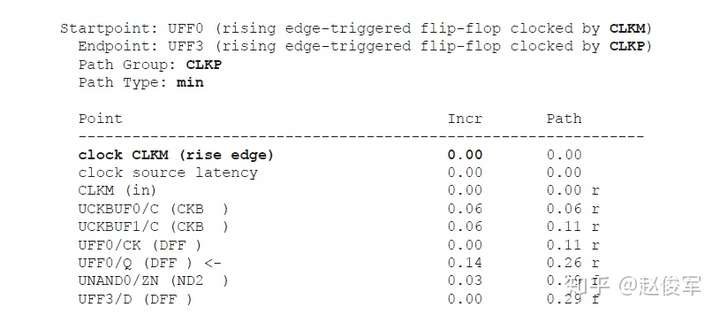
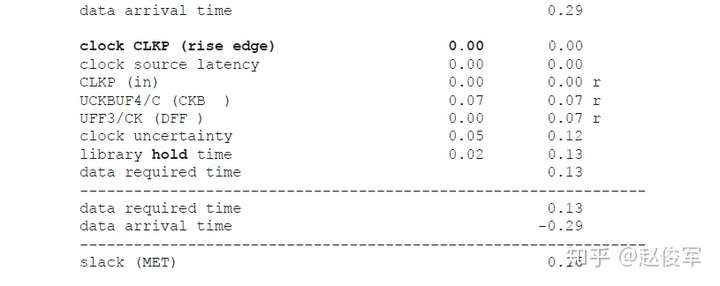
慢速时钟域到快速时钟域
在此示例中,捕获时钟速度是发起时钟速度的2倍。图8-32中为建立时间和保持时间检查对应的时钟沿:从发起沿0ns到下一个捕获沿5ns进行建立时间检查,保持时间检查是在建立时间捕获沿前一个周期的捕获沿进行的,也就是说,发起沿和捕获沿都为0ns。
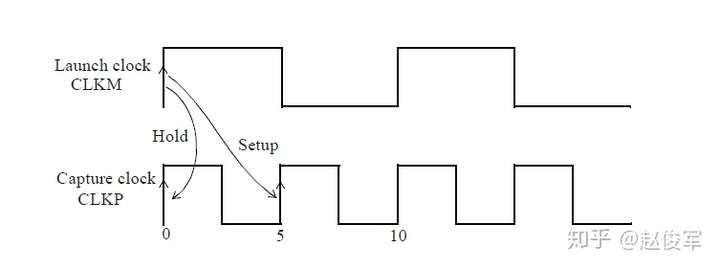
以下是建立时间检查的路径报告:
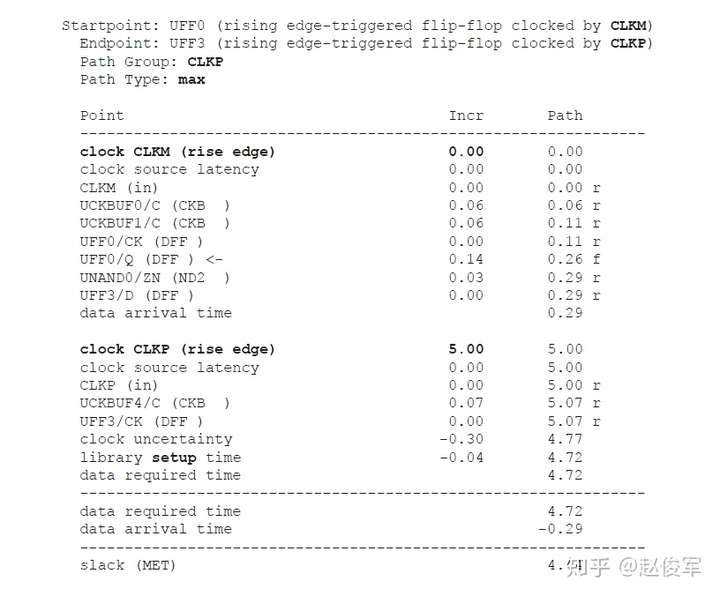
以下是保持时间检查的路径报告:

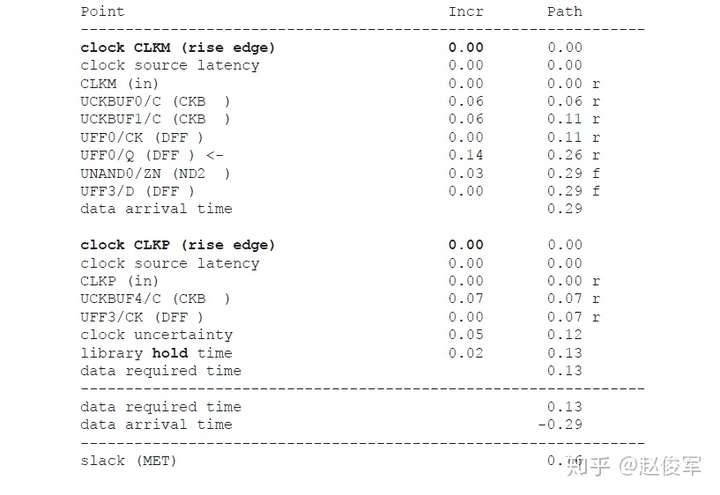
多时钟
整数倍
在设计中通常会定义多个时钟,这些时钟的频率是彼此的整数倍。在这种情况下,会通过计算所有相关时钟(related clocks)之间的公共基本周期来执行STA(如果两个时钟域之间具有数据路径,则两个时钟相关)。建立公共基本周期的目的是以便所有时钟都同步。
以下是3个相关时钟的示例:
● create_clock -name CLKM -period 20 -waveform {0 10} [get_ports CLKM]
● create_clock -name CLKQ -period 10 -waveform {0 5} [get_ports CLKQ]
● create_clock -name CLKP -period 5 -waveform {0 2.5} [get_ports CLKP]
分析CLKP和CLKM时钟域之间的路径时,将使用20ns的公共基本周期,如图8-33所示。
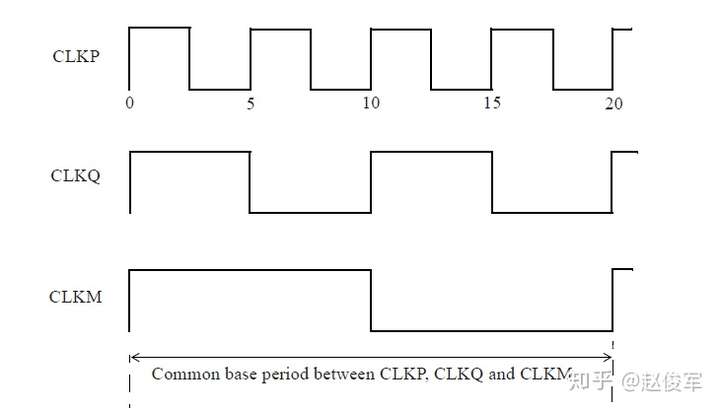
以下是建立时间检查的路径报告,用于从较快时钟CLKP到较慢时钟CLKM的路径。
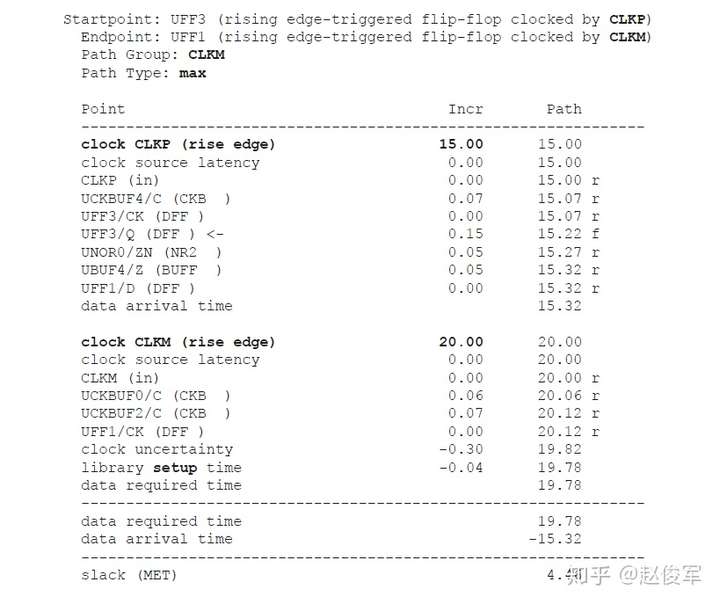
相应保持时间检查的路径报告如下:

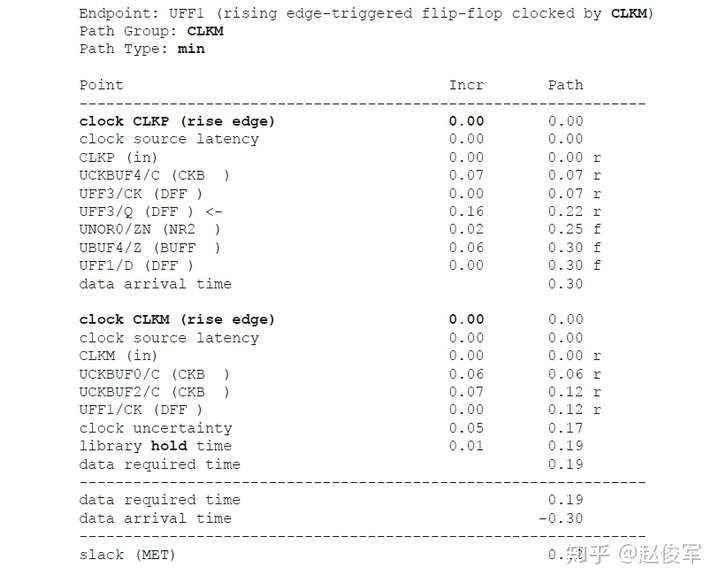
非整数倍
考虑当两个频率不是彼此整数倍的时钟域之间存在数据路径的的情况。例如,发起时钟是公共时钟的8分频,而捕获时钟是公共时钟的5分频,如图8-34所示。本节将介绍在这种情况下如何执行建立时间和保持时间检查。
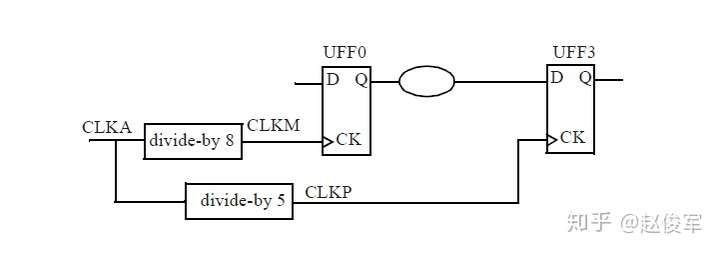
以下是时钟定义,其波形如图8-35所示:
● create_clock -name CLKM -period 8 -waveform {0 4} [get_ports CLKM]
● create_clock -name CLKQ -period 10 -waveform {0 5} [get_ports CLKQ]
● create_clock -name CLKP -period 5 -waveform {0 2.5} [get_ports CLKP]
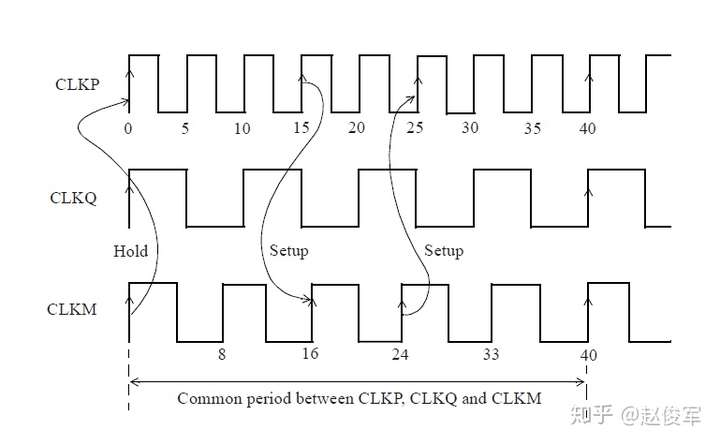
时序分析会先计算相关时钟的公共周期,然后再将时钟扩展到该公共周期。请注意,仅针对相关时钟(即在它们之间具有时序路径的时钟)去计算公共周期。CLKQ和CLKP之间数据路径的公共周期仅扩展为10ns的公共周期,CLKM和CLKQ之间数据路径的公共周期为40ns,而CLKM和CLKP之间数据路径的公共周期也为40ns。
让我们考虑一条从CLKM时钟域到CLKP时钟域的数据路径,这种情况下时序分析的公共基本周期为40ns。
建立时间检查在时钟发起沿和捕获沿之间的最短时间内进行。在我们从CLKM到CLKP的示例路径中,这就是24ns处的时钟CLKM发起沿以及25ns处的时钟CLKP捕获沿。

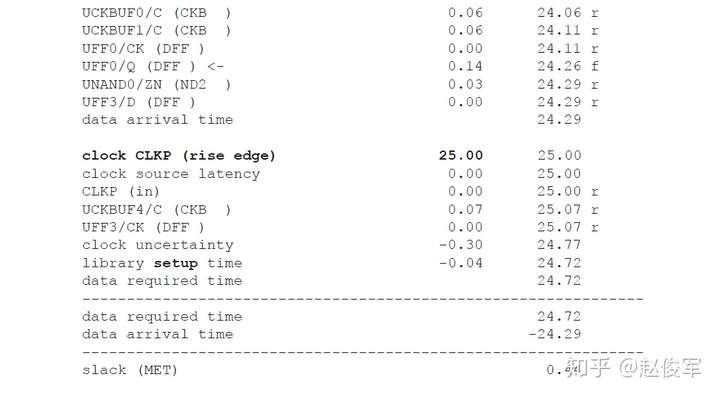
以下是保持时间检查的路径报告,最严格的保持时间检查是从0ns处的CLKM发起沿到0ns处的CLKP捕获沿。
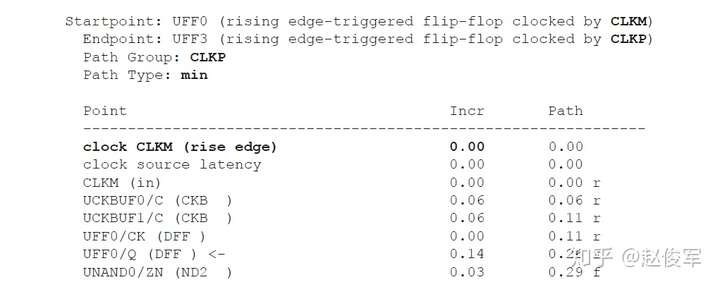
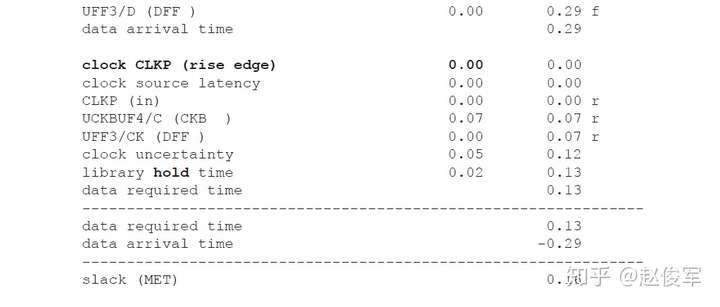
现在,我们对从CLKP时钟域到CLKM时钟域的路径的建立时间进行检查。在这种情况下,最严格的建立时间检查是从15ns处的时钟CLKP发起沿到16ns处的时钟CLKM捕获沿。
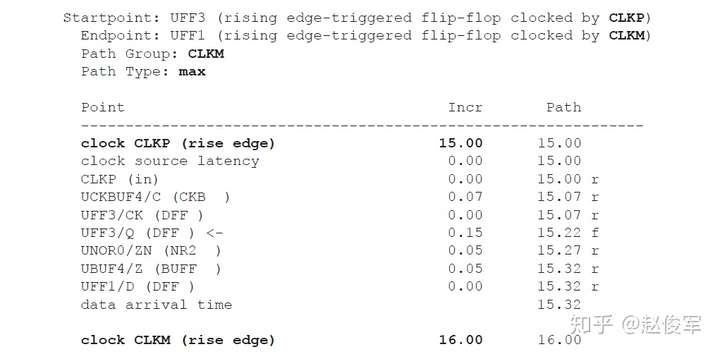

以下是保持时间检查的路径报告,同样,最严格的还是0ns处的检查。
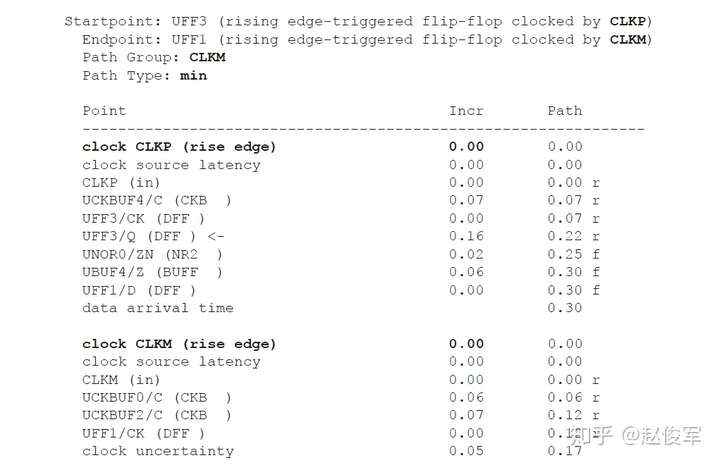

移相
在以下示例中,两个时钟有90°的相移(phase shift):
● create_clock -period 2.0 -waveform {0 1.0} [get_ports CKM]
● create_clock -period 2.0 -waveform {0.5 1.5} [get_ports CKM90]
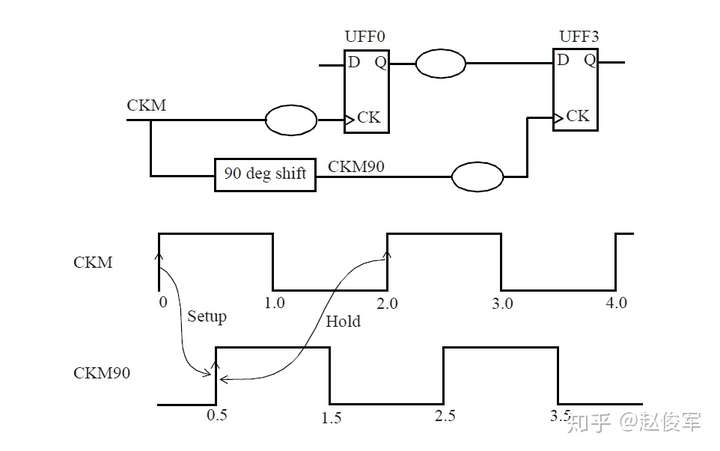
图8-36给出了使用这两个时钟的示例。建立时间检查的路径报告如下:


0.5ns处的CKM90第一个上升沿是捕获沿,保持时间检查是在建立时间捕获沿之前一个周期的时钟沿处。对于2ns的发起沿,建立时间捕获沿为2.5ns,因此保持时间检查沿就在0.5ns处的前一个捕获沿。保持时间检查的路径报告如下:
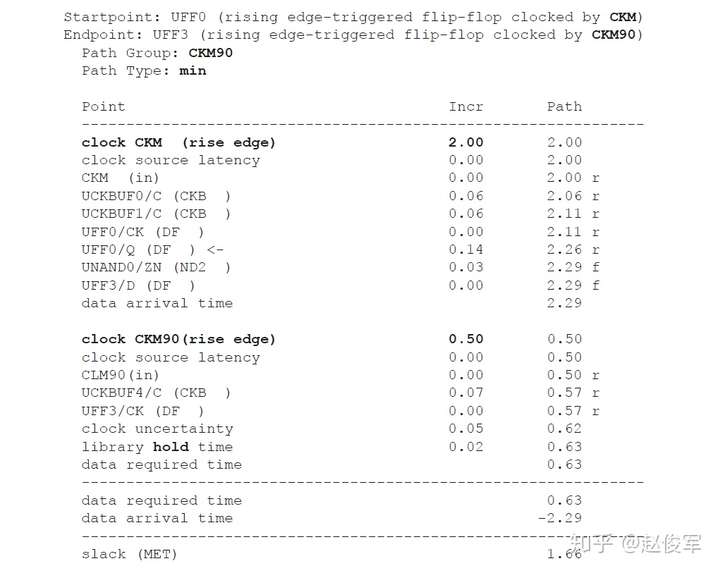
在第10章中还会介绍其它时序检查,例如数据到数据(data to data)检查和时钟门控(clock gating)检查。
接口分析
本章节将介绍各种类型输入和输出路径的时序分析过程以及几种常用的接口,还介绍了特殊接口(例如SRAM)的时序分析和源同步接口(例如DDR SDRAM)的时序分析。
IO接口
本小节中的示例说明了该如何定义DUA输入和输出接口的约束。后面的小节介绍了SRAM和DDR SDRAM接口的时序约束示例。
输入接口
有两种指定输入接口时序要求的方法:
● 以AC特性的形式指定DUA输入端的波形。
● 指定外部逻辑到输入的路径延迟。
指定输入端口的波形
考虑图9-1中所示的输入AC特性:输入CIN在时钟CLKP的上升沿之前4.3ns必须保持稳定,并且必须要保持稳定直到时钟上升沿之后2ns。
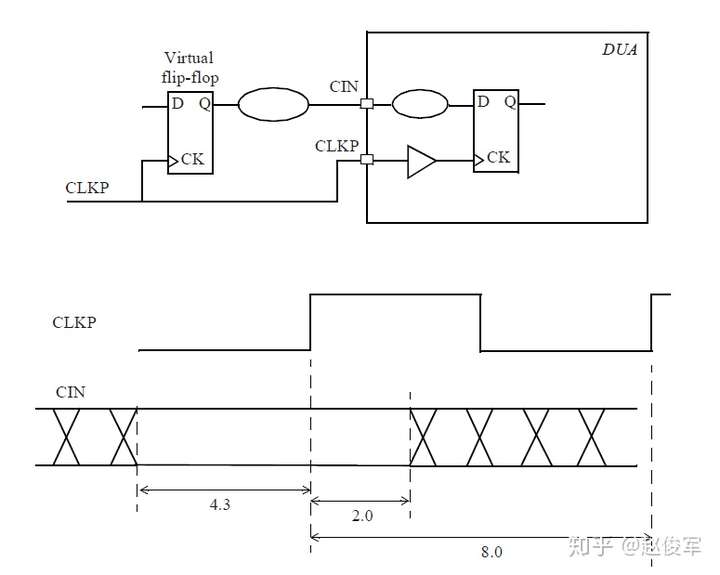
首先考虑4.3ns的约束,给定时钟周期为8ns(如图9-1所示),这约束了从虚拟触发器(驱动该输入的触发器)到输入端口CIN的延迟。从虚拟触发器时钟引脚到CIN的延迟最大为3.7ns(= 8.0-4.3), 这样可确保输入CIN处的数据在上升沿之前4.3ns到达。因此,AC特性的这一部分可以等效地指定为3.7ns的最大输入延迟。
AC特性还指出,输入CIN在时钟上升沿之后2ns必须继续保持稳定,这也约束了虚拟触发器的延迟,即从虚拟触发器到输入CIN的延迟必须至少为2.0ns。因此,最小输入延迟指定为2.0ns。
以下是输入延迟约束:
● create_clock -name CLKP -period 8 [get_ports CLKP]
● set_input_delay -min 2.0 -clock CLKP [get_ports CIN]
● set_input_delay -max 3.7 -clock CLKP [get_ports CIN]
以下是设计在这些输入延迟约束下的路径报告,首先是建立时间检查:
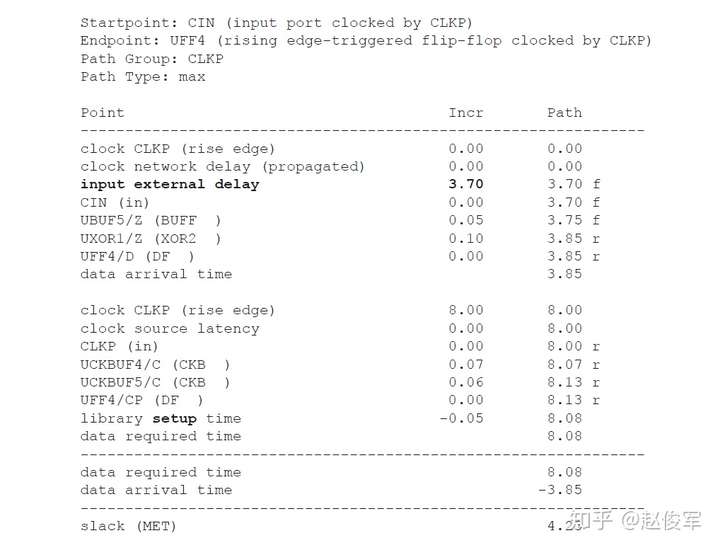
指定的最大输入延迟(3.7ns)被添加到了数据路径中。建立时间检查会确保DUA内部的延迟小于4.3ns,这样就可以锁存到正确的数据。 接下来是保持时间检查:

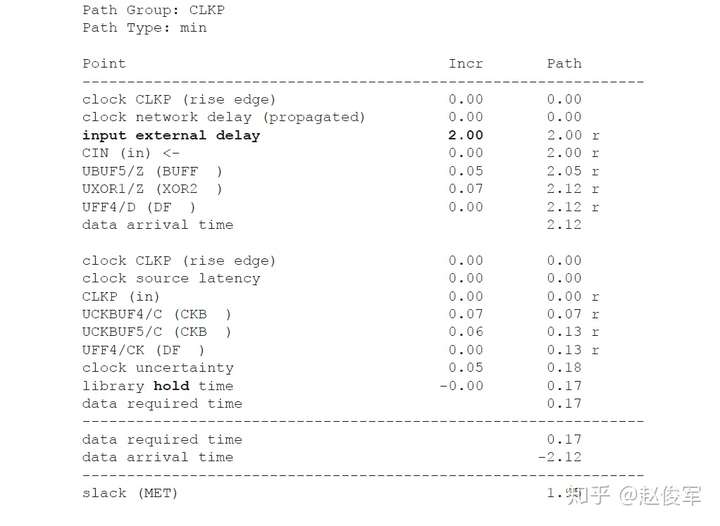
最小输入延迟将被添加到保持时间检查的数据路径中。该检查可确保最早的数据在时钟沿之后的2ns处才变化,这样就不会覆盖触发器上捕获到的先前数据。
指定输入端口的路径延迟
已知连接到输入的外部逻辑的路径延迟后,指定输入约束就是一件很简单的事情了。将沿外部逻辑路径到输入的任何延迟全部相加起来,然后使用set_input_delay命令去指定路径延迟。
图9-2给出了一条输入的外部逻辑路径示例。Tck2q和Tc1延迟相加就是外部延迟,知道了Tck2q和Tc1,就可以直接获得输入延迟,即Tck2q + Tc1。
外部逻辑的最大和最小路径延迟可以转换为以下输入延迟约束:
● create_clock -name RCLK -period 10 [get_ports RCLK]
● set_input_delay -max 6.2 -clock RCLK [get_ports INIT]
● set_input_delay -min 3.0 -clock RCLK [get_ports INIT]
上述输入延迟约束的时序检查路径报告与8.1节和8.2节中的报告类似。
请注意,在计算设计内部触发器数据引脚的实际到达时间时,将会根据执行的是最大路径(建立时间)检查还是最小路径(保持时间)检查,分别选择将输入延迟的最大值或最小值添加到数据路径延迟中去。
输出接口
与输入接口类似,也可以使用两种方法来指定输出时序要求:
● 以AC特性的形式指定DUA输出端的波形。
● 指定输出到外部逻辑的路径延迟。
指定输出端口的波形
考虑图9-3中所示的输出AC特性:在时钟CLKP的上升沿之前2ns,输出QOUT就应保持稳定。同样,输出QOUT需要保持稳定直到时钟上升沿之后的1.5ns为止。通常可从与QOUT接口的外部模块的建立时间和保持时间要求中获得这些约束值。
以下是对输出端口时序要求进行的约束:
● create_clock -name CLKP -period 6 -waveform {0 3} [get_ports CLKP]
● set_output_delay -clock CLKP -max 2.0 [get_ports QOUT]
● set_output_delay -clock CLKP -min -1.5 [get_ports QOUT]
最大输出路径延迟指定为了2.0ns,这将确保数据QOUT在时钟沿前2ns之前允许改变。从虚拟触发器的角度来看,最小输出路径延迟指定为了-1.5ns,这用于确保在输出QOUT上1.5ns的保持时间要求。1.5ns的保持时间要求就是set_output_delay中指定的最小值-1.5。
以下是建立时间检查的路径报告:
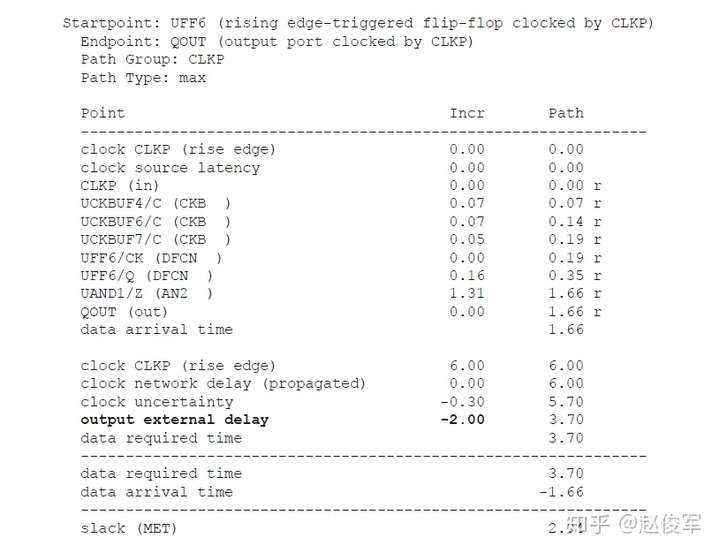
在建立时间检查中,将从下一个时钟沿减去最大的输出延迟,以确定在DUA输出处数据需要到达的时间。
接下来是保持时间检查的路径报告:
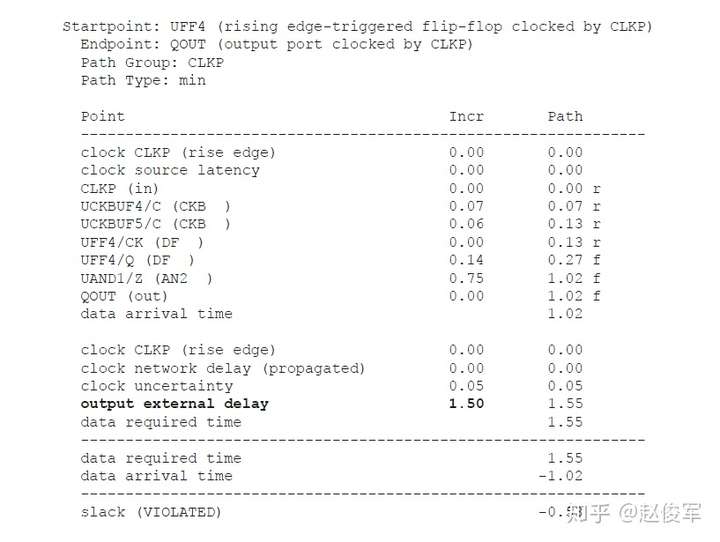
在保持时间检查中,将从捕获时钟边沿中减去最小的输出延迟(-1.5ns),以确定满足保持时间要求的DUA输出的数据最早到达时间。注意,最小输出延迟为负值很常见。
指定输出端口的路径延迟
在这种情况下,将明确指定外部逻辑的路径延迟。请参见图9-4中的示例:
让我们首先检查建立时间,由Tc2_max和Tsetup可获得最大输出延迟(set_output_delay -max)。为了检查DUA内部触发器(例如UFF0)和虚拟触发器之间输出路径的建立时间要求,最大输出延迟可指定为Tc2_max + Tsetup。
接下来,让我们检查保持时间,由Tc2_min和Thold可获得最小输出延迟(set_output_delay -min)。由于捕获触发器的保持时间被添加到了捕获时钟路径中,因此最小输出延迟指定为Tc2_min-Thold。
以下是输出延迟约束:
● create_clock -name SCLK -period 5 [get_ports SCLK]
● set_output_delay -max 3.1 -clock SCLK [get_ports RDY]
● set_output_delay -min 1.45 -clock SCLK [get_ports RDY]
这些路径报告与8.1节和8.2节中的报告相似。
时序窗口内的输出变化
set_output_delay命令可用于指定输出信号相对于时钟的最大和最小到达时间。本节考虑特殊情况,当输出只能在相对于时钟沿的时序窗口内发生改变时,可以指定输出延迟约束来验证时序,在验证源同步(source synchronous)接口的时序时尤其常用。
在源同步接口中,时钟也与数据一起输出。在这种情况下,通常时钟和数据之间需要有一个时序关系。例如,可能仅在时钟上升沿附近的特定时序窗口内才能改变输出数据。
源同步接口的时序要求如下图9-5所示:
该时序要求:DATAQ的每个比特位(bit)只能在指定的时序窗口中改变,即在时钟上升沿之前2ns以及时钟上升沿之后1ns之间。这与前面各节中讨论的输出延迟约束有很大的不同,在前几节中,要求数据引脚在时钟上升沿附近的指定时序窗口中保持稳定。
我们以CLKM为主时钟创建了一个衍生时钟CLK_STROBE,方便去指定与该接口要求相对应的时序约束。
● create_clock -name CLKM -period 6 [get_ports CLKM]
● create_generated_clock -name CLK_STROBE -source CLKM -divide_by 1 [get_ports CLK_STROBE]
通过结合建立时间和保持时间检查以及多周期路径约束来指定时序窗口要求。该时序要求对应在单个上升沿(相同的发起沿和捕获沿)处进行建立时间检查。因此,我们将多周期建立时间指定为0。
● set_multicycle_path 0 -setup -to [get_ports DATAQ]
另外,保持时间检查必须在同一时钟沿上执行,因此我们需要将多周期保持时间指定为-1。
● set_multicycle_path -1 -hold -to [get_ports DATAQ]
现在,相对于时钟CLK_STROBE指定输出的时序约束:
● set_output_delay -max -1.0 -clock CLK_STROBE [get_ports DATAQ]
● set_output_delay -min +2.0 -clock CLK_STROBE [get_ports DATAQ]
请注意,输出延迟约束中指定的最小值大于最大值。之所以会这样,是因为在这种情况下,输出延迟约束并不对应于实际的逻辑块。与典型的输出接口(其中输出延迟约束对应于输出处的逻辑块)不同,源同步接口中的set_output_delay约束只是一种机制,用于验证输出是否被限制在了时钟有效沿附近的指定窗口内才能切换 。因此,我们才会有最小输出延迟大于最大输出延迟这样的一种异常情况。
这是针对以上约束的建立时间检查路径报告:
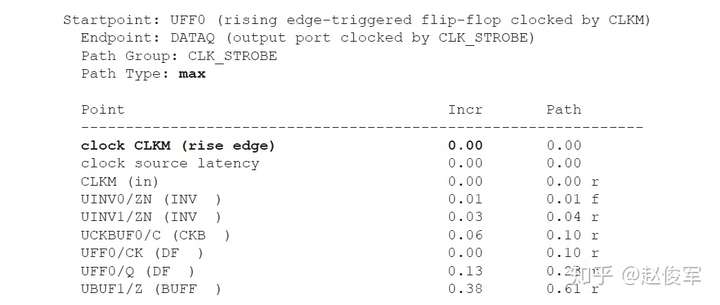
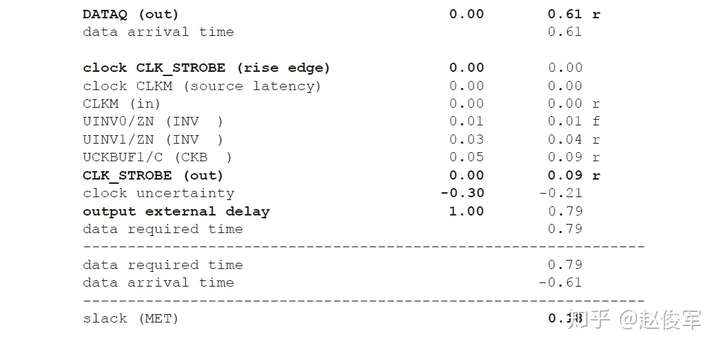
请注意,数据发起沿和捕获沿都为在0时刻处的相同时钟沿。该报告显示DATAQ在0.61ns处变化,而CLK_STROBE在0.09ns处变化。由于DATAQ可以在CLK_STROBE的1ns内被允许变化,因此在考虑了0.3ns的时钟不确定性后,正裕量为0.18ns。
以下是保持时间检查的路径报告,用于检查时钟另一侧的界限:

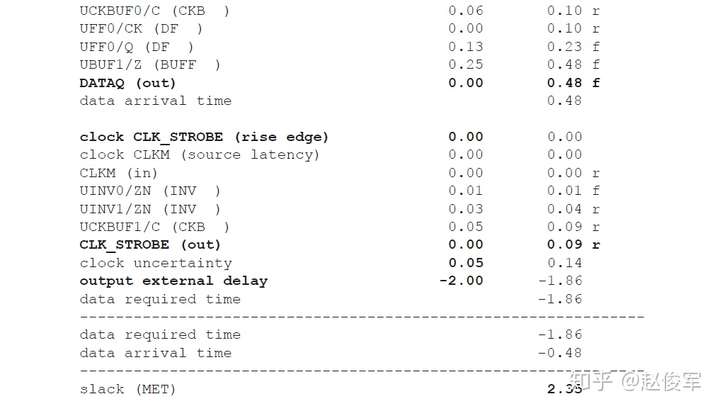
在上述最小路径分析中,DATAQ在0.48ns处到达,而CLK_STROBE在0.09ns处到达。由于要求是数据最早可以在CLK_STROBE之前2ns处发生改变,因此在考虑了50ps的时钟不确定度后,我们获得了2.35ns的正裕量。
源同步接口的另一个示例如图9-6所示。在这种情况下,输出时钟是主时钟的二分频,并且是数据同步接口的一部分。输出POUT被限制在QCLKOUT之前2ns和之后1ns之间才能进行改变。
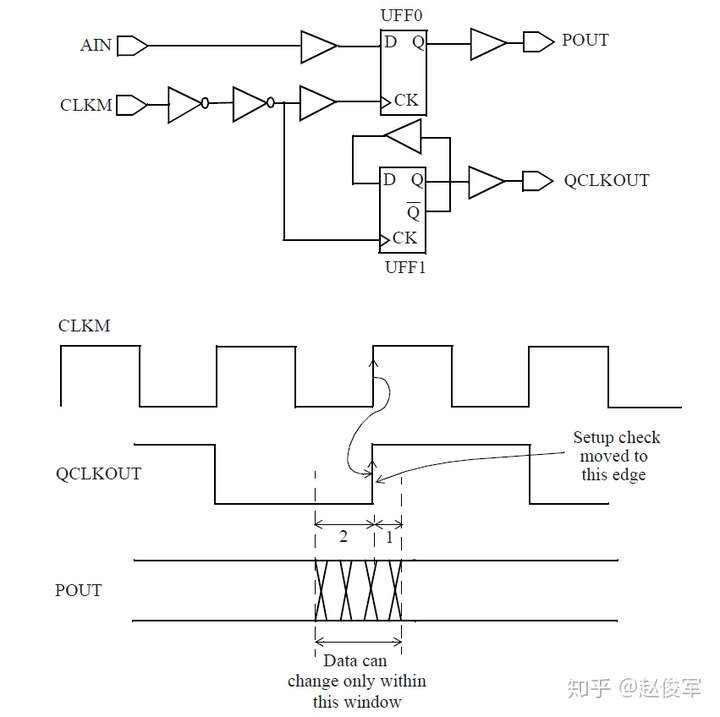
以下是这种情况的时序约束:
● create_clock -name CLKM -period 6 [get_ports CLKM]
● create_generated_clock -name QCLKOUT -source CLKM -divide_by 2 [get_ports QCLKOUT]
● set_multicycle_path 0 -setup -to [get_ports POUT]
● set_multicycle_path -1 -hold -to [get_ports POUT]
● set_output_delay -max -1.0 -clock QCLKOUT [get_ports POUT]
● set_output_delay -min +2.0 -clock QCLKOUT [get_ports POUT]
以下是建立时间检查的路径报告:
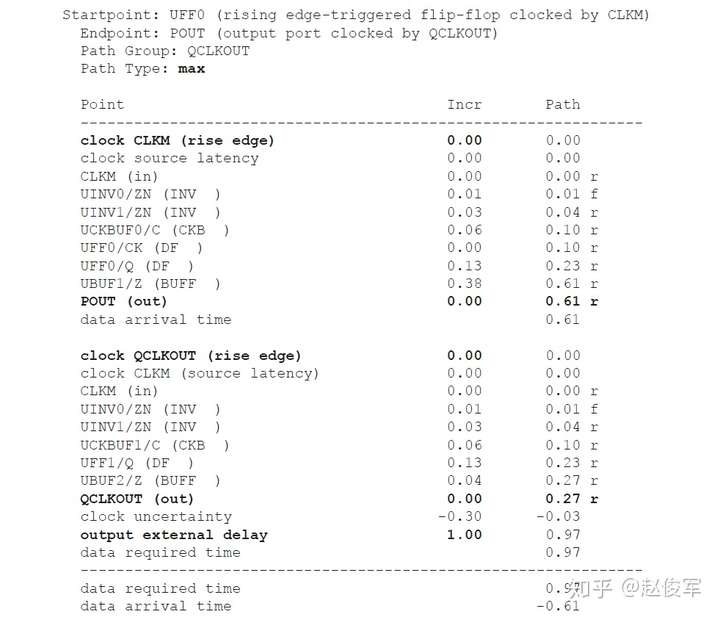

请注意,多周期路径约束已将建立时间检查沿向后移了一个周期,以便在同一时钟沿执行检查。输出POUT在0.61ns处变化,而时钟QCLKOUT在0.27ns处变化。基于在时钟沿1ns内允许变化的要求,并考虑0.30ns的时钟不确定度,我们可得0.36ns的正裕量。
接下来是保持时间检查的路径报告,用于检查时序窗口要求的另一个约束:
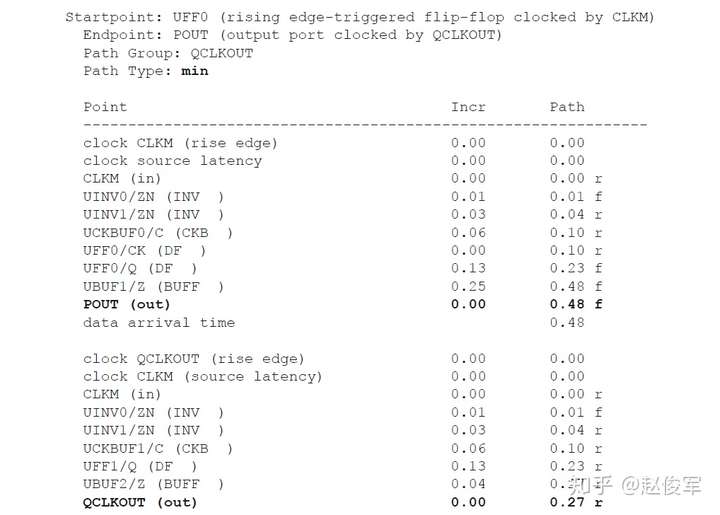

路径报告显示,数据是在QCLKOUT时钟边沿之前的2ns时序窗口内才发生改变的,并且有2.17ns的正裕量。
SRAM接口
SRAM接口中的所有数据传输仅发生在时钟的有效沿处,所有信号仅在有效时钟沿处由SRAM锁存或由SRAM发起。组成SRAM接口的信号包括命令(command)、地址(address)、控制输出总线(CAC)、双向数据总线(DQ)和时钟。在写周期(write cycle)中,DUA将数据写到SRAM中去,数据和地址从DUA传送到SRAM中去,并都在有效时钟沿处被锁存在SRAM中。在读周期(read cycle)中,地址信号仍然从DUA传送到SRAM中去,而数据信号则是由SRAM输出给DUA的。因此,地址和控制信号是单向的且方向为从DUA到SRAM,如图9-7所示。通常将延迟锁定环DLL(Delay-Locked Loop)放置在时钟路径中,DLL允许在必要时延迟时钟信号,以解决由于PVT和其它外部变化而导致接口上各种信号的延迟变化。通过考虑这些变化,在往返于SRAM的读周期和写周期中,都将有良好的时序裕度可用于数据传输。
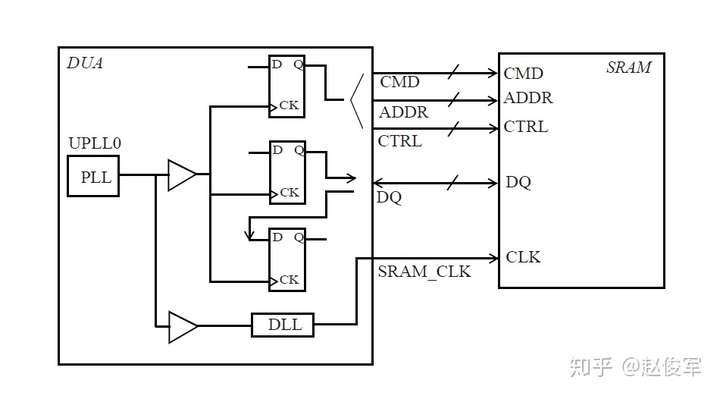
图9-8显示了典型SRAM接口的AC特性。请注意,图9-8中的数据输入和数据输出是指SRAM看到的方向。来自SRAM的Data out是DUA的输入,进入SRAM的Data in是DUA的输出。
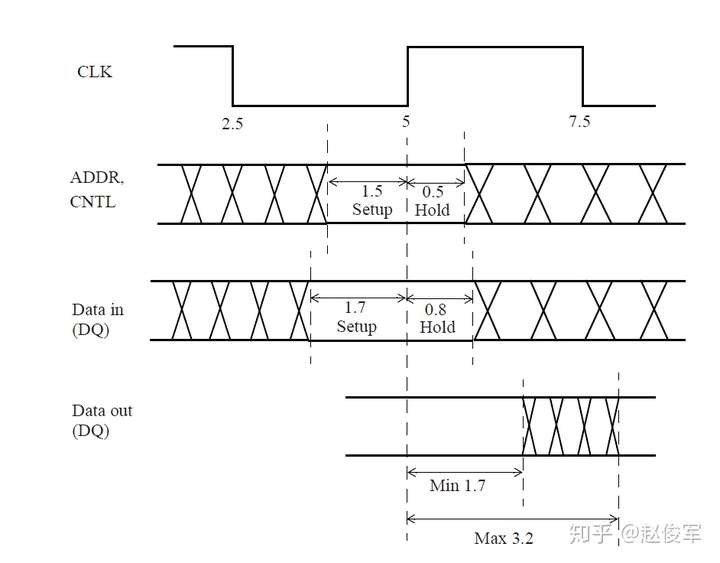
图9-8中的要求可以转换为用于DUA与SRAM之间接口的以下IO接口约束:
● create_clock -name PLL_CLK -period 5 [get_pins UPLL0/CLKOUT]
● create_generated_clock -name SRAM_CLK -source [get_pins UPLL0/CLKOUT] -divide_by 1 [get_ports SRAM_CLK]
● set_output_delay -max 1.5 -clock SRAM_CLK [get_ports ADDR[*]]
● set_output_delay -min -0.5 -clock SRAM_CLK [get_ports ADDR[*]]
● set_output_delay -max 1.7 -clock SRAM_CLK [get_ports DQ[*]]
● set_output_delay -min -0.8 -clock SRAM_CLK [get_ports DQ[*]]
● set_input_delay -max 3.2 -clock SRAM_CLK [get_ports DQ[*]]
● set_input_delay -min 1.7 -clock SRAM_CLK [get_ports DQ[*]]
以下是典型地址引脚的建立时间检查路径报告:
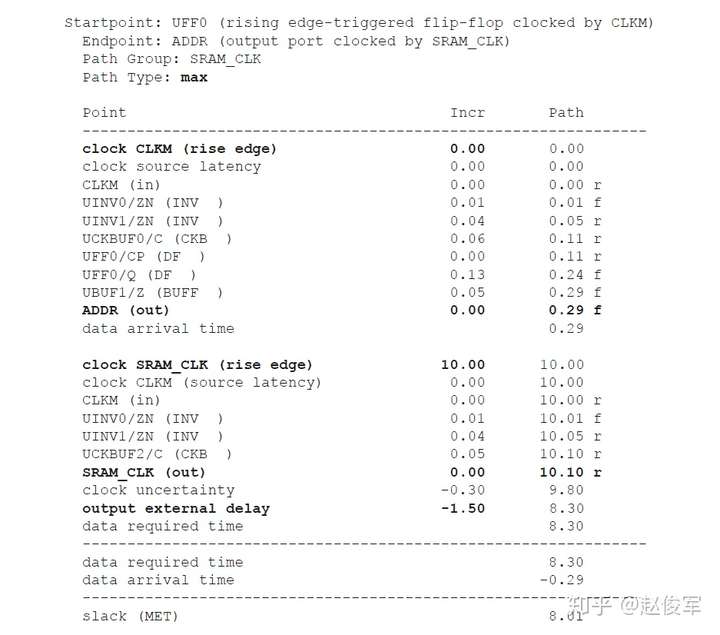
建立时间检查将验证地址信号是否在SRAM_CLK时钟沿之前1.5ns(SRAM地址引脚的建立时间)到达SRAM。
以下是相同地址引脚的保持时间检查路径报告:
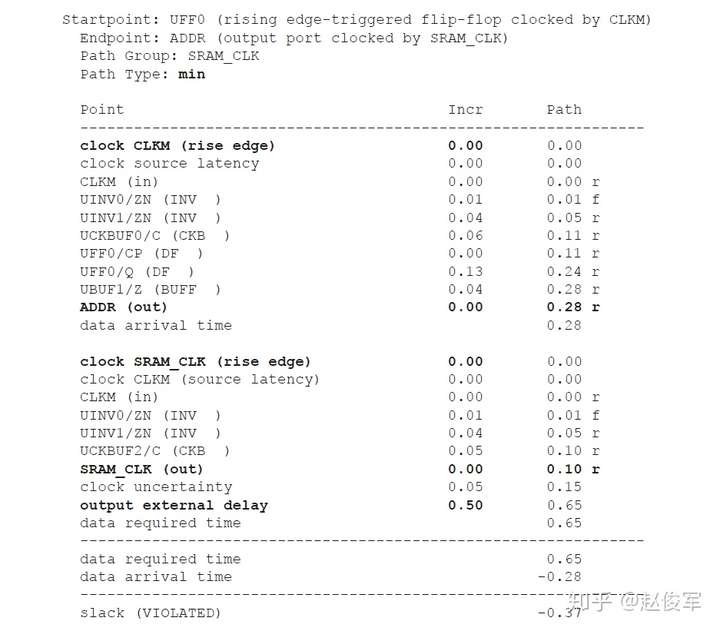
保持时间检查将验证地址信号在SRAM_CLK时钟沿之后是否继续保持稳定了0.5ns。
DDR SDRAM接口
DDR SDRAM接口可以看作是上一节中所介绍的SRAM接口的一种扩展。就像SRAM接口一样,有两条主要的总线,图9-9说明了DUA和SDRAM之间的总线及其方向。由命令、地址和控制引脚(通常称为CAC)组成的第一条总线将使用以下标准方案:在存储器时钟的一个时钟沿(或每个时钟周期一次)处发送信息。双向总线由DQ(数据总线)和DQS(数据选通脉冲)组成,DDR接口的不同之处就在于双向数据选通DQS。DQS选通脉冲可用于一组数据信号,这使得数据信号(每字节一个或每半字节一个)与选通脉冲的时序紧密匹配。如果时钟是整个数据总线共用的时钟,那么使用时钟信号进行这种紧密匹配可能不可行。双向选通信号DQS可用于读操作和写操作,并且在选通脉冲的两个边沿(下降沿和上升沿,或称双倍数据速率)上都可捕获数据。在SDRAM的读模式期间,DQ总线与数据选通引脚DQS(而不是存储器的时钟引脚)同步,即DQ和DQS从SDRAM中被输出时彼此是对齐的。而对于另一个方向,即当DUA发送数据时,DQS将相移90度。请注意,数据DQ和选通DQS的沿均来自DUA内部的存储器时钟。
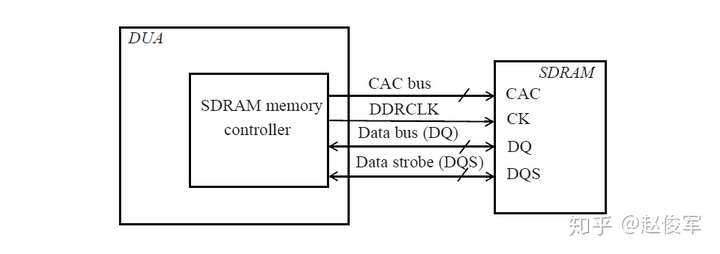
如上所述,对于一组DQ信号(4个或8个bit)存在一个数据选通DQS。这样做是为了使DQS和DQ的所有bit之间的偏斜平衡(skew balancing)要求更容易满足。例如,如果对于一个字节使用一个DQS,则一组中只需平衡9个信号(8个DQ和1个DQS),这比平衡72位的数据总线和时钟要容易得多。
上面的描述并不是对DDR SDRAM接口的完整说明,但足以说明这种接口的时序要求。
图9-10显示了典型DDR SDRAM接口中CAC总线(在DUA处)的AC特性。
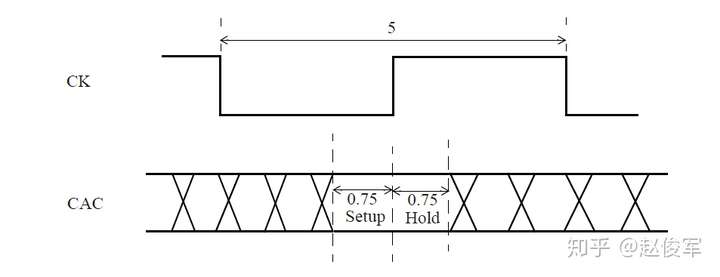
上述建立时间和保持时间的要求对应到CAC总线上的接口约束如下所示:
● create_generated_clock -name DDRCLK -source [get_pins UPLL0/CLKOUT] -divide_by 1 [get_ports DDRCLK]
● set_output_delay -max 0.75 -clock DDRCLK [get_ports CAC]
● set_output_delay -min -0.75 -clock DDRCLK [get_ports CAC]
在某些情况下,尤其是与无缓冲(unbuffered)存储器模块接口时,地址总线可能会比时钟驱动更大的负载。在这种情况下,地址信号对存储器的延迟要比时钟信号大,并且这种延迟差异可能会导致AC特性不同于图9-10中所示。
DQS和DQ的对齐方式在读周期和写周期中有所不同,以下小节将对此进行进一步探讨。
读周期
在读周期中,存储器输出的数据与DQS是边沿对齐(edge-aligned)的,如图9-11中波形所示。图中的DQ和DQS代表存储器引脚上的信号。数据(DQ)由存储器在DQS的每个沿上发出,并且DQ改变数据的时刻也与DQS的下降沿和上升沿对齐。
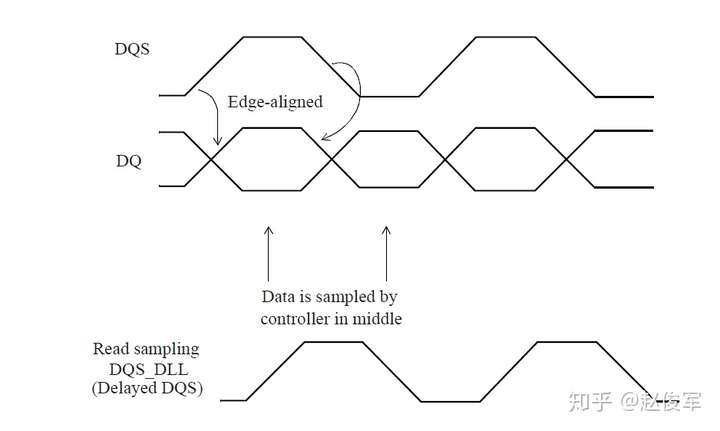
由于DQS选通信号和DQ数据信号彼此对齐,因此DUA内部的存储控制器(memory controller)通常使用DLL(或其它替代方法来实现四分之一周期延迟)来延迟DQS,从而使DQS的边沿对齐于数据有效窗口的中心。
即使DQ和DQS在存储器中彼此对齐,但DQ和DQS选通信号也可能无法再在DUA内部的存储控制器上对齐,这可能是由于IO缓冲器之间的延迟差以及PCB互连走线等因素所导致的。
图9-12中为基本的数据读取原理图。上升沿触发的触发器在DQS_DLL的上升沿捕获数据DQ,而下降沿触发的触发器在DQS_DLL的下降沿捕获数据DQ。虽然图中的DQ路径上没有DLL,但某些设计可能在数据路径上也会放置一个DLL。这样可以用来延迟信号(以解决由于PVT或互连走线长度或其它差异引起的变化),以便可以在数据有效窗口的中间准确地采样数据。
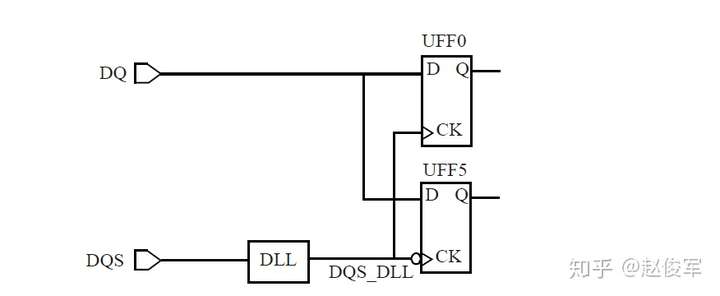
为了对存储控制器上的读接口进行约束,我们在DQS上定义了一个时钟,并相对于该时钟在数据上指定了输入延迟。
● create_clock -period 5 -name DQS [get_ports DQS]
假定存储器读接口以200MHz(当在两个时钟沿上都传输数据时相当于400Mbps)的频率进行工作,这对应于每2.5ns采样一次DQ数据信号。由于数据是在两个边沿上捕获的,因此需要为每个边沿分别指定输入约束。
● set_input_delay 0.4 -max -clock DQS [get_ports DQ]
● set_input_delay -0.4 -min -clock DQS [get_ports DQ]
● set_input_delay 0.35 -max -clock DQS -clock_fall [get_ports DQ]
● set_input_delay -0.35 -min -clock DQS -clock_fall [get_ports DQ]
● set_multicycle_path 0 -setup -to UFF0/D
● set_multicycle_path 0 -setup -to UFF5/D
输入延迟命令指定了DUA引脚上DQ和DQS沿之间的延迟差,即使这两个信号通常是从存储器中同时输出的,但由于不同存储器的规格,在时序上仍会存在偏差。因此,DUA内的控制器设计应考虑到两个信号之间可能存在偏斜(skew)。以下是两个触发器建立时间检查的路径报告。假设捕获触发器的建立时间要求为0.05ns、保持时间要求为0.03ns,且DLL延迟设置为1.25ns,即四分之一周期。
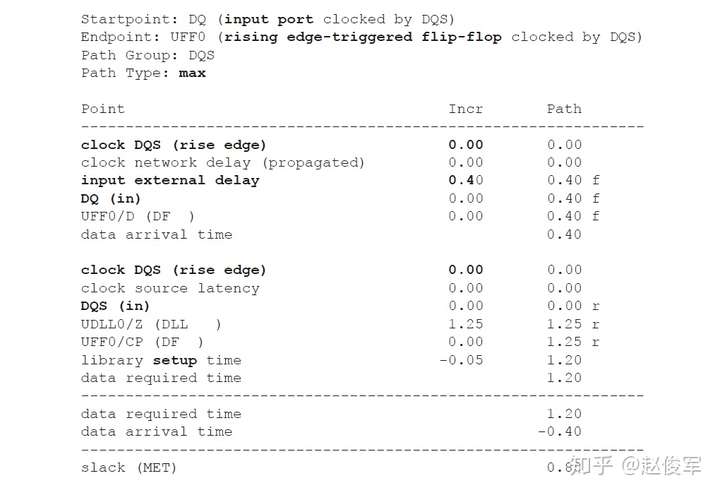


以下是保持时间检查的路径报告:
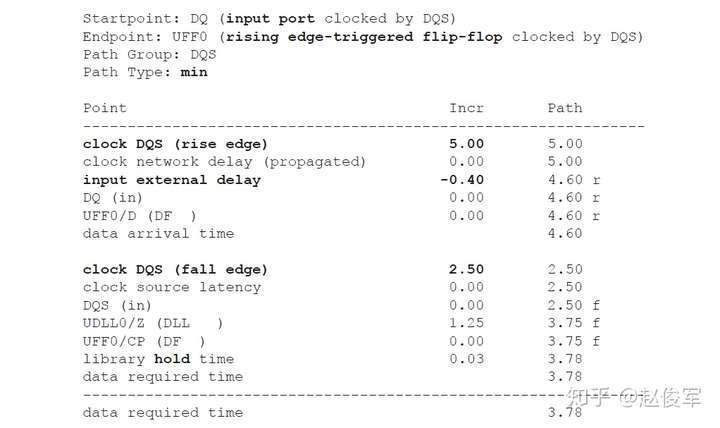

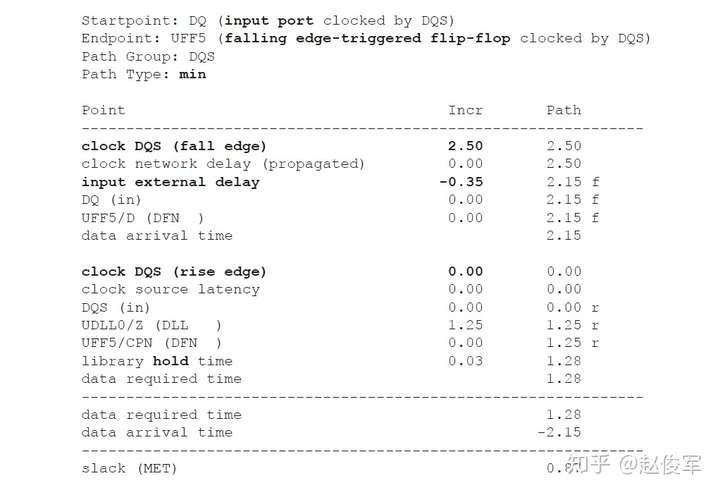
写周期
在写周期中,DQS沿会与从DUA内存储控制器输出的DQ信号相差四分之一周期,因此存储器可以直接使用DQS选通脉冲去捕获数据。
图9-13显示了存储器引脚上所需的波形,在存储器引脚处,DQS信号必须与DQ数据窗口的中心对齐。请注意,仍然是由于IO缓冲器延迟不匹配或者PCB互连走线的变化,仅在存储控制器(DUA内部)中对齐DQ和DQS还不足以使这些信号在SDRAM存储器引脚处真正的对齐。因此,DUA通常在写周期中使用额外的DLL去进行控制,以实现DQS和DQ信号之间所需的四分之一周期偏移(offset)。
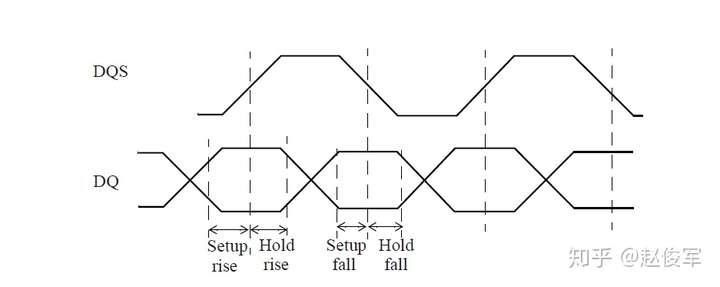
如何约束此模式的输出取决于控制器中时钟的生成方式,接下去我们考虑两种不同情况。
情况1:内部二倍频时钟
如果内部时钟是DDR时钟频率的两倍,则输出逻辑可以类似于图9-14中所示。DLL提供了一种必要时使DQS时钟偏斜的机制,从而满足存储器引脚上的建立时间和保持时间要求。在某些情况下,可以不使用DLL,而是使用负沿触发的触发器来获得90度的偏移。
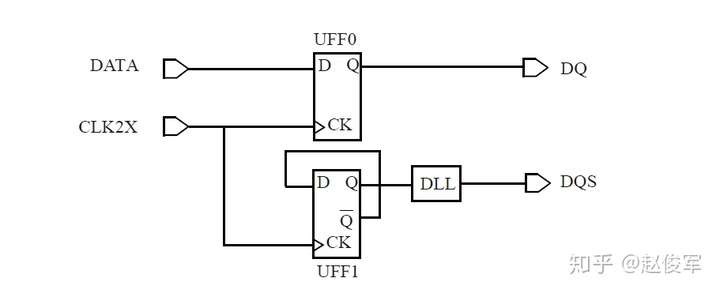
对于图9-14中所示情况,可以进行如下输出延迟约束:
● create_clock -period 3 [get_ports CLK2X]
● create_generated_clock -name pre_DQS -source CLK2X -divide_by 2 [get_pins UFF1/Q]
● create_generated_clock -name DQS -source UFF1/Q -edges {1 2 3} -edge_shift {1.5 1.5 1.5} [get_ports DQS]
DQ输出引脚上的时序必须相对于衍生时钟DQS进行约束。
假设DDR SDRAM的DQ和DQS引脚之间建立时间要求分别为DQ上升沿的0.25ns和下降沿的0.4ns。类似地,假设DQ引脚上升沿和下降沿的保持时间要求分别为0.15ns和0.2ns。DQS输出上的DLL延迟已设置为四分之一周期,即1.5ns,所有波形如下图9-15所示:
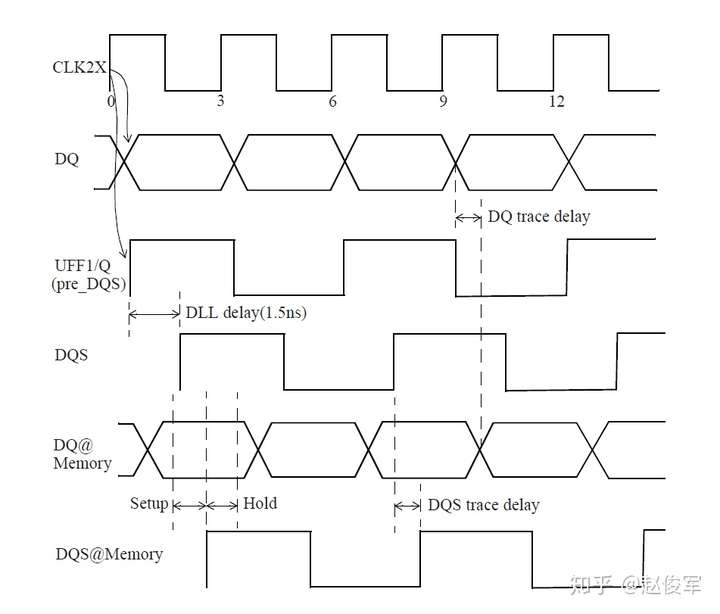
● set_output_delay -clock DQS -max 0.25 -rise [get_ports DQ]
● set_output_delay -clock DQS -max 0.4 -fall [get_ports DQ]
● set_output_delay -clock DQS -min -0.15 -rise [get_ports DQ]
● set_output_delay -clock DQS -min -0.2 -fall [get_ports DQ]
以下是通过输出DQ路径的建立时间检查报告。建立时间检查从0ns处发起DQ的CLK2X上升沿到1.5ns处的DQS上升沿进行。
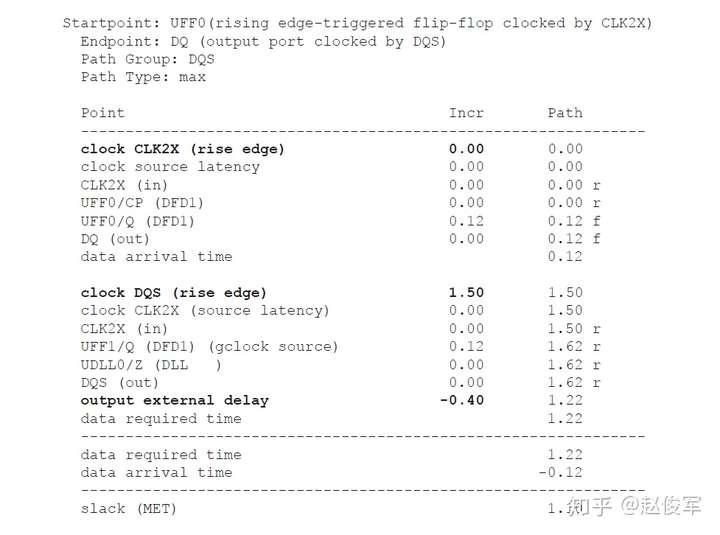
请注意,上述报告中的四分之一周期延迟出现在了时钟DQS上升沿的第一行中,而不是在DLL实例UDLL0的那行中。这是因为DLL延迟已被建模为了衍生时钟DQS定义的一部分,而不是DLL时序弧中的一部分。
以下是通过输出DQ路径的保持时间检查报告。保持时间检查从3ns处发起DQ的时钟CLK2X上升沿到1.5ns处的DQS前一个上升沿。
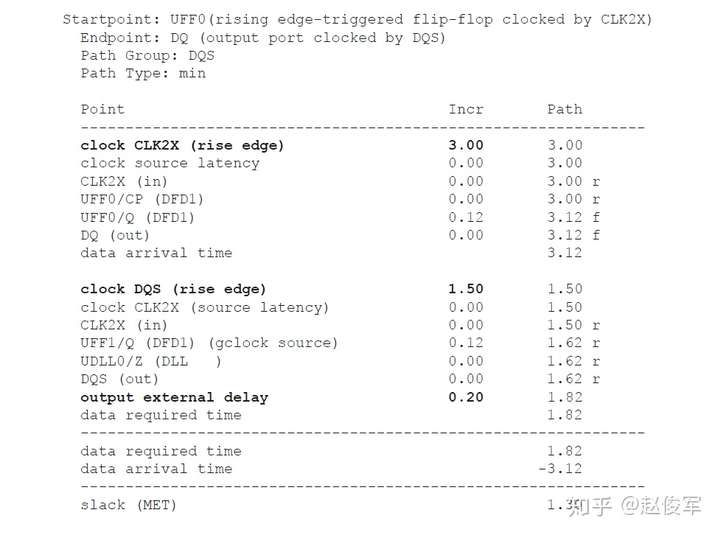
情况2:内部一倍频时钟
当内部只有一倍频时钟可用时,输出电路通常可能类似于图9-16所示的电路。
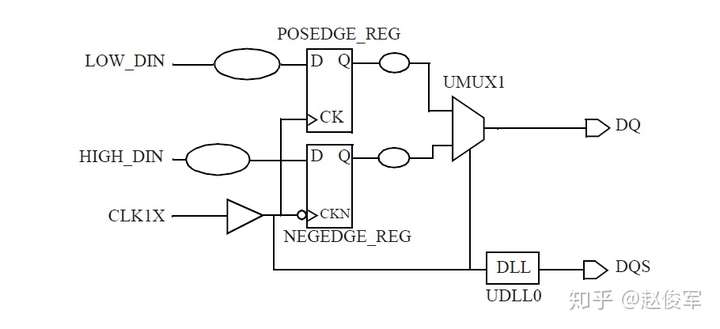
有两个触发器用于生成DQ数据:第一个触发器NEGEDGE_REG由时钟CLK1X的负沿触发,而第二个触发器POSEDGE_REG由时钟CLK1X的正沿触发。每个触发器会锁存适当的边沿数据,然后使用CLK1X作为多路复用器的选择信号来多路复用该数据:CLK1X为高电平时,触发器NEGEDGE_REG的输出发送到DQ;而当CLK1X为低电平时,触发器POSEDGE_REG的输出发送到DQ。因此,数据会在时钟CLK1X的两个边沿都到达输出DQ。请注意,每个触发器都有半个周期将数据传播到多路复用器的输入端,以确保在由CLK1X边沿选择输入数据之前,已在多路复用器的输入端口上准备好了输入数据。相关波形如图9-17所示。
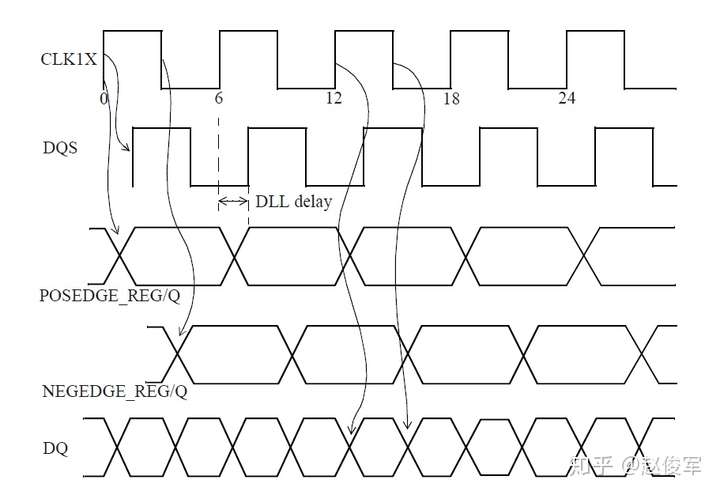
这种情况的输出延迟约束如下:
● create_clock -name CLK1X -period 6 [get_ports CLK1X]
● create_generated_clock -name DQS -source CLK1X -edges {1 2 3} -edge_shift {1.5 1.5 1.5} [get_ports DQS]
● set_output_delay -max 0.25 -clock DQS [get_ports DQ]
● set_output_delay -max 0.3 -clock DQS -clock_fall [get_ports DQ]
● set_output_delay -min -0.2 -clock DQS [get_ports DQ]
● set_output_delay -min -0.27 -clock DQS -clock_fall [get_ports DQ]
建立时间和保持时间检查可验证从多路复用器到输出的时序。建立时间检查之一是从多路复用器输入处的CLK1X上升沿(发起NEGEDGE_REG数据)到DQS的上升沿。另一个建立时间检查是从多路复用器输入处的CLK1X下降沿(发起POSEDGE_REG数据)到DQS的下降沿。同样,保持时间检查是从(与建立时间检查)相同的CLK1X边沿到DQS的前一个下降沿或上升沿。
以下是通过DQ端口的建立时间检查报告,该检查在(选择输出NEGEDGE_REG的)CLK1X的上升沿和DQS的上升沿之间进行。
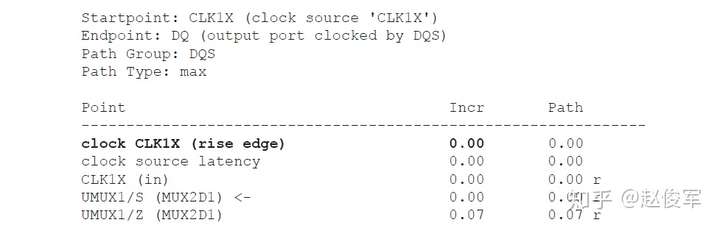
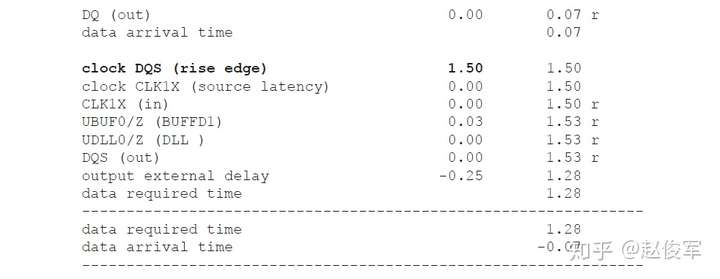

这是通过DQ端口的另一个建立时间检查报告,该检查在(选择输出POSEDGE_REG的)CLK1X的下降沿和DQS的下降沿之间进行。
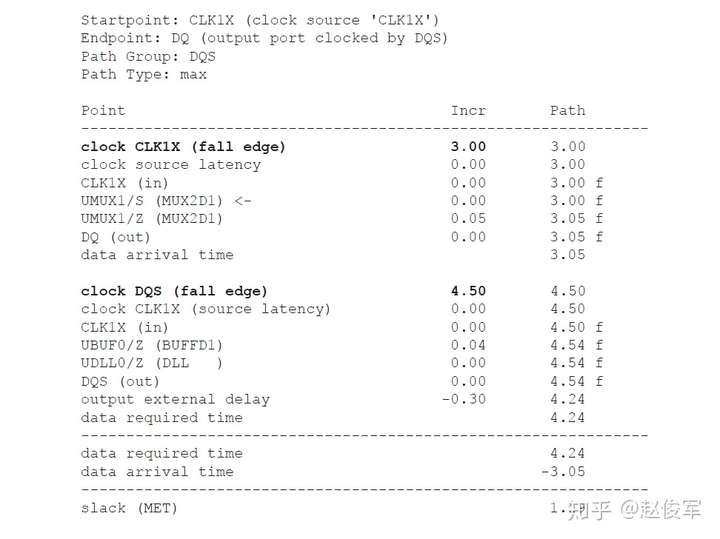
这是通过DQ端口的保持时间检查报告,该检查在CLK1X的上升沿和DQS的前一个下降沿之间进行。
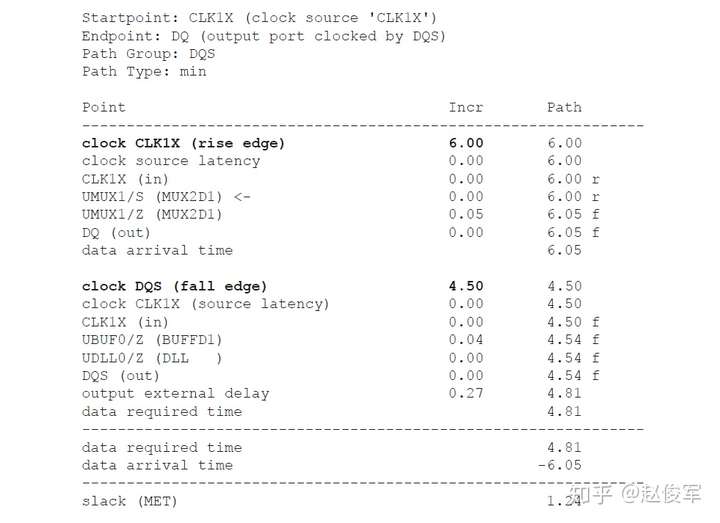
这是另一个通过DQ端口的保持时间检查报告,该检查在CLK1X的下降沿和DQS的前一个上升沿之间进行。

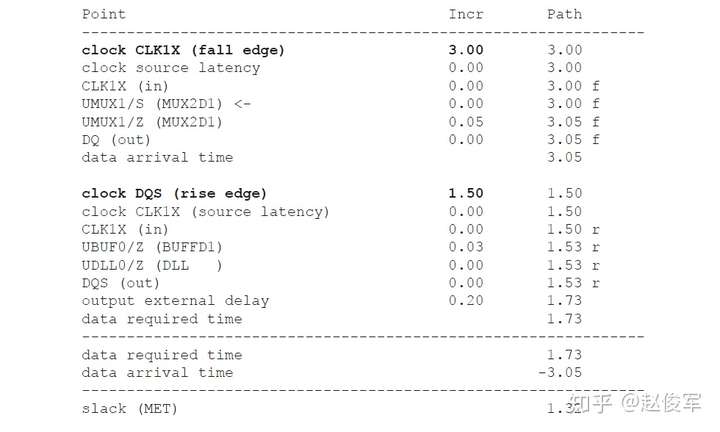
尽管以上接口时序分析已忽略了任何负载对输出的影响,但我们也可以指定额外的负载(使用set_load命令)来提高准确性。STA同样可以通过电路仿真来补充,以实现可靠的DRAM时序。
DDR接口的DQ和DQS信号通常在读模式和写模式下使用终端电阻ODT(On-Die Termination),以减少由于DRAM和DUA处的阻抗不匹配而引起的任何反射(reflection)。在使用ODT的情况下,用于STA的时序模型将无法提供足够的精度。设计人员可以使用另一种机制,例如详尽的电路级仿真,来验证信号完整性和DRAM接口的时序。
DAC接口
考虑下图9-18的一个典型DAC接口,其中高速时钟将数据传输到DAC的低速时钟接口。
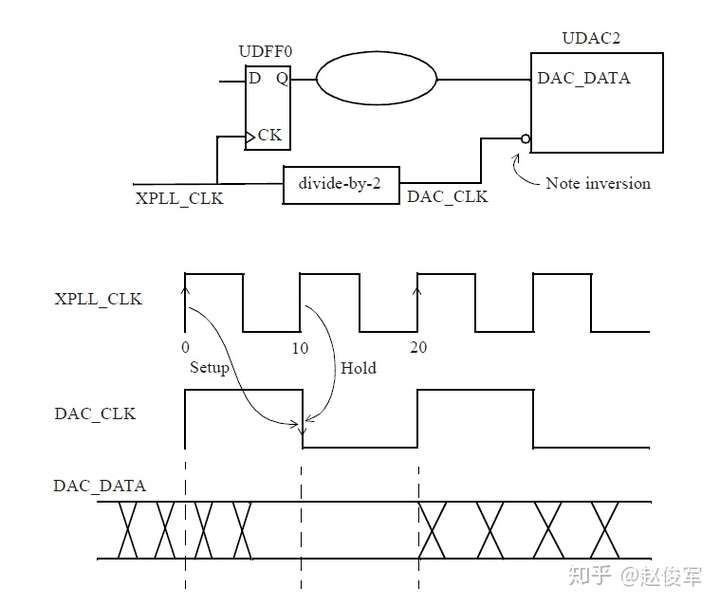
时钟DAC_CLK是时钟XPLL_CLK的2分频,DAC建立时间和保持时间检查针对的是DAC_CLK的下降沿。
在这种情况下,即使可以根据需要将从快时钟域到慢时钟域的接口指定为多周期路径,但也可以将建立时间视作单周期(XPLL_CLK)路径。如图9-18所示,XPLL_CLK的上升沿发起数据,而DAC_CLK的下降沿捕获数据。以下是建立时间检查的路径报告:
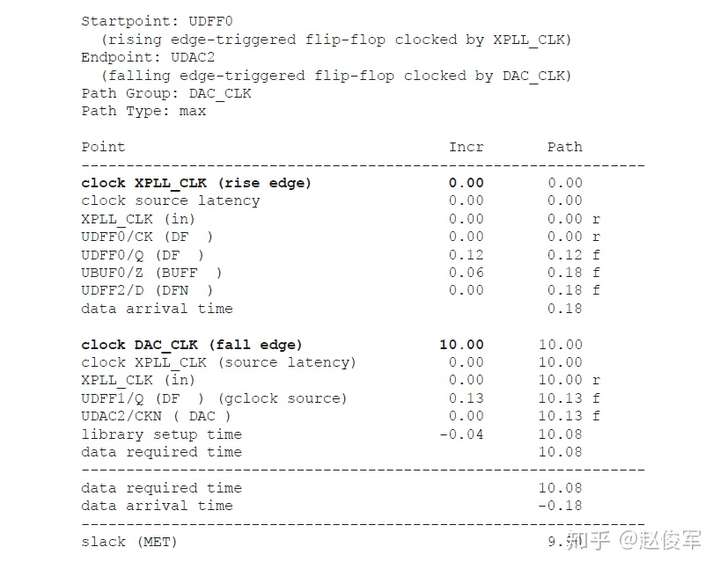
请注意,该接口是从较快的时钟域到较慢的时钟域,因此如有必要,完全可以将其设置为两周期路径。
以下是保持时间检查的路径报告:
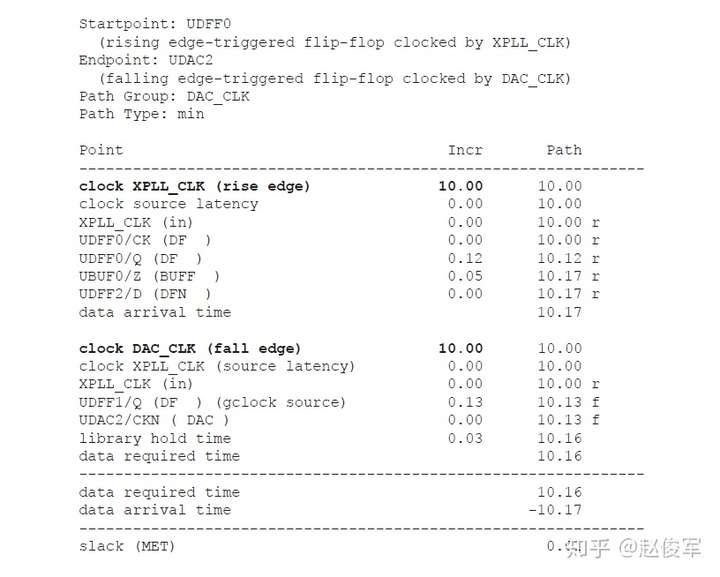
保持时间检查是在建立时间捕获沿之前一个周期完成的。在这种接口情况下,最关键的保持时间检查是在发起沿和捕获沿重合处执行的,这在以上保持时间检查的报告中可以看出。
鲁棒性检查
本章节将介绍特殊的STA分析,例如时间借用(time borrowing)、时钟门控(clock gating)和非时序(non-sequential)检查。此外,还介绍了高级STA概念,例如片上变化(on-chip variation)、统计时序(statistical timing)以及功耗和时序之间的折中。
片上变化
通常,工艺和各环境参数在芯片的不同部分上可能不一致。由于工艺差异,芯片上不同部分的相同MOS晶体管可能没有相似的特性,这些差异是由于芯片内部的工艺差异引起的。请注意,多个制造批次中的工艺参数差异可能会覆盖慢工艺到快工艺(2.10节中所介绍)。在本节中,我们讨论的是对一个芯片上可能存在的工艺差异(称为局部工艺差异)的分析,该差异远小于多个制造批次之间的差异(称为全局工艺差异)。
除了工艺参数的变化之外,设计中不同部分可能还会存在不同的电源电压和温度。因此,同一芯片的两个区域可能不在相同的PVT条件下。这些差异可能是由许多因素引起的,包括:
● 会影响局部电源电压的沿芯片区域的IR压降变化;
● PMOS或NMOS器件的电压阈值变化;
● PMOS或NMOS器件的沟道长度变化;
● 由于局部热点造成的温度变化;
● 互连金属刻蚀或厚度变化会影响互连电阻或电容。
上述的PVT变化被称为片上变化(OCV),这些变化会影响芯片不同部分的走线延迟和单元延迟。如上所述,OCV建模并不是要对芯片与芯片之间可能的PVT变化进行建模,而是要对单个芯片内局部可能的PVT变化进行建模。OCV带来的影响通常在时钟路径上更为明显,因为时钟路径在芯片中传播的距离更长。解决局部PVT变化的一种方法是在STA期间包含OCV分析。前面各章中所介绍的静态时序分析能够获得特定时序角(timing corner)的时序,但没有对芯片上的变化进行建模。由于时钟和数据路径可能受到不同OCV的影响,因此时序验证可以通过使数据发起路径和捕获路径的PVT条件稍有不同来对OCV的影响进行建模。通过降额(derate)特定路径的延迟就可以对OCV带来的影响进行建模,即首先使这些路径更快或更慢,然后通过这些变化来验证设计的性能。可以降额单元延迟或走线延迟,或同时降额两者,以模拟OCV的影响。
现在,我们来讨论如何完成OCV降额处理以进行建立时间检查。考虑图10-1中所示逻辑,其中PVT条件可能随芯片的不同区域而变化。当发起时钟路径和数据路径的OCV条件导致延迟最大、而捕获时钟路径的OCV条件导致延迟最小时,此时的建立时间检查最为严格。请注意,此处最小和最大延迟是由于芯片上局部PVT的变化。
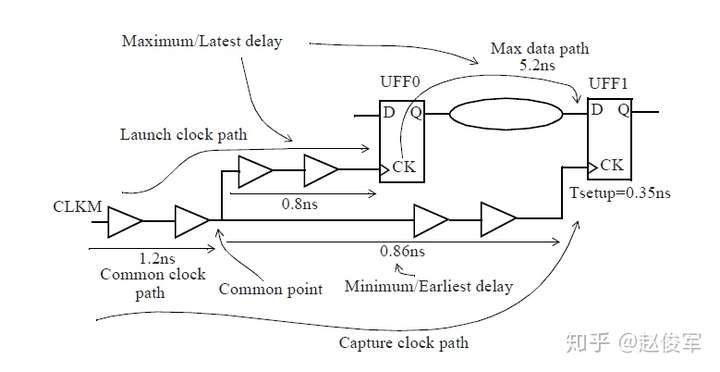
对于此示例,以下是建立时间检查,注意此处还不包括任何用于降额延迟的OCV设置:
● LaunchClockPath + MaxDataPath <= ClockPeriod + CaptureClockPath - Tsetup_UFF1
● Minimum clock period = LaunchClockPath + MaxDataPath - CaptureClockPath + Tsetup_UFF1
● LaunchClockPath = 1.2 + 0.8 = 2.0
● MaxDataPath = 5.2
● CaptureClockPath = 1.2 + 0.86 = 2.06
● Tsetup_UFF1 = 0.35
● Minimum clock period = 2.0 + 5.2 - 2.06 + 0.35 = 5.49ns
以上路径延迟对应于没有任何OCV降额的延迟值,我们可以使用set_timing_derate命令来对单元和网络延迟进行降额处理。比如以下命令:
● set_timing_derate -early 0.8
● set_timing_derate -lata 1.1
上述命令将最小/最短/最早路径的延迟降低了20%,并将最大/最长/最迟路径的延迟增加了10%。长路径的延迟(例如,用于建立时间检查的数据路径和发起时钟路径或用于保持时间检查的捕获时钟路径)将乘以使用-late选项指定的降额值,而短路径的延迟(例如,用于建立时间检查的捕获时钟路径或用于保持时间检查的数据路径和发起时钟路径)将乘以使用-early选项指定的降额值。如果未指定降额系数,则假定值为1.0。
降额系数将统一应用于所有网络延迟和单元延迟,如果某个应用场景中需要保证单元和网络的降额系数不同,则可以在set_timing_derate命令中使用-cell_delay和-net_delay选项。
● set_timing_derate -cell_delay -early 0.9
● set_timing_derate -cell_delay -late 1.0
● set_timing_derate -net_delay -early 1.0
● set_timing_derate -net_delay -late 1.2
可以使用-cell_check选项来对单元检查(例如建立时间和保持时间)的延迟进行降额。使用此选项时,使用set_output_delay指定的任何输出延迟也将被降额,因为此约束也是输出建立时间要求的一部分。但是,对于使用set_input_delay指定的输入延迟,是不会被降额的。
● set_timing_derate -early 0.8 -cell_check
● set_timing_derate -late 1.1 -cell_check
-clock选项仅将降额应用于时钟路径。同样,-data选项仅将降额应用于数据路径。
● set_timing_derate -early 0.95 -clock
● set_timing_derate -late 1.05 -data
现在,我们将以下降额约束应用于图10-1的示例:
● set_timing_derate -early 0.9
● set_timing_derate -late 1.2
● set_timing_derate -late 1.1 -cell_check
在以上降额约束的情况下,我们可以进行如下计算:
● LaunchClockPath = 2.0 * 1.2 = 2.4
● MaxDataPath = 5.2 * 1.2 = 6.24
● CaptureClockPath = 2.06 * 0.9 = 1.854
● Tsetup_UFF1 = 0.35 * 1.1 = 0.385
● Minimum clock period = 2.4 + 6.24 - 1.854 + 0.385 = 7.171ns
在上面的建立时间检查中,由于时钟树的公共时钟路径(图10-1)具有1.2ns的延迟,而发起时钟和捕获时钟路径上的降额有所不同,因此存在差异。时钟树的这一部分对于发起时钟和捕获时钟路径都是通用的,因此不应进行不同的降额。对发起和捕获时钟路径应用不同的降额是过于悲观的,因为在实际上时钟树的这一部分实际上仅处于一个PVT条件下,即最大路径或最小路径(或介于两者之间),但绝不会同一时间处在两种不同PVT条件下。由于对时钟树的公共部分应用了不同降额系数而引起的悲观被称为“公共路径悲观度”CPP(Common Path Pessimism),在分析过程中应将其消除。CPPR(Common Path Pessimism Removal)表示“公共路径悲观度消除”,通常在路径报告中作为单独的条目列出,它也被标记为时钟收敛悲观度消除CRPR(Clock Reconvergence Pessimism Removal)。
CPPR消除了时序分析中发起时钟路径和捕获时钟路径之间的人为悲观情绪。如果同一个时钟既驱动捕获触发器又驱动发起触发器,那么时钟树很可能会在分支之前共享一条公共路径。CPP本身是沿时钟树公共路径的延迟之差,这是由于发起和捕获时钟路径的降额系数不同所致。时钟信号在公共点的最小到达时间和最大到达时间之间的差即为CPP。公共点(Common Point)的定义为时钟树公共部分中最后一个单元的输出引脚。
● CPP = LatestArrivalTime @CommonPoint - EarliestArrivalTime @CommonPoint
上述分析中的“最晚时间”和“最早时间”是指在特定工艺角(Corner)下的OCV降额值,例如最坏情况下的慢速(Worst-Case-Slow)或最佳情况下的快速(Best-Case-Fast)。对于图10-1的示例:
● LatestArrivalTime @CommonPoint = 1.2 * 1.2 = 1.44
● EarliestArrivalTime @CommonPoint = 1.2 * 0.9 = 1.08
● CPP = 1.44 - 1.08 = 0.36ns
● Minimum clock period = 7.171 - 0.36 = 6.811ns
对于前面的设计示例,应用OCV降额会把最小时钟周期从5.49ns增加到6.811ns,这说明了通过这些降额系数建模的OCV变化会降低设计的最大工作频率。
最差PVT条件下的OCV分析
如果在最差情况(worst-case)的PVT条件下执行建立时间检查,则在较晚路径(late path)上就无需降额了,因为它们已经是最差的情况了。但是,可以通过将特定的降额系数应用于较早路径(early path)来使那些路径更快,例如使较早路径加速10%。在最差情况下,降额约束可能如下所示:
● set_timing_derate -early 0.9
● set_timing_derate -late 1.0
上述降额约束可用于在最差情况的慢速工艺角下进行最大路径(或建立时间)检查。因此,较晚路径的OCV降额系数设置为1.0,以使其不会超出最差情况的慢速工艺角。
接下来介绍在最差情况的慢速工艺角下进行建立时间检查的示例。为捕获时钟路径指定了以下降额约束:
● set_timing_derate -early 0.8 -clock
以下是在最差情况的慢速工艺角下执行的建立时间检查路径报告。较晚路径使用的降额系数在报告中为Max Data Paths Derating Factor和Max Clock Paths Derating Factor,而较早路径使用的降额系数在报告中为Min Clock Paths Derating Factor。

请注意,捕获时钟路径的延迟已被降低了20%:可参考时序报告中的单元UCKBUF0,在发起路径中它有56ps的延迟,而在捕获路径中仅有45ps的延迟。单元UCKBUF0处在公共时钟路径上,也就是既在捕获时钟路径上又在发起时钟路径上。由于公共时钟路径不能有不同的降额系数,因此该公共路径的延迟差56ps-45ps = 11ps将会被补偿校正,这可以从clock reconvergence pessimism那行中看出。总而言之,如果要比较此路径报告降额与不降额的差别的话,则可能会注意到只有捕获时钟路径的单元和网络延迟被降低了。
保持时间检查的OCV
现在,我们将介绍如何对保持时间检查进行降额处理。考虑如图10-2所示的逻辑,如果整个芯片上的PVT条件不同,则当发起时钟路径和数据路径具有导致延迟最小的OCV条件(即最早的发起时钟),且保持时钟路径具有导致延迟最大的OCV条件(即最晚的捕获时钟)时,保持时间检查的最差情况就会发生。
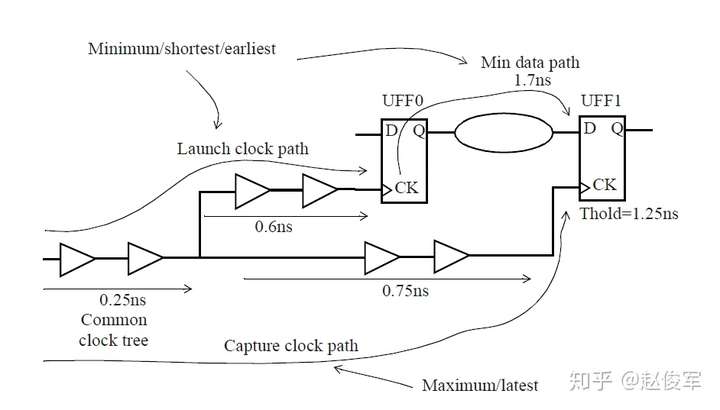
以下表达式即为此示例所要执行的保持时间检查:
● LaunchClockPath + MinDataPath - CaptureClockPath - Told_UFF1 >= 0
将图10-2中的延迟值应用于上述表达式,我们可得(不应用任何降额系数):
● LaunchClockPath = 0.25 + 0.6 = 0.85
● MinDataPath = 1.7
● CaptureClockPath = 0.25 + 0.75 = 1.00
● Thold_UFF1 = 1.25
这意味着检查结果如下:
● 0.85 + 1.7 - 1.00 - 1.25 = 0.3ns >= 0
因此可得结论:保持时间没有违例。
应用以下降额约束:
● set_timing_derate -early 0.9
● set_timing_derate -late 1.2
● set_timing_derate -early 0.95 -cell_check
重新计算的结果如下:
● LaunchClockPath = 0.85 * 0.9 = 0.765
● MinDataPath = 1.7 * 0.9 = 1.53
● CaptureClockPath = 1.00 * 1.2 = 1.2
● Thold_UFF1 = 1.25 * 0.95 = 1.1875
● Common Clock Path Pessimism = 0.25 * (1.2 - 0.9) = 0.075
由于在公共时钟路径上应用不同降额系数而导致的悲观度也进行了计算,这个值将被补偿然后再进行保持时间检查。保持时间的检查将变为:
● 0.765 + 1.53 - 1.2 - 1.1875 + 0.075 = -0.0175ns
结果小于0,因此表明对路径应用了OCV降额系数之后保持时间违例了。
通常,保持时间检查是在最佳情况的快速PVT角下执行的。在这种情况下,较早路径无需降额,因为这些路径已经是最快的路径了。但是,可以通过将特定的降额系数应用于较晚路径来使那些路径更慢,例如使较晚路径变慢20%。在最佳情况下,降额约束可能如下所示:
● set_timing_derate -early 1.0
● set_timing_derate -late 1.2
对于图10-2中的示例:
● LatestArrivalTime @CommonPoint = 0.25 * 1.2 = 0.30
● EarliestArrivalTime @CommonPoint = 0.25 * 1.0 = 0.25
因此此时公共路径悲观度为:
● 0.30 - 0.25 = 0.05ns
这是使用此降额约束的设计示例的保持时间检查路径报告:
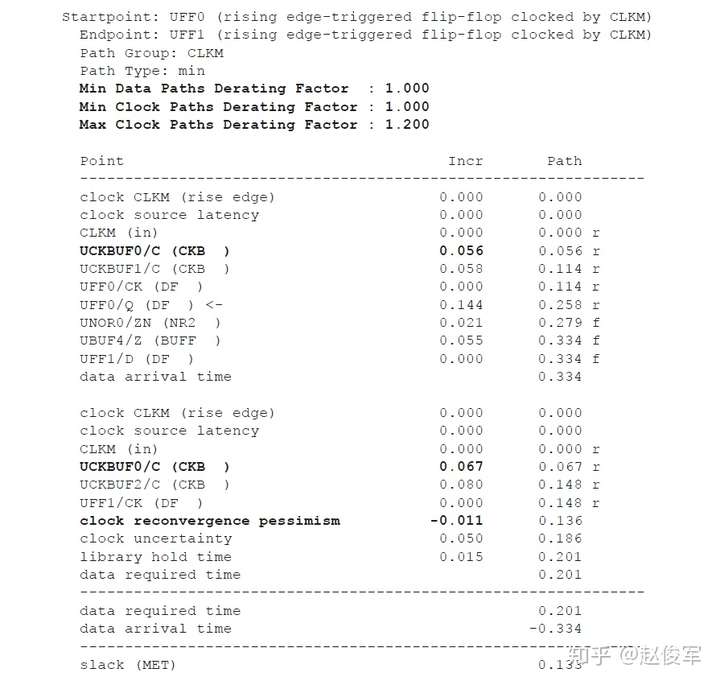
请注意,较晚路径的延迟增加了20%,而较早路径保持不变。来看一下单元UCKBUF0的延迟,其在发起时钟路径上的延迟为56ps,而在捕获时钟路径上的延迟为67ps,增加了20%。UCKBUF0是公共时钟树上的单元,因此由于此公共时钟树上的降额系数不同而引入的悲观度为67ps-56ps = 11ps,这在clock reconvergence pessimism一行中得到了补偿校正。
时间借用
时间借用(Time Borrowing)技术(也称为周期窃取cycle stealing技术)发生在锁存器(Latch)上。在锁存器中,时钟的一个边沿会使锁存器透明,即这个沿打开了锁存器,使得锁存器的输出与数据输入相同,该时钟沿被称为打开沿(opening edge)。时钟的另一个沿会关闭锁存器,也就是说,输入数据的任何改变在锁存器的输出处都无效,此时钟沿被称为关闭沿(closing edge)。
通常,应在时钟有效沿之前就在锁存器输入处准备好数据。但是,由于锁存器在时钟处于有效状态时是透明的,因此数据可以晚于有效时钟沿到达,也就是说,它可以从下一个周期借用时间。如果这样借用了时间,则会减少可用于下一级(锁存器到另一个时序单元)的时间。
图10-3给出了使用有效上升沿借用时间的示例。如果在锁存器10ns处的CLK上升沿(打开沿)之前的时间A处数据DIN就已经准备好了,则数据在锁存器打开时会流向锁存器的输出。如果数据DIN在时间B处(延迟)到达,则它将借用时间Tb。但是,这减少了从锁存器到下一个触发器UFF2的可用时间,只有时间Ta可用,而不再是完整的时钟周期。
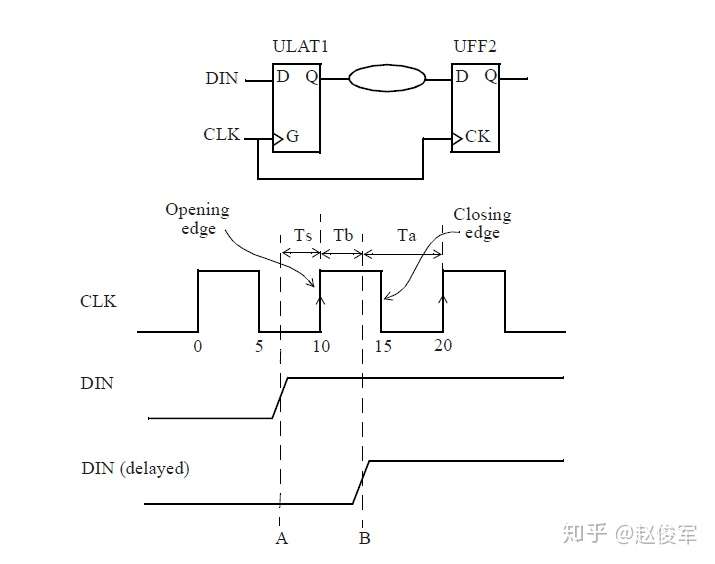
锁存器的时序的第一条规则是:如果数据在锁存器的打开沿之前到达,则寄存器行为将与触发器完全一样。在打开沿捕获数据,而同一时钟沿又将发起数据,作为下一条时序路径的起点。
第二条规则适用的情况是:数据在锁存器为透明状态时(在打开沿和关闭沿之间)到达。锁存器的输出将被用作下一级时序路径的起点,而不是时钟引脚。在锁存器处结束的时序路径所借用的时间将决定下一级的发起时间。
在锁存器的关闭沿之后到达的数据信号是时序违例的。图10-4显示了正裕量、零裕量和负裕量(即发生违例时)所分别对应的数据到达时序区域。
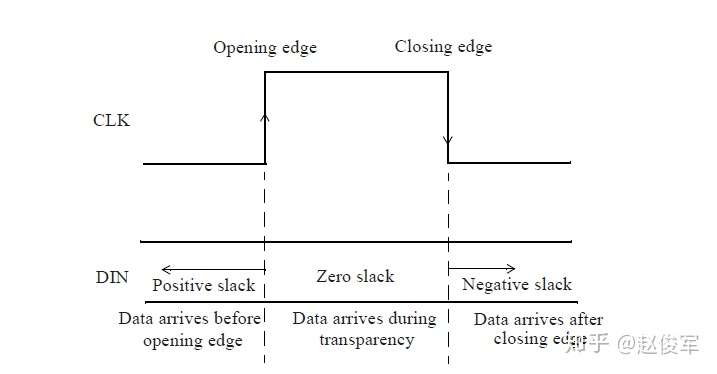
图10-5(a)中为锁存器到下一级触发器的半周期路径,图10-5(b)描绘了时间借用的波形,时钟周期为10ns。UFF0在0时刻发起数据,但数据路径需要7ns。锁存器ULAT1在5ns时打开。因此,向ULAT1到UFF1的路径借用了2ns,而ULAT1到UFF1的可用时间仅为3ns(5ns-2ns)。
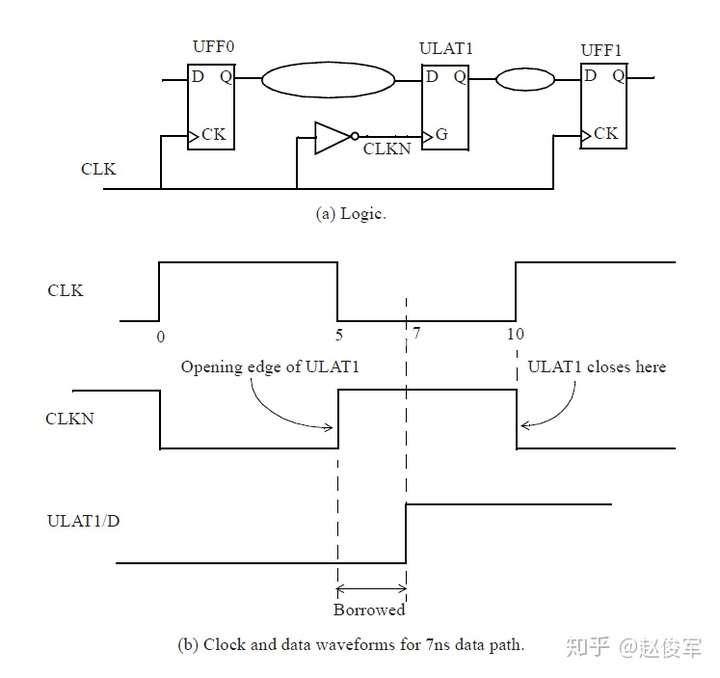
接下来,我们将介绍图10-5(a)锁存器示例的三组不同时序报告,以说明从下一级路径借用的不同时间量。
没有借用时间
若从触发器UFF0到锁存器ULAT1的数据路径延迟小于5ns,则建立时间检查的路径报告如下:


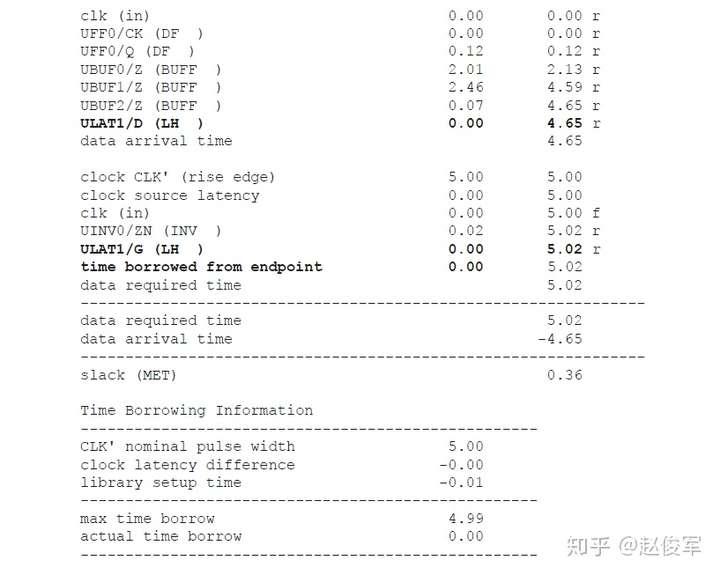
在这种情况下,由于数据在锁存器打开之前及时到达了锁存器ULAT1,因此无需借用时间。
借用了时间
若从触发器UFF0到锁存器ULAT1的数据路径延迟大于5ns,则建立时间检查的路径报告如下:


在这种情况下,由于锁存器透明时数据是可用的,因此会从后续路径借用所需的1.81ns,然后仍能满足时序要求。以下是后续路径的路径报告,其中显示了前一条路径借用的1.81ns:

时序违例的例子
在这种情况下,数据路径延迟要大得多,并且数据在锁存器关闭之后才能到达,这显然是时序违例的。
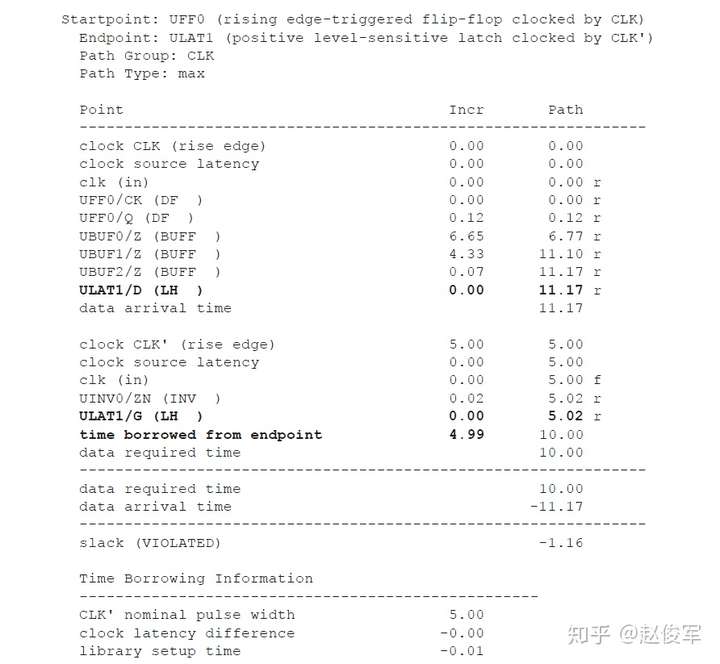

数据引脚到数据引脚检查
建立时间和保持时间检查也可以在任意两个数据引脚之间进行,这两个都不是时钟引脚。一个引脚为约束引脚(constrained pin),其作用类似于触发器的数据引脚,而另一个引脚为相关引脚(related pin),其作用类似于触发器的时钟引脚。关于触发器建立时间检查的一个重要区别是,数据到数据的建立时间检查是在与发起沿相同的沿上执行的(不同于触发器的常规建立时间检查,其中捕获时钟边沿通常会距离发起时钟沿一个周期)。因此,数据到数据的建立时间检查也称为零周期检查(zero-cycle checks)或同周期检查(same-cycle checks)。
使用set_data_check命令可以指定数据到数据的检查,SDC约束命令示例如下:
● set_data_check -from SDA -to SCTRL -setup 2.1
● set_data_check -from SDA -to SCTRL -hold 1.5
参见图10-6,SDA是相关引脚,而SCTRL是约束引脚。建立时间数据检查规定SCTRL应该在相关引脚SDA的边沿之前至少2.1ns到达,否则即为数据到数据的建立时间检查违例。保持时间数据检查规定SCTRL应该在SDA之后至少1.5ns到达,如果约束引脚的信号早于该时刻到达,即为数据到数据的保持时间检查违例。
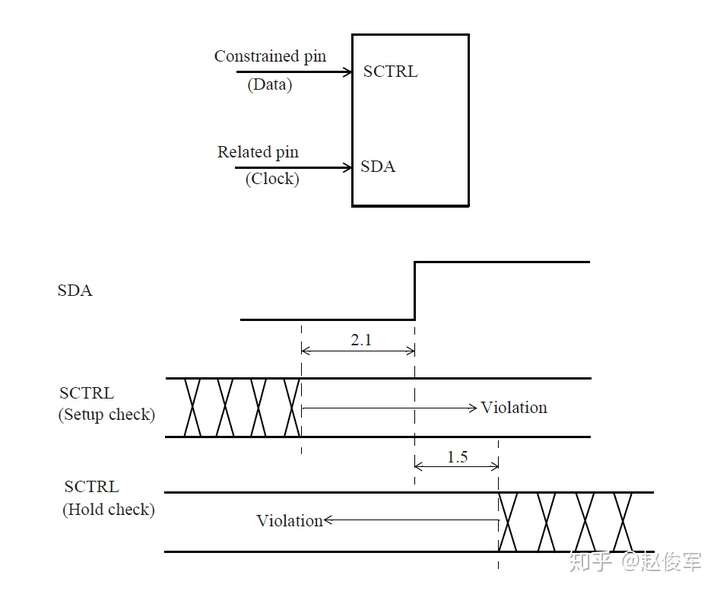
此检查在定制设计的模块中很有用,在定制设计的模块中很有可能会要去约束一个信号相对于另一个信号的到达时间。一种常见情况是由使能信号选通的数据信号,此时需要确保当数据信号到达时使能信号保持稳定。
考虑图10-7中所示的与门单元。我们假设要求是确保PNA在PREAD上升沿之前1.8ns到达,并且在PREAD上升沿之后1.0ns内不应发生改变。在此示例中,PNA是约束引脚,而PREAD是相关引脚,对应的波形如图10-7所示。
对于这样的时序要求,可以使用数据到数据的建立时间和保持时间检查:
● set_data_check -from UAND0/A1 -to UAND0/A2 -setup 1.8
● set_data_check -from UAND0/A1 -to UAND0/A2 -hold 1.0
以下是建立时间检查路径报告:
建立时间在报告中显示为data check setup time。以上时序违例的报告表明PREAD至少需要延迟1.72ns,以确保PNA在PREAD之前1.8ns能够到达,这是我们的建立时间要求。
数据到数据建立时间检查很重要的一点是,约束引脚和相关引脚的发起时钟沿都来自同一时钟周期。因此,在报告中请注意,捕获沿(UDFF0 / CK)的起始时间为0ns,而不是一个周期之后的时钟沿(通常在报告中看到的都是这种情况)。
零周期(zero-cycle)建立时间检查会导致保持时间检查与其它保持时间检查有所不同,保持时间检查将不再位于同一时钟沿。以下是CLKPLL的时钟定义,将用于下面的保持时间路径报告:
● create_clock -name CLKPLL -period 10 -waveform {0 5} [get_ports CLKPLL]

注意,在保持时间检查中,相关引脚的发起沿比约束引脚的发起沿要早一个周期。这是因为根据定义,通常在建立时间捕获沿之前的一个周期执行保持时间检查。由于数据到数据建立时间检查的约束引脚和相关引脚的时钟沿相同,因此会在发起沿之前一个周期执行保持时间检查。
在某些情况下,设计人员可能要求在同一时钟周期上执行数据到数据的保持时间检查。相同周期的保持时间要求意味着要将用于相关引脚的时钟沿移回约束引脚的时钟沿处。可以通过指定多周期保持时间为-1来实现:
● set_multicycle_path -1 -hold -to UAND0/A2
以下是带有多周期约束的上述示例的保持时间检查路径报告:

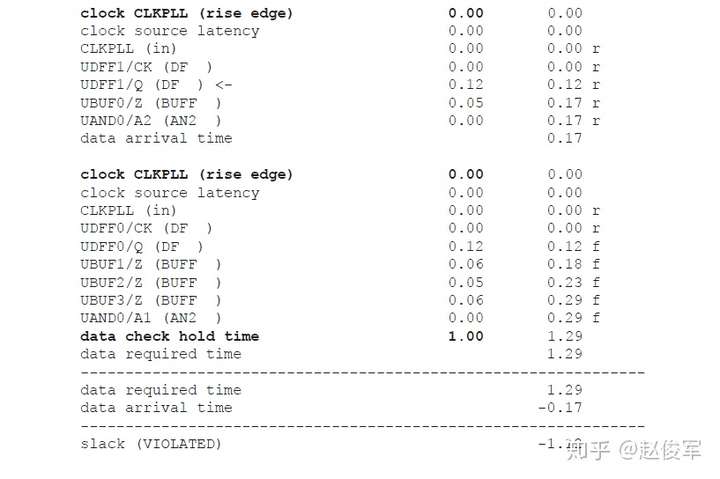
现在,保持时间检查是在约束引脚和相关引脚相同时钟沿上执行的。在同一周期中执行数据到数据保持时间检查的另一种方法是:将其指定为相反方向上的引脚之间的数据到数据建立时间检查。
● set_data_check -from UAND0/A2 -to UAND0/A1 -setup 1.0
数据到数据的检查在对数据不改变进行检查(no-change data check)时也很有用。通过在上升沿处指定建立时间检查,在下降沿处指定保持时间检查,从而有效地定义了数据不变窗口,如图10-8所示。
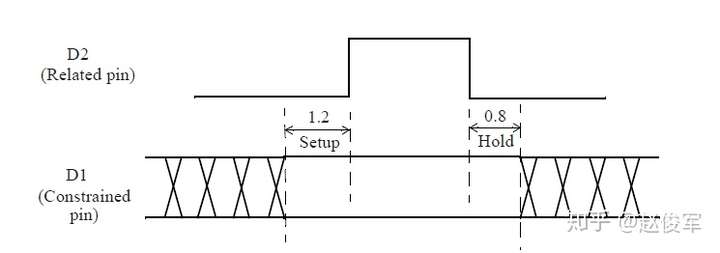
这种情况的约束如下:
● set_data_check -rise_from D2 -to D1 -setup 1.2
● set_data_check -fall_from D2 -to D1 -hold 0.8
非时序检查
单元或宏(macro)的库文件可以将时序弧指定为非时序(non-sequential)检查,例如两个数据引脚之间的时序弧。非时序检查是指两个引脚之间的检查,两者都不是时钟。一个引脚是约束引脚,其作用类似于数据,而第二个引脚是相关引脚,其作用类似于时钟。该检查指定了在相关引脚上的数据改变前后,约束引脚上的数据必须保持稳定多长时间。
请注意,此检查被指定为单元库规范的一部分,并且不需要显式的数据到数据检查约束。以下是这种时序弧在单元库中的表示形式:


setup_rising指相关引脚的上升沿,固有(intrinsic)上升值和下降值是指约束引脚的上升和下降建立时间。可以为hold_rising、setup_falling和hold_falling定义类似的时序弧。
非时序检查类似于10.3节中介绍的数据到数据检查,但是有两个主要区别。在非时序检查中,建立时间和保持时间的值是从标准单元库中获得的,可以使用NLDM表格模型或其它高级时序模型来描述建立时间和保持时间模型。而在数据到数据检查中,只能为数据到数据的建立时间或保持时间检查指定一个值。第二个区别是,非时序检查只能应用于单元的引脚,而数据到数据的检查可以应用于设计中的任意两个引脚。
非时序建立时间检查指定了约束信号必须相对于相关引脚多早到达,如图10-9所示。单元库中包含了建立时间弧D0-> WEN,它被指定为了非时序弧。如果在建立时间窗口内出现WEN信号,则非时序建立时间检查将失败。
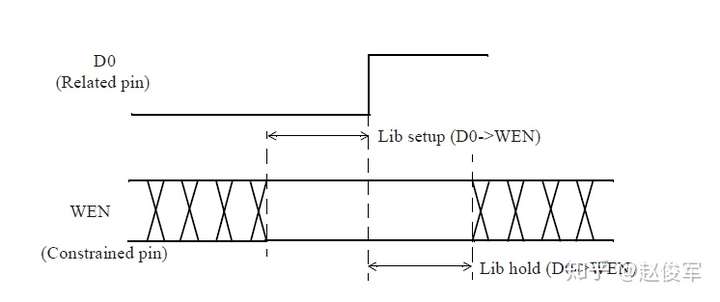
非时序保持时间检查指定了约束信号必须相对于相关引脚多晚到达,如图10-9所示。如果WEN在保持时间窗口中改变了,则非时序保持时间检查将失败。
时钟门控检查
当一个门控信号(gating signal)可以控制逻辑单元中时钟信号(clock signal)的路径时,将会执行时钟门控检查(clock gating check),一个示例如图10-10所示。逻辑单元与时钟相连的引脚称为时钟引脚(clock pin),与门控信号相连的引脚称为门控引脚(gating pin),产生时钟门控的逻辑单元也称为门控单元(gating cell)。
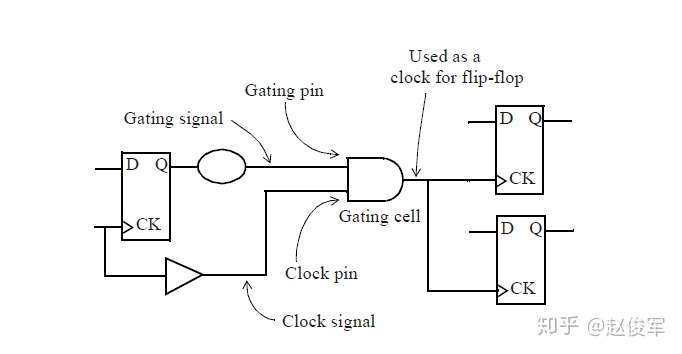
进行时钟门控检查的条件之一是:必须将通过门控单元的时钟用作下游的时钟。下游时钟的使用可以是触发器的时钟、也可以是扇出到输出端口、也可以是作为衍生时钟的主时钟。如果时钟不用作门控单元之后的下游时钟,则不会推断出时钟门控检查。
时钟门控检查的另一个条件针对的是门控信号:门控引脚上的信号不应是时钟,或者如果是时钟,也不应将其用作下游时钟(例如本节稍后要介绍的将时钟用作门控信号的一个示例)。
在一般情况下,时钟信号和门控信号不需要连接到同一个逻辑单元(例如与门、或门),但是可以输入到任意逻辑块。在这种情况下,为了推断出时钟门控检查,检查的时钟引脚和检查的门控引脚必须扇出到公共输出引脚。
可推断出两种时钟门控检查:
● 高电平有效时钟门控检查:门控单元具有“与”功能或者“与非”功能。
● 低电平有效时钟门控检查:门控单元具有“或”功能或者“或非”功能。
高电平有效和低电平有效是指门控信号的逻辑状态,该逻辑状态用以使能门控单元输出端的时钟信号。如果门控单元是门控关系不明显的复杂功能,例如多路复用器(MUX)或异或门(XOR),则STA输出通常会给出警告,提示没有推断出时钟门控检查。但是,可以通过使用命令set_clock_gating_check为门控单元显式地指定时钟门控关系。在这种情况下,如果set_clock_gating_check命令与门控单元的功能不一致,则STA通常会给出警告。我们将在本节稍后部分介绍此类命令的示例。
如前所述,只有当时钟不用作下游时钟时,它才可以用作门控信号,考虑图10-11中的示例。由于定义了CLKA的衍生时钟,因此CLKB不用作下游时钟,即CLKB的路径被衍生时钟的定义阻塞了。因此,针对这个与门单元会推断出时钟CLKA的时钟门控检查。
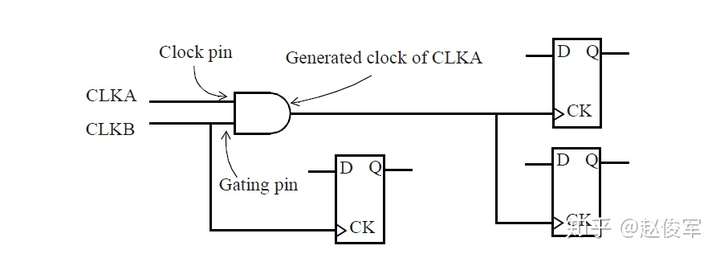
高电平有效时钟门控
现在,我们来讨论高电平有效时钟门控检查的时序关系。这发生在与门(and)或者与非门(nand)单元上,使用与门单元的示例如图10-12所示。门控单元的引脚B是时钟信号,门控单元的引脚A是门控信号。
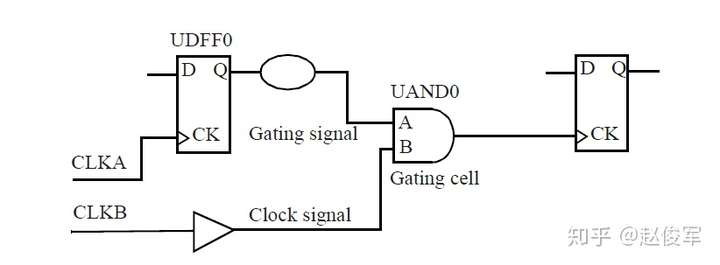
让我们假设两个时钟CLKA和CLKB具有相同的波形。
● create_clock -name CLKA -period 10 -waveform {0 5} [get_ports CLKA]
● create_clock -name CLKB -period 10 -waveform {0 5} [get_ports CLKB]
因为它是一个与门单元,所以门控信号引脚UAND0 / A上为高电平时才会打开门控单元,并允许时钟传播通过。时钟门控检查旨在验证门控引脚的电平切换不会为扇出时钟创建时钟有效沿。对于上升沿触发的逻辑,这意味着门控信号的上升沿发生在时钟的无效周期内(当其为低电平时)。类似地,对于下降沿触发的逻辑,门控信号的下降沿应仅在时钟为低电平时产生。注意,如果时钟同时驱动上升沿和下降沿触发的触发器,则门控信号的任何边沿(上升沿或下降沿)都必须仅在时钟为低电平时产生。图10-13给出了一个在有效周期期间门控信号电平切换的示例,该信号需要延迟才能通过时钟门控检查。
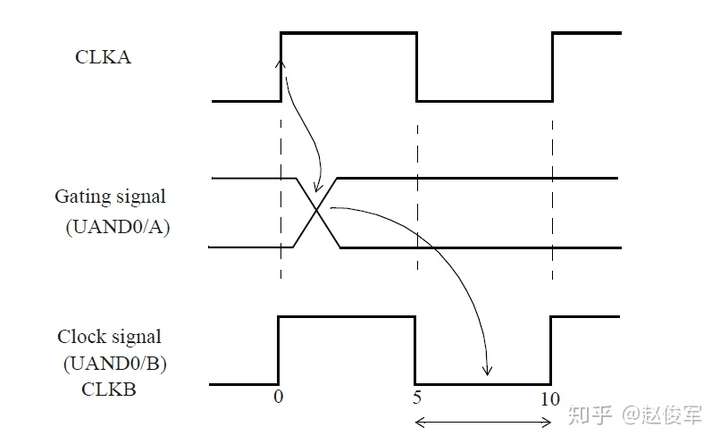
高电平有效时钟门控的建立时间检查可确保门控信号的电平改变发生在时钟变为高电平之前。以下是建立时间检查的路径报告:

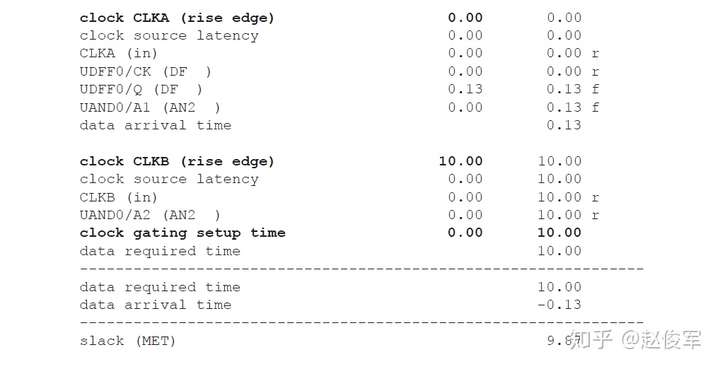
请注意,终点(Endpoint)处说明这是时钟门控检查。另外,从Path Group一行中可以看出该路径属于clock_gating_default路径组中。该检查能确保门控信号在10ns处的时钟CLKB下一个上升沿之前改变。
高电平有效时钟门控的保持时间检查要求门控信号仅在时钟的下降沿之后才可以发生变化。以下是保持时间检查的路径报告:
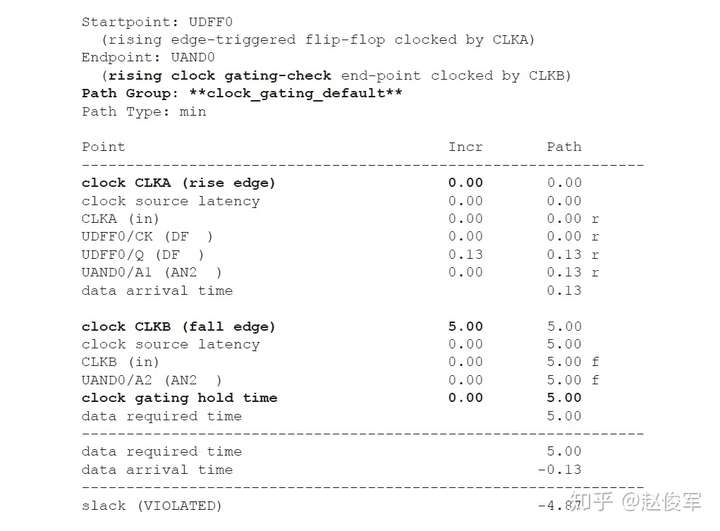
时钟门控的保持时间检查失败了,因为在5ns处的CLKB下降沿之前,门控信号发生了改变。如果在UDFF0 / Q和UAND0 / A1引脚之间添加了5ns的延迟,则时钟门控的建立时间和保持时间检查都会通过,即门控信号仅在指定的时间窗口内发生变化。
从前文可以看到保持时间要求是非常大的,这是由于产生门控信号的时钟沿和门控单元时钟信号的有效沿是相同沿(上升沿或下降沿)导致的,这可以通过使用另一种类型的触发器(例如下降沿触发的触发器)产生门控信号来解决。下面将介绍这样的示例。
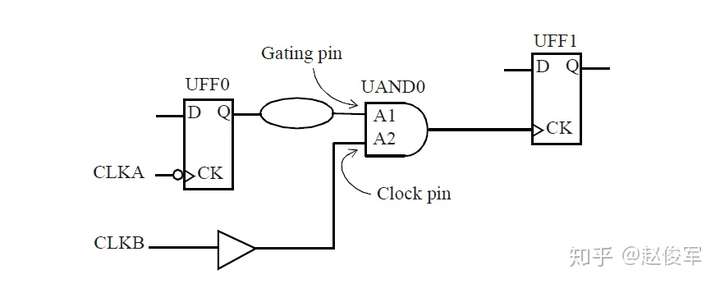
在图10-14中,触发器UFF0由时钟CLKA的下降沿触发。安全的时钟门控意味着触发器UFF0的输出必须在门控时钟的无效周期(5ns至10ns)之间才能变化。
与图10-14中的原理图相对应的信号波形如图10-15所示:
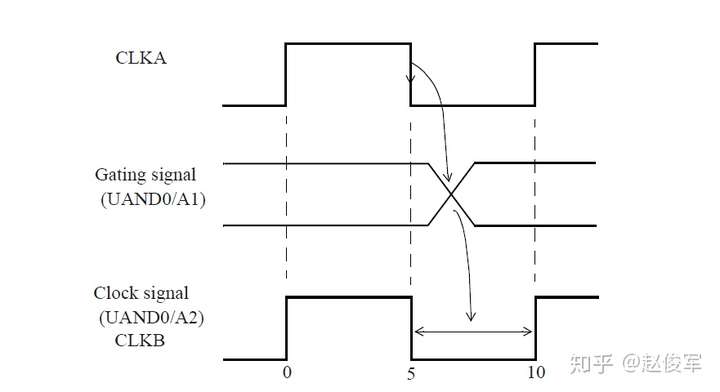
以下是时钟门控的建立时间检查报告:

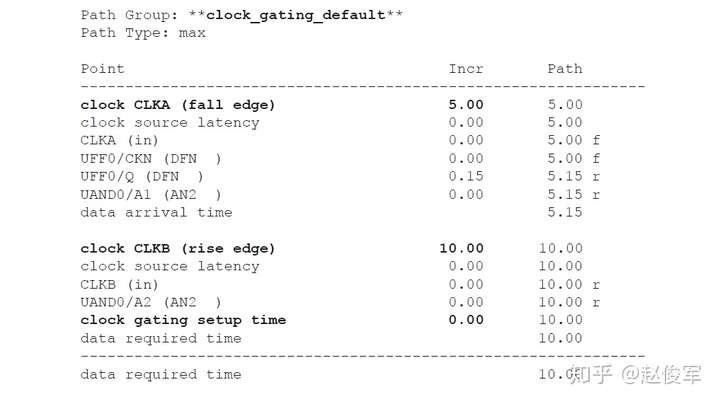

以下是时钟门控的保持时间检查报告。请注意,在此新设计中,保持时间检查更容易满足要求。
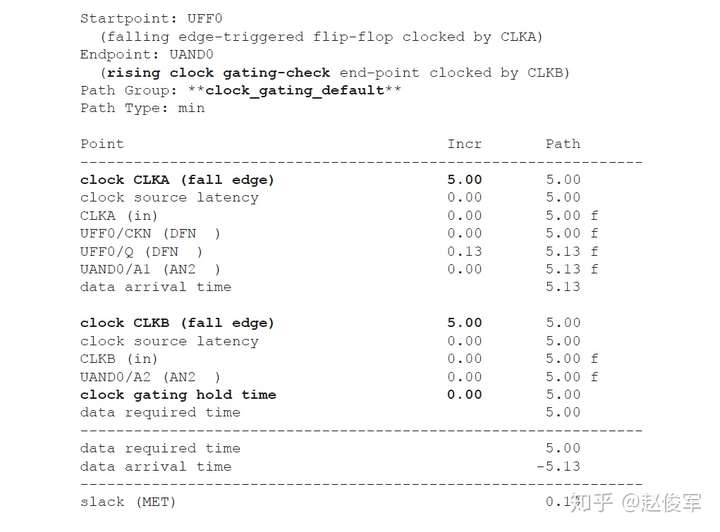
由于产生门控信号的时钟沿(下降沿)与门控时钟相反(高电平有效),因此很容易满足建立时间和保持时间的要求。这也是门控时钟最常用的结构。
低电平有效时钟门控
图10-16给出了低电平有效时钟门控检查的示例:
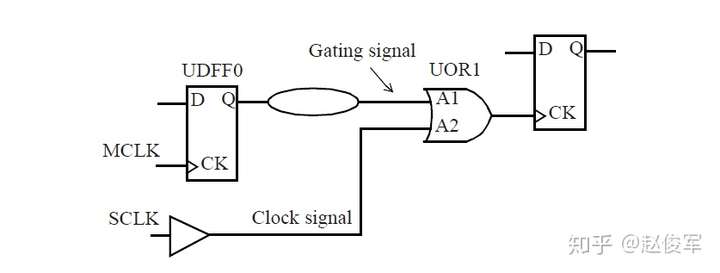
● create_clock -name MCLK -period 8 -waveform {0 4} [get_ports MCLK]
● create_clock -name SCLK -period 8 -waveform {0 4} [get_ports SCLK]
低有效时钟门控检查可验证对于上升沿触发的逻辑,门控信号的上升沿在时钟的有效周期(高电平时)内到达。如前所述,关键在于门控信号不应使门控时钟的输出产生有效沿。当门控信号为高电平时,时钟无法通过。因此,只有在时钟为高电平时,门控信号才允许切换,如图10-17所示。
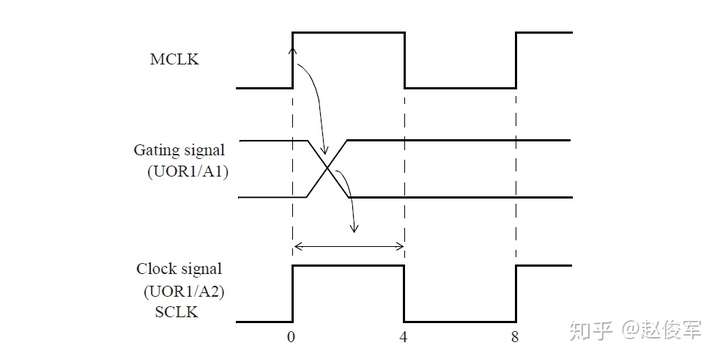
以下是低电平有效时钟门控的建立时间检查报告。该检查可确保门控信号在时钟沿变为无效状态(在这种情况下为4ns)之前到达。
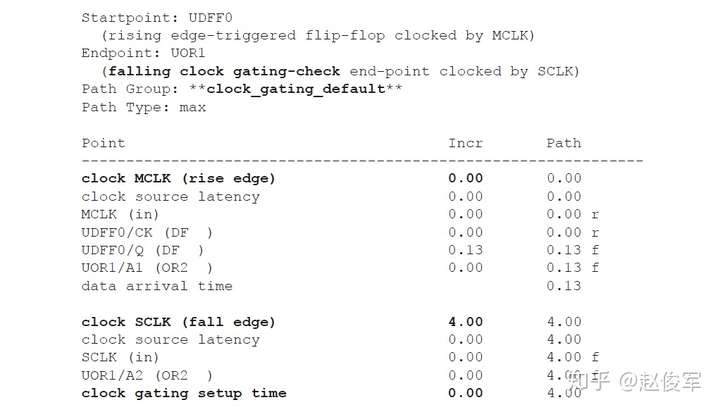

以下是时钟门控的保持时间检查报告。此检查可确保门控信号仅在时钟信号的上升沿(在这种情况下为0ns)之后才发生变化。
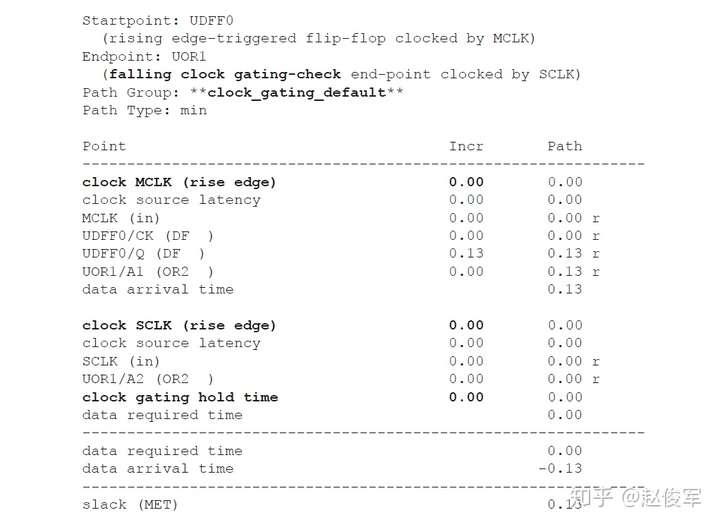
使用多路复用器的时钟门控
图10-18给出了使用多路复用器单元进行时钟门控的示例。多路复用器输入上的时钟门控检查可确保多路复用器选择信号在正确的时间到达,以在MCLK和TCLK之间进行“干净”(clean)的切换。对于这个例子,我们感兴趣的是MCLK,假设TCLK为低电平时选择信号进行切换。这意味着多路复用器的选择信号应仅在MCLK为低电平时进行切换,这类似于高电平有效时钟门控检查。
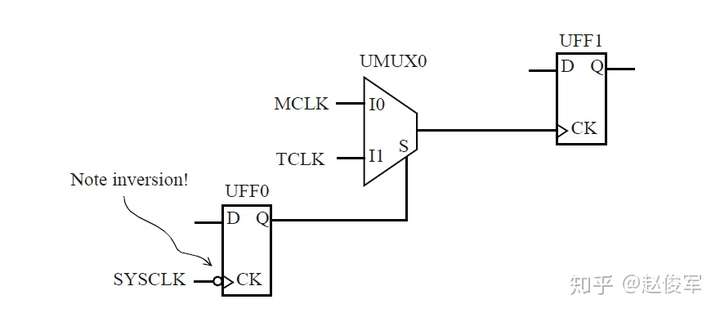
时序关系如图10-19所示,多路复用器的选择信号必须在MCLK为低电平时到达。同样,假设选择信号改变时TCLK为低电平。
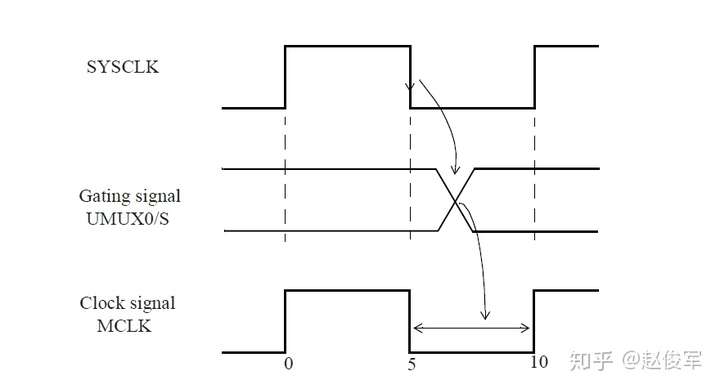
由于门控单元是多路复用器,因此不会自动推断出时钟门控检查,在STA期间会报告出以下信息:

但是,通过使用set_clock_gating_check命令可以强制执行时钟门控检查。
● set_clock_gating_check -high [get_cells UMUX0]
● set_disable_clock_gating_check UMUX0/I1
第一条命令中的-high选项表示这是高电平有效的时钟门控检查,第二条命令中的禁止检查将关闭特定引脚上的时钟门控检查,因为我们不考虑该引脚。以下是建立时间检查的路径报告:

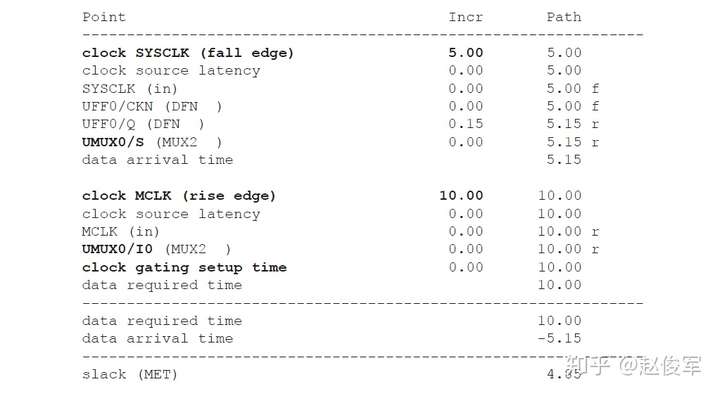
接下来是时钟门控的保持时间检查报告:


带时钟反相的时钟门控
图10-20显示了另一个时钟门控示例,其中产生门控信号的触发器时钟被反相了。由于门控单元是与门单元,因此门控信号必须仅在时钟信号为低电平时才能切换,这定义了时钟门控的建立时间和保持时间检查。
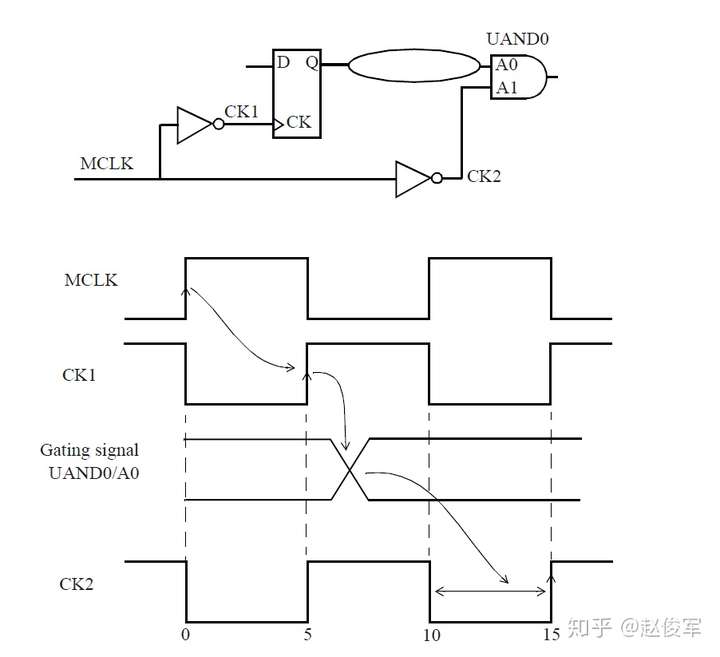
以下是时钟门控的建立时间检查报告:



请注意,建立时间检查会验证数据是否在15ns处的MCLK沿之前发生改变。以下是时钟门控的保持时间检查报告:
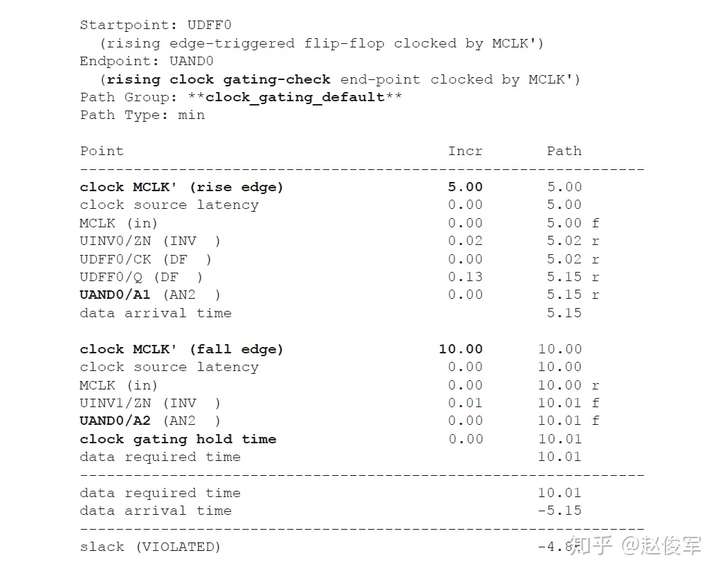
保持时间检查可验证门控信号是否在10ns处的MCLK下降沿之前发生了改变。
如果门控单元是一个复杂的单元并且建立时间和保持时间检查不够明显,则可以使用set_clock_gating_check命令来指定对门控单元的门控信号进行建立时间和保持时间检查。建立时间检查会去确保门控信号在时钟信号的有效沿之前是稳定的,建立时间检查的失败可能会导致门控单元输出端出现毛刺。保持时间检查可验证门控信号在时钟信号的无效沿处是否稳定。以下是set_clock_gating_check命令的一些示例:
● set_clock_gating_check -setup 2.4 -hold 0.8 [get_cells U0/UXOR1]
● set_clock_gating_check -high [get_cells UMUX5]
功耗管理
功耗管理是任何设计及其实现方式的一个重要方面。在设计实现(implementation)过程中,设计人员通常需要评估在速度、功耗和面积之间权衡(trade-off)的不同方法。
如第3章所述,一个设计的逻辑部分中消耗的功率包括漏电功率(leakage power)和有功功率(active power)。 此外,模拟部分和IO缓冲器(尤其是具有主动匹配功能的)会耗散与功能无关且非漏电的功率。在本节中,我们重点讨论设计中逻辑部分所耗散功率的权衡。
通常,管理由标准单元和存储器组成的数字逻辑的功率影响有两个注意事项:
● 使设计的总有功功率最小化:设计人员将确保总功耗保持在特定的功耗极限之内。设计的不同工作模式可能会有不同的极限值,此外,设计中使用的不同供电电源也会有不同的极限值。
● 使待机模式下设计的功耗最小化:对于电池供电的设备(例如手机),这是一个重要的考虑因素,其目的是使待机模式下的功耗最小。待机模式下的功耗等于漏电功耗加上待机模式下有效逻辑的任何功耗。如上所述,可能存在其它模式,例如睡眠模式,其对功耗的约束有所不同。
本节将介绍各种功耗管理方法,这些方法中的每一种都有其优缺点。
时钟门控
如第3章所述,触发器的时钟翻转是总功耗的重要组成部分。即使触发器的输出未切换,触发器也会由于时钟切换而消耗功率。考虑图10-21(a)中的示例,其中触发器仅在使能信号EN处于有效状态时才接收新数据,否则将保持先前的状态。在EN信号处于无效状态期间,时钟在触发器处的翻转不会引起任何输出变化,但是仍然导致了触发器内部的功率消耗。时钟门控的目的是:通过在触发器输入无效的时钟周期内消除触发器的时钟翻转来最大程度地减少这种影响。通过时钟门控进行的逻辑重组会在触发器时钟引脚上引入时钟门控,图10-21给出了此时钟门控的示例:
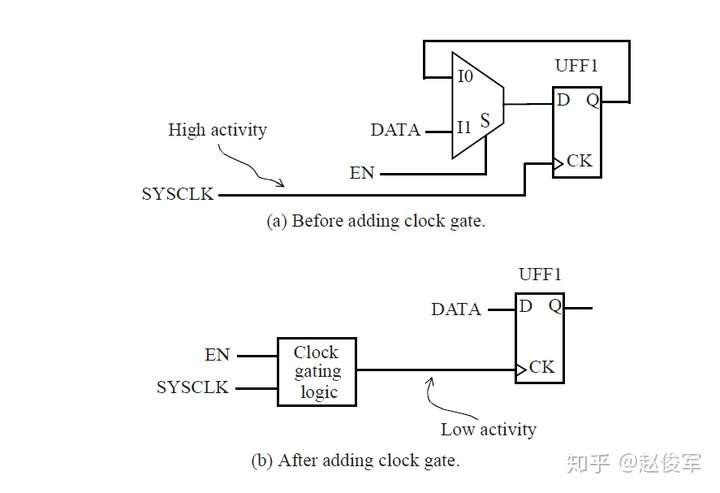
因此,时钟门控可确保仅在其数据输入端有新数据可用时,触发器的时钟引脚才会翻转。
电源门控
电源门控包括关闭电源,以便可以关闭无效模块的供电。图10-22中说明了此过程,其中在电源中串联添加了Header(或Footer)MOS器件。适当配置控制信号SLEEP后,可以使Header(或Footer)MOS器件在模块的正常工作期间处于打开状态。由于在正常工作期间电源门控MOS器件(Header或Footer)处于打开状态,因此该模块已被上电,并在正常功能模式下运行。在模块的无效(或睡眠)模式期间,门控MOS器件(Header或Footer)被关闭,这可以消除逻辑模块中的任何有功功耗。Footer是在实际的地与模块的地网络之间的大型NMOS器件,可通过电源门控对其进行控制。Header是实际的电源和模块的电源网络之间的大型PMOS设备,也可通过电源门控进行控制。在睡眠模式下,模块中唯一消耗的功率是通过Header(或Footer)器件的漏电功率。
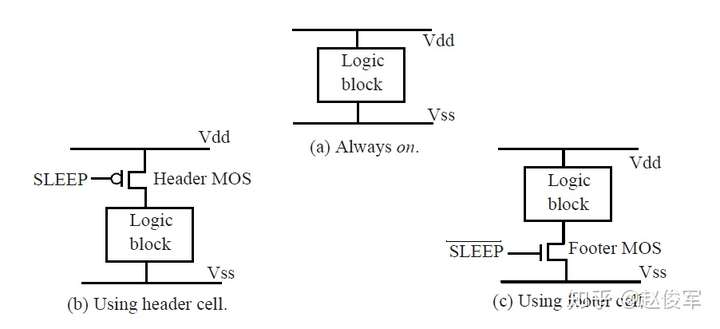
通常使用多个电源门控单元来实现Header或Footer,这些电源门控单元对应于多个并联的MOS器件。Header和Footer器件为电源引入了一系列导通电阻。如果导通电阻的值不小,则通过门控MOS器件的IR压降会影响逻辑模块中单元的时序。关于门控器件尺寸的考虑主要是为了确保导通电阻值足够小,若再同时考虑电源门控MOS器件在无效模式或睡眠模式下的漏电功耗,则需要进行权衡。
总之,应该有足够数量的并联电源门控单元,以确保在正常工作模式下电阻串联时的IR压降最小。但是,在无效模式或睡眠模式下门控单元的漏电功耗也是选择并联电源门控单元数量的标准。
多阈值单元
如第3章(3.8节)中所述,多阈值(Vt)单元可用于权衡速度与漏电。高Vt单元的漏电较少,但是却比标准Vt单元的速度更慢,相反,标准Vt单元虽然速度更快,但是漏电也更多。同样,低Vt单元的速度比标准Vt单元更快,但漏电量也相应地比较高。
在大多数设计中,目标是在达到所需工作速度的同时将总功率降至最低。即使漏电可能是总功率的重要组成部分,但仅采用高Vt单元来减少漏电的设计也可能会增加总功率,尽管漏电确实减少了。这是因为最终的设计实现可能需要更多(或更高强度)的高Vt单元才能实现所需的性能。由于使用高Vt单元,等效门数的增加导致的有功功率增加将会远大于漏电功率的减少。但是在某些情况下,漏电才是总功率的主要组成部分,在这种情况下,使用高Vt单元的设计可以使总功率降低。由于需要取决于具体的设计以及切换活动曲线(switching activity profile),因此需要适当地利用上述具有不同Vt的单元之间在速度和漏电方面的折中。下面将介绍一个高性能模块的两种不同情况,根据模块是处于非常活跃状态还是低切换状态,实现方法可能有所不同。
具有高切换活动的高性能模块
这种情况是具有高切换活动的高性能模块,其功率主要由有功功率决定。对于此类模块,即使可以将漏电影响最小化,但仅专注于降低漏电功率还是会导致总功率的增加。在这种情况下,初始设计实现应使用标准Vt(或低Vt)单元来满足所需的性能。在达到所需的时序之后,可以将具有正时序裕量的路径上的单元更改为高Vt单元,以便在仍满足时序要求的同时减少漏电功率。因此,在最终实现中,仅沿着关键或难以实现的时序路径使用标准Vt(或低Vt)单元,而沿着非关键时序路径的单元可以是高Vt单元。
具有低切换活动的高性能模块
这种情况是切换活动非常低的高性能模块,因此漏电功率是总功率的主要组成部分。由于该模块切换活动频率很低,因此有功功率并不是设计总功率的主要组成部分。对于此类模块,最初的设计实现在组合逻辑和触发器中仅使用高Vt单元。由于时钟树始终处于有效状态,因此会使用标准Vt(或低Vt)单元。在仅使用高Vt单元的最初实现之后,可能会有一些时序路径无法满足所需的时序。然后,可以将沿着此类路径的单元替换为标准Vt(或低Vt)单元,以实现所需的时序性能。
阱极偏置
阱极偏置(well bias)是指分别向用于NMOS和PMOS器件的P阱或N阱增加小的电压偏置。图2-1中所示的NMOS器件的衬底(或P阱)通常连接至地。同样,图2-1中所示的PMOS器件的衬底(或N阱)通常连接至电源(Vdd)。
如果阱的连接处具有轻微的负偏置电压,则可以大大降低漏电功率。这意味着NMOS器件的P阱连接到较小的负电压(例如-0.5V),类似地,PMOS器件的N阱连接处被连接到了高于电源的电压(例如Vdd + 0.5V)。通过添加阱极偏置,将会影响单元的速度,但是漏电大大减少了。单元库中的时序是考虑了阱极偏置之后的。
使用阱极偏置的缺点是:P阱和N阱连接需要额外的供电电源(例如-0.5V和Vdd + 0.5V)。
反标
SPEF
STA如何知道设计的寄生参数?通常,此参数信息是使用寄生提取工具提取出的,并且STA工具会以SPEF格式来读取此数据。SPEF的详细信息和格式将在附录C中介绍。
物理设计布局工具中STA引擎的行为也是类似的,不同之处在于提取信息将被写入内部数据库中。
SDF
在某些情况下,单元和互连走线的延迟是由另一个工具计算的,并通过SDF文件将其读入STA。使用SDF的优点是不再需要计算单元延迟和互连走线延迟,因为它们直接来自SDF文件,因此STA可以专注于时序检查。但是,这种标注延迟(delay annotation)的缺点是,由于缺少寄生信息,STA无法执行串扰计算。通常SDF是用于将延迟信息传递给仿真器的一种机制。
SDF的详细信息和格式将在附录B中介绍。
Sign-off方法学
STA可以在许多不同的情况下执行,不同的情况主要由三个变量来确定:
● 寄生角(用于寄生参数提取的RC互连角和工作条件)
● 操作模式
● PVT角
互连寄生角
寄生参数可以在许多角(corner)下提取。这些主要取决于制造过程中金属宽度和金属刻蚀的变化,这些角包括:
● Typical:这是指互连电阻和电容的标准值。
● Mac C:这是指使电容值最大的互连角,其互连电阻小于Typical角下的电阻。该角会导致较短网络的路径延迟最大,因此可用于最大路径分析。
● Min C:这是指使电容值最小的互连角,其互连电阻大于Typical角下的电阻。 该角会导致较短网络的路径延迟最小,因此可用于最小路径分析。
● Max RC:这是指使互连RC乘积最大的互连角。这通常对应于较大的刻蚀,较大的刻蚀可以减小走线的宽度。该角会使电阻值最大,但对应的电容值小于Typical角下的电容。总体而言,该角对于互连走线较长的路径具有最大的延迟,可用于最大路径分析。
● Min RC:这是指使互连RC乘积最小的互连角。这通常对应于较小的蚀刻,较小的刻蚀会增加走线的宽度。该角会使电阻值最小,但对应的电容值大于Typical角下的电容。总的来说,该角对于互连走线较长的路径具有最小的路径延迟,可用于最小路径分析。
基于上述各个角的互连电阻和电容,具有较大电容的互连角会导致电阻较小,具有较小电容的互连角会导致电阻较大。因此,电阻在一定程度上补偿了各个互连角下的电容。这意味着对于所有类型网络的延迟,没有一个角会真正对应极限情况(最差情况或最佳情况)。使用Cworst / Cbest角下的路径延迟仅对于较短网络是极限情况,而RCworst / RCbest角仅对于较长网络是极限情况,而对于平均长度的网络,Typical互连角通常在路径延迟方面是极限的。因此,设计人员经常会在上述各个互连角下都去验证设计的时序。但是,即使在每个角处都进行了验证也可能无法涵盖所有可能的情况,因为不同的金属层实际上可以独立地处于不同互连角下,例如:METAL2在Max C角下而METAL1在Max RC角下。10.9节中介绍的统计(statistical)时序分析将提出一种静态时序分析的机制,其中不同的金属层可以处于不同的互连角下。
操作模式
操作模式决定了设计所要执行的操作,设计的各种操作模式包括:
● 功能模式1(工作在高速时钟下)
● 功能模式2(工作在低速时钟下)
● 功能模式3(睡眠模式)
● 功能模式4(调试模式)
● 测试模式1(scan capture)
● 测试模式2(scan shift)
● 测试模式3(bist)
● 测试模式4(jtag)
PVT角
PVT角指的是STA在什么条件下执行。最常见的PVT角有:
● WCS(慢工艺、低电压、高温)
● BCF(快工艺、高电压、低温)
● Typical(典型工艺、标准电压、标准温度)
● WCL(低温下的最差情况:慢工艺、低电压、低温)
STA分析可以在任何条件下执行,这里的条件是指上述互连寄生角、操作模式和PVT角的组合。
多模式多角分析
多模式多角分析MMMC(Multi-Mode Multi-Corner)是指同时在多个工作模式、PVT角和寄生互连角之间执行STA。例如,假设一个DUA具有四个工作模式(正常、睡眠、扫描移位和Jtag),并且正在三个PVT角(WCS,BCF,WCL)和三个寄生互连角(Typical,Min C,Min RC)下进行分析 ,如下表所示:
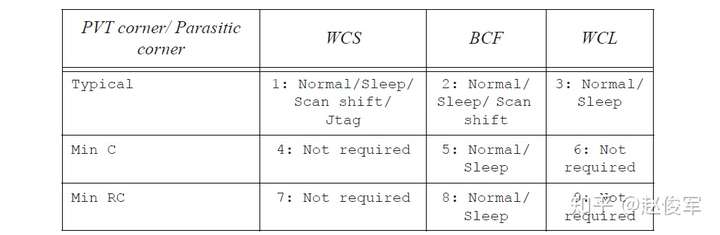
总共有36种可能的情况可以去执行所有时序检查,例如建立时间、保持时间、压摆和时钟门控检查。对于运行时间而言,同时运行所有36个情况的STA可能会因设计规模而导致运行时间过长。某一个情况可能不是基本的,因为它可能包含在了另一个情况中,又或者这个情况不是必需的。例如,设计人员可以确定情况4、6、7和9不相关,因此不是必需的。此外,可能不必在一个角上运行所有模式,例如在情况5中可能不需要扫描移位模式或Jtag模式。如果可以使用MMMC功能,则STA可以在单个情况中运行,也可以在多个情况中同时运行。
运行多模式多角STA的优点是可以节省运行时间并节省设置分析脚本的复杂性。MMMC方案的另一个优势在于,与每种模式或角需要分别多次加载设计和寄生参数相比,MMMC只需加载一次或两次即可。这样的工作也更适合在LSF服务器上运行。多模式多角在优化过程中也具有很大的优势:在优化过程中会对所有情况进行优化,因此在一个情况中解决的时序违例不会在另一情况中引入时序违例。
对于IO约束,-add_delay选项可与多个时钟源一起使用,以在一次运行(run)中分析不同的模式,例如scan或bist模式,或PHY中对应于不同速度的不同操作模式。通常每种模式都会在单独的运行中进行分析,但并非总是如此。
通常这样的设计是不常见的:具有大量时钟、需要数十次独立运行才能覆盖最大和最小角的每种模式、需要包括串扰和噪声的影响。
统计静态时序分析
到目前为止介绍的静态时序分析技术是确定性的,因为分析基于的是设计中所有时序弧的固定延迟。每个时序弧的延迟都是根据工作条件以及工艺和互连模型计算得出的,尽管可能存在多个模式和多个角,但给定情况下的时序路径延迟是可以明确获得的。
实际上,执行STA时通常使用的工艺和工作条件的最差情况(WCS)或最佳情况(BCF)对应于极端的3σ角。时序库基于的是代工厂提供的带有工作条件的工艺角模型,这些条件对应于单元时序值的不同角。例如,使用快速工艺模型、最高电源和最低温度来表征最佳情况的快速时序库。
工艺和互连走线变化
全局工艺变化
全局工艺变化(global process variation),也称为芯片间器件变化(inter-die device variations),是指影响芯片(或晶圆)上所有器件的工艺参数变化,参见图10-24。这表明芯片上的所有器件都会受到这些工艺变化的影响,芯片上的每个器件都会是slow或是fast的,或者介于两者之间。 因此,通过全局工艺参数建模的变化旨在捕获芯片与芯片之间的变化。
图10-25中显示了全局参数值(例如g_par1)的变化。例如,参数g_par1可以对应于标准NMOS器件的IDSsat(器件饱和电流)。由于这是一个全局参数,因此芯片上所有单元实例中的所有NMOS器件将对应于相同的g_par1值。可以有如下选择:所有单元实例的g_par1的变化是完全相关的,或者芯片上g_par1的变化相互影响。注意,可能还存在其它全局参数(g_par2,...),其可能可以对PMOS器件饱和电流和其它相关变量建模。
不同的全局参数(g_par1,g_par2,...)之间是不相关的。不同全局参数的变化是不会相互影响的,这意味着g_par1和g_par2参数彼此将独立地变化。在一块芯片上,g_par1可能处于最大值,而g_par2可能处于最小值。
在确定性(即非统计性)分析中,慢速工艺模型可能对应于芯片间变化的+ 3σ角的条件。类似地,快速工艺模型可能对应于芯片间变化的-3σ角的条件。
局部工艺变化
局部工艺变化(local process variation),也称为芯片内器件变化,是指工艺参数的变化,这些变化可以在给定芯片上影响不同器件,参见图10-26。这意味着并排放置在同一芯片上的相同器件可能具有不同的行为。由局部工艺变化建模的变化旨在捕获芯片内的随机工艺变化。
图10-27显示了局部工艺参数的变化。芯片上的局部参数变化不会相互影响,并且它们从一个单元实例到另一单元实例的变化是不相关的。这意味着对于同一芯片上的不同器件,局部参数可能具有不同的值。例如,芯片上的不同NAND2单元实例可能会具有不同的局部工艺参数值。即使其它参数(例如输入压摆和输出负载)相同,这也可能导致同一NAND2单元的不同实例具有不同的延迟值。
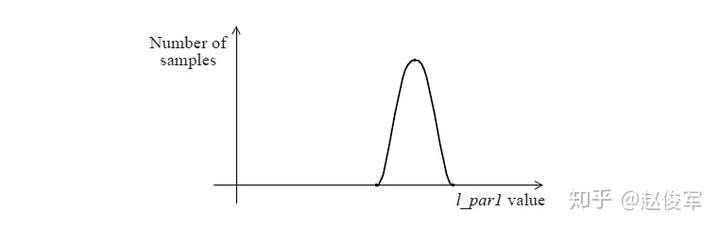
由全局和局部变化引起的NAND2单元延迟变化的示意图如图10-28所示。该图说明了全局参数变化比局部参数变化引起的延迟变化更大。
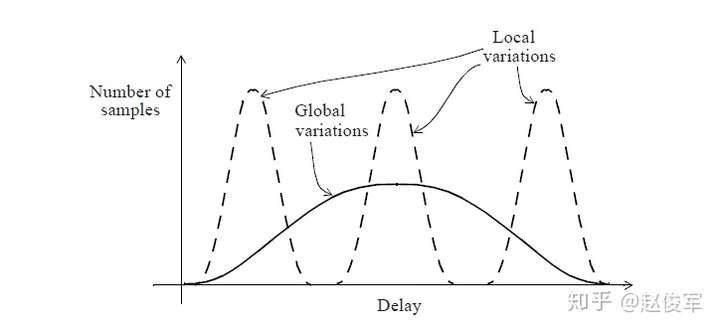
局部工艺变化是打算在使用OCV建模的分析中捕获的变化之一,如10.1节中所述。由于统计时序模型通常包括局部工艺变化,因此使用统计时序模型进行的OCV分析不应在OCV设置中包括局部工艺变化。
互连走线变化
如10.8节中所述,实际上存在着各种互连角,它们代表影响互连电阻和电容值的每个金属层的参数变化。这些参数变化通常是金属和电介质的厚度以及影响各种金属层中金属走线的宽度和间距的金属刻蚀。通常,影响金属的参数会影响该金属层中所有走线的寄生参数,但对其它金属层中走线的寄生影响很小甚至是没有影响。
10.8节中介绍的互连角可用于对互连走线变化进行建模,以便所有金属层都对应到相同的互连角下。对互连走线变化进行统计建模时,每个金属层都可以独立地变化。统计方法会对互连走线空间中所有可能的变化组合进行建模,从而对仅通过在指定互连角下进行分析可能无法捕获的变化进行建模。例如,时钟树的发起路径可能在METAL2中,而时钟树的捕获路径可能在METAL3中。传统互连角下的时序分析会考虑各种角,这些角会同时改变所有金属层,因此无法对这种情况进行建模:METAL2在该角下延迟最大,而METAL3在该角下延迟最小。这种组合对应于路径建立时间检查的最差情况,并且只能通过对互连走线变化进行统计建模来捕获。
统计分析
什么是SSTA?
如果对单元时序模型和互连寄生进行统计建模,则上述对变化的建模是可行的。除延迟外,还对单元输入端的引脚电容值也进行了统计建模,这意味着时序模型是根据工艺参数(全局和局部)的均值和标准差来描述的,而互连电阻和电容是根据互连参数的平均值和标准差来描述的。延迟计算过程(在第5章中介绍的)会先获得每个时序弧(单元以及互连走线)的延迟,然后再用相对于各种参数的平均值和标准差来表示。因此,每个延迟都由平均值和N个标准差来表示(其中N是统计建模中独立工艺和互连参数的数量)。
由于通过各个时序弧的延迟是用统计形式表示的,因此统计静态时序分析SSTA(Statistical Static Timing Analysis)过程中会结合时序弧的延迟以获得路径延迟,该路径延迟同样会以统计形式表示(具有均值和标准差)。SSTA会根据独立的工艺和互连参数的标准差,来获得路径延迟的总体标准差。例如,考虑由两个时序弧组成的路径延迟,如图10-29所示。由于每个延迟分量都有其变化,因此根据变化是相关的还是不相关的,将对变化进行不同的组合。如果变化来自同一来源(例如,由相互影响的g_par1参数引起),则路径延迟的σ仅等于(σ1 + σ2)。但是,如果变化是不相关的(例如由于l_par1参数),那么路径延迟的σ等于 ,该值小于(σ1 + σ2)。当对局部(不相关的)工艺变化建模时,路径延迟σ较小的现象也称为各个延迟变化的统计抵消(statistical cancellation)。
对于一个实际设计,既要建模相关变化,也要建模不相关变化,因此需要适当组合这两种类型变化的权重。
发起和捕获时钟的时钟路径延迟也以相同的统计形式表示。基于数据和时钟路径延迟,可以将裕量(slack)作为具有标准值和标准差的统计量。
假设使用正态分布,可以获得对应于(平均值mean +/- 3σ)的有效最小值和最大值。 (平均值mean -/ + 3σ)对应于图10-30中所示正态分布的0.135%和99.865%的分位数。0.135%的分位数意味着仅0.135%的结果分布小于此值(平均值mean-3σ);同样,99.865%的分位数表示99.865%的结果小于此值,或仅0.135%(100%-99.865%)的结果大于此值(平均值mean+3σ)。有效的下限和上限在SSTA报告中称为分位数(quantile),设计人员可以选择分析中使用的分位数,例如0.5%或99.5%,对应于(平均值mean -/ + 2.576σ)。
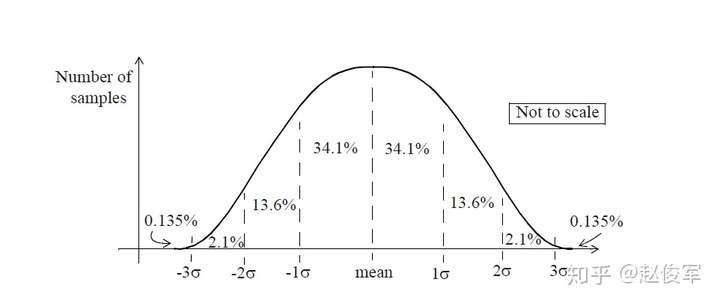
对于噪声和串扰分析(第6章),将使用相对于各种参数的平均值和标准差来对路径延迟和时间窗口进行统计建模。
根据路径裕量分布,SSTA会报告每个路径裕量的平均值、标准差和分位数,从而可以根据所需的统计置信度(confidence)来判断时序是通过还是违例。
统计时序库
在SSTA方法中,标准单元库(以及设计中使用的其它单元库)提供了各种环境条件下的时序模型。例如,在最小Vdd和高温角下进行的分析利用了在此条件下表征的库,但对工艺参数进行了统计建模。该库包含了用于标准参数值以及参数变化的时序模型。对于N个工艺参数,在0.9V电源和125°C条件下表征的统计时序库可能包括以下内容:
● 具有标准工艺参数的时序模型
● 参数i为(标准值+1σ)的时序模型,其他参数保持为标准值
● 参数i为(标准值-1σ)的时序模型,其他参数保持为标准值
对于仅具有两个独立工艺参数的简化情况示例,时序模型是以标准参数值以及参数值的变化来表征的,如图10-31所示。
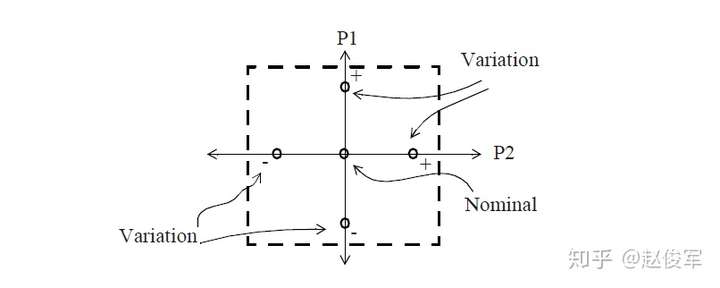
统计互连走线变化
每个金属层有三个独立的参数:
● 金属刻蚀:这可以控制金属宽度以及与相邻导体的间距。金属层中的大刻蚀减小了宽度(这增加了电阻)并增加了到相邻走线的间距(这减小了到相邻走线的耦合电容)。该参数表示为导体宽度的变化。
● 金属厚度:较厚的金属意味着与下面各层的电容更大。该参数表示为导体厚度的变化。
● IMD(金属间介电层)厚度:较大的IMD厚度会减少与下面各层的耦合。该参数表示为IMD厚度的变化。
SSTA结果
统计分析中输出的结果将根据平均值和角的有效值来提供路径的裕量。以下是用于建立时间检查(最大路径分析)的SSTA报告示例:
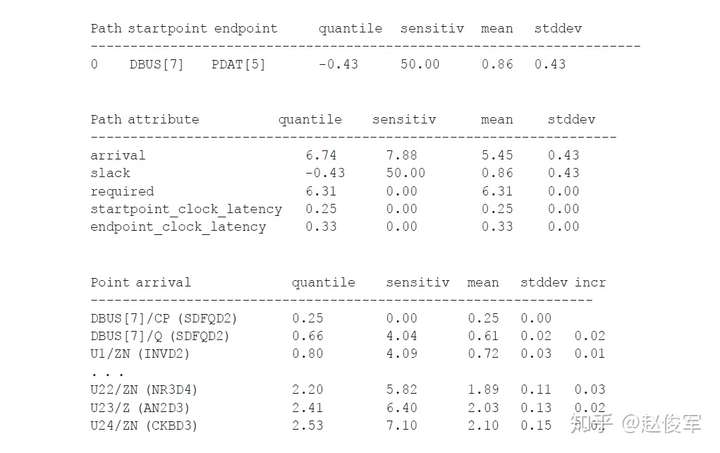

上面的报告显示,尽管时序路径的均值满足要求,但0.135%的分位数却有0.43ns的时序违例,时序路径裕量的分位数为-0.43ns。时序路径裕量的平均值为+ 0.86ns,标准差为0.43ns,这意味着+/- 2σ的分布结果满足要求。由于95.5%的分布落在2σ的变化范围内,这意味着只有2.275%的路径会出现时序违例(其余的2.275%分布具有较大的正裕量)。因此,把分位数设置为2.275%后可以使得裕量为0或没有时序违例。到达时间和路径裕量分布如下图10-32所示:
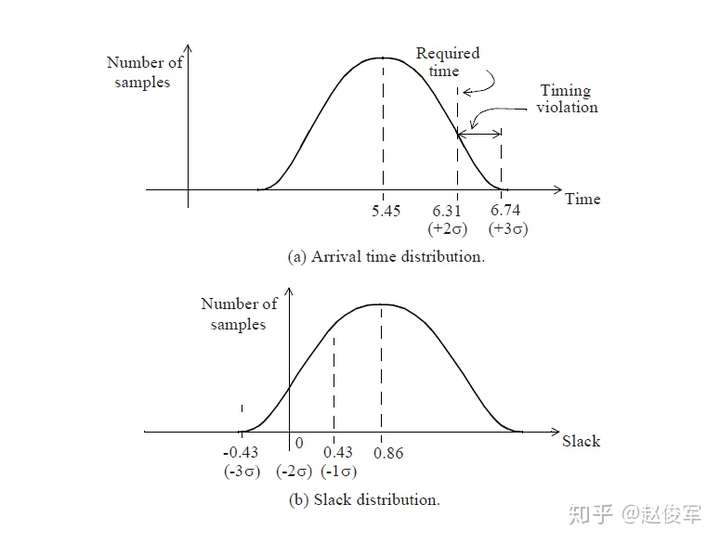
请注意,以上报告是针对建立时间检查的,因此分位数那一列提供的是分位数上限(例如,路径延迟的+ 3σ值),保持时间检查时则会指定为分位数下限(例如-3σ值)。报告中的“sensitiv”列是指敏感度,即标准差与平均值的比值(表示为百分比)。就裕量而言,需要较小的灵敏度,这意味着即使平均值发生变化,以平均值通过的路径也会继续通过。“incr”列中指定了报告中该行的增量标准差。
使用单元和互连走线的统计模型,统计时序方法可以分析各种角条件下的设计,并分析由于工艺和互连参数变化而导致的情况。例如,在最差VT(电压和温度)情况下进行统计分析将分析整个全局工艺和互连走线空间。在最佳VT(电压和温度)情况下的另一种统计分析也将分析整个工艺和互连走线空间。这些分析可以与在最差PVT情况或最佳PVT情况下进行的传统分析进行对比,传统分析仅探讨工艺和互连空间中的单个点。
时序违例路径
在本节中,我们提供了一些示例,重点介绍了设计人员在STA调试期间需要重点关注的方面。其中一些示例仅包含STA报告中的相关片段。
找不到路径
如果有人试图获取路径报告而STA却报告找不到路径,或者它提供了路径报告但裕量是无限的,该怎么办?在这两种情况下,都可能是由于以下原因引起的:
● 时序路径被打断
● 路径不存在
● 这是一条伪路径
在每种情况下,都需要仔细检查约束条件,以识别导致路径阻塞的约束条件。一种“简单粗暴”的选择是删除所有伪路径和时序中断的设置,然后查看路径是否可以进行时序分析。(时序中断是在STA中中断时序弧,可通过使用7.10节中所述的set_disable_timing命令来实现)
跨时钟域
以下是一份路径报告的前面部分:
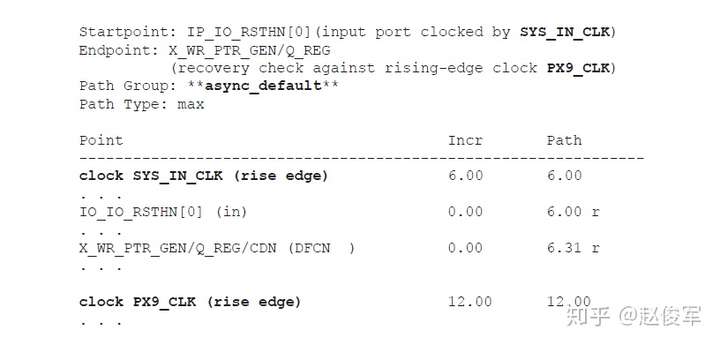

首先要注意的是,该路径从输入端口开始,到触发器的复位引脚结束,并且在该复位引脚上会进行恢复时间检查(图中表示为library recovery time)。接下来要注意的是,该路径跨越了两个不同的时钟域:用于发起输入数据的SYS_IN_CLK和用于恢复时间检查的PX9_CLK。即使从时序报告中看不出来,但从设计知识上来看,也可以检查两个时钟是否完全异步,以及这两个时钟域之间的任何路径是否应申明为伪路径。
反相衍生时钟
创建衍生时钟时,需要谨慎使用-invert选项。如果使用-invert选项指定了衍生时钟,则STA会假定指定点处的衍生时钟属于指定的类型。但是根据逻辑,在设计中可能不会出现这种波形。STA通常会给出错误或警告消息,表明衍生时钟无法实现,但是它将继续进行分析并报告时序路径。
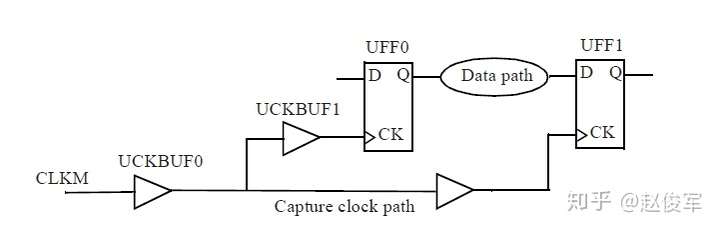
考虑图10-33中示例,让我们在单元UCKBUF0的输出上使用-invert选项定义一个衍生时钟:
● create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM]
● create_generated_clock -name CLKGEN -divide_by 1 -invert -source [get_ports CLKM] [get_pins UCKBUF0/C]
以下是基于上述约束的建立时间检查路径报告:
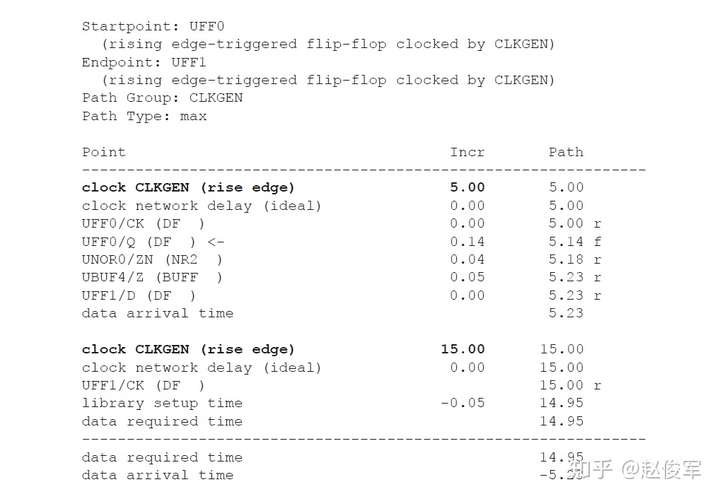

注意,STA会假设单元UCKBUF0的输出波形是时钟CLKM的反相时钟。因此上升沿为5ns,建立时钟捕获沿为15ns。除了时钟的上升沿是5ns而不是0ns之外,从时序报告中还看不出有什么问题。应该注意的是,由于错误是在发起时钟路径和捕获时钟路径的共同部分上,因此建立时间和保持时间检查是正确的。设计人员需要仔细分析和理解STA产生的警告和错误信息。
要注意的重要一点是,无论是否可实现,STA都会按照指定的方式创建衍生时钟。
现在,让我们尝试将带有-invert选项的衍生时钟移至单元UCKBUF1的输出处,看看会发生什么。
● create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM]
● create_generated_clock -name CLKGEN -divide_by 1 -invert -source [get_ports CLKM] [get_pins UCKBUF1/C]
以下是建立时间检查的路径报告:

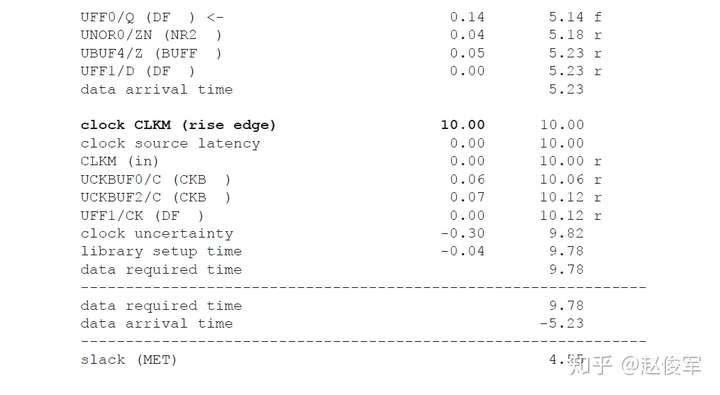
该路径看起来像半周期路径(half-cycle path),但这是不正确的,因为实际逻辑中的时钟路径上没有反相。STA将再次假定UCKBUF1 / C引脚上的时钟为create_Generated_clock命令中指定的时钟。因此,上升沿出现在5ns。捕获时钟为时钟CLKM,其下一个上升沿发生在10ns处。下面的保持时间检查路径报告也会出现与建立时间检查路径相似的异常情况:

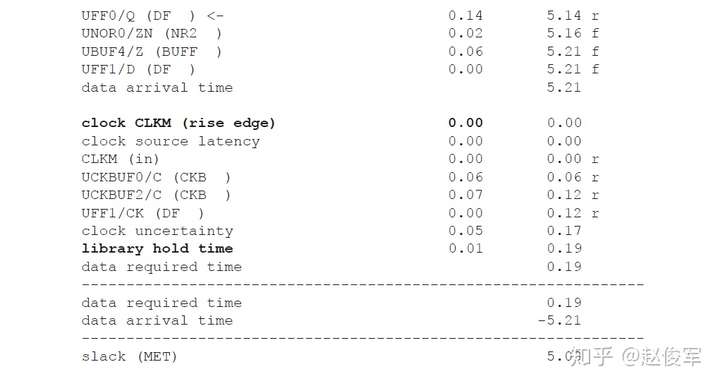
通常,STA输出的结果将包含指示衍生时钟不可实现的错误或警告信息。调试此类不正确路径的最佳方法是在捕获触发器和发起触发器处绘制时钟波形,并尝试了解所示时钟沿是否确实有效。
缺少虚拟时钟延迟
考虑以下路径报告:


这是一条从输入端口开始的路径。请注意,起始的数据到达时间列为0。这表示在时钟VCLKM上未指定延迟,时钟VCLKM用于定义输入引脚RESET_L上的输入到达时间。这很可能是一个虚拟时钟,这就是为什么会缺少数据到达时间的原因。
IO延迟大
当输入或输出路径有时序违例时,首先要检查的是时钟延迟,该延迟用作指定输入到达时间或输出所需时间的参考。这同样适用于前面所讲的例子。
要检查的第二件事是输入或输出延迟,即输入路径上的输入到达时间或输出路径上的输出所需时间。我们可能会发现这些数值对于目标频率是不现实的。输入到达时间通常是时序报告中数据路径的第一个值,而输出所需时间通常是时序报告中数据路径的最后一个值。

在这条时序违例的输入数据路径中,注意输入到达时间为14ns。在这种特殊情况下,输入到达时间约束中会存在一个错误,因为它太大了。
IO缓冲器延迟不正确
当路径经过输入缓冲器或输出缓冲器时,约束不正确可能会导致输入或输出缓冲器延迟值较大。在如下所示的情况中,请注意18ns这个较大的输出缓冲器延迟值,这是由于输出引脚上指定的负载值较大导致的。
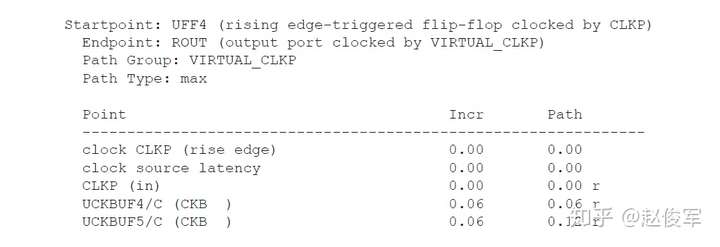
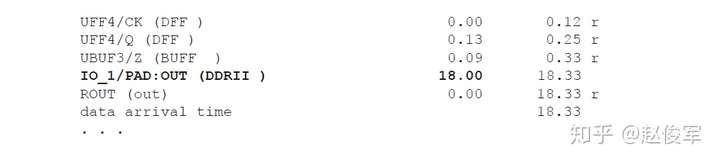
延迟值不正确
当时序路径出现违例时,需要检查的一件事是发起时钟和捕获时钟的延迟是否合理,即确保这些时钟之间的偏斜(skew)在可接受的范围内。错误的延迟约束或生成时钟树时错误的时钟平衡(balancing)可能会导致发起时钟和捕获时钟路径间的较大偏斜,从而导致时序违例。
半周期路径
如前面的示例所述,设计人员需要检查违例路径的时钟域。随之而来的是,设计人员可能需要检查发起和捕获触发器的时钟沿。在某些情况下,可能会发现一个半周期路径(上升沿至下降沿路径或下降沿至上升沿路径)并且可能无法满足半周期路径的时序要求,又或者这些半周期路径不是真实存在的 。
较大的延迟和过渡时间
一个关键事项是要检查沿数据路径的延迟或过渡时间的值是否异常地大,其中一些原因可能是:
● 高扇出网络:未适当缓冲(buffered)的网络。
● 较长网络:需要在中间插入缓冲器的网络。
● 低强度单元:由于在设计中标有“don't touch”,因此未被更换的单元。
● 存储器路径:这些路径通常会由于存储器输入上的建立时间较长以及存储器输出上的输出延迟较大而导致时序违例。
缺少多周期保持时间约束
对于多周期建立时间约束N,常见的是缺少相应的多周期保持时间约束N-1。因此,这可能会导致工具在修复保持时间违例时插入大量不必要的延迟单元。
未优化的路径
STA违例也可能出现在尚未优化的路径上,可以通过检查数据路径来确定这种情况。是否存在延迟较大的单元?可以手动改善数据路径的时序吗?也许数据路径需要进一步优化,工具可能正在其它违例路径上工作。
仍不满足时序的路径
如果数据路径具有强驱动能力的单元,而该路径仍然时序违例,则需要检查布线延迟和线负载较高的引脚。这可能是下一个改进方法:也许可以将单元移动得更近一些,从而可以减少线负载和布线延迟。
如果仍然不满足时序怎么办
可以利用有用偏斜(useful skew)来帮助时序收敛。有用偏斜是指故意使时钟树失衡的地方,尤其是时序违例路径的发起时钟和捕获时钟路径,从而使时序在该路径上收敛。通常,这意味着可以延迟捕获时钟,以使捕获触发器的时钟在数据准备就绪稍后到达。当然,这假定了后续数据路径(即下一级触发器到触发器的数据路径)上有足够的裕量。
也可以尝试相反的操作,也就是说,可以使发起时钟路径更短,以便更早地发起来自发起触发器的数据,从而帮助满足建立时间要求。同样,只有在前一级触发器到触发器路径具有多余的裕量时,才能做到这一点。
有用偏斜技术不仅可用于修复建立时间违例,还可用于修复保持时间违例。此技术的一个缺点是,如果设计具有多种操作模式,则有用偏斜可能会在另一种模式下引起问题。
验证时序约束
随着芯片尺寸的增长,将越来越依赖静态时序分析所交付的时序。仅依赖STA的风险在于STA取决于时序约束的合理与否。因此,时序约束的验证成为重要的考虑因素。
检查路径例外
有一些工具可以根据设计的结构(网表)检查伪路径和多周期路径的有效性,这些工具会检查指定的伪路径或多周期路径约束是否有效。此外,这些工具还可能可以根据设计的结构生成缺少的伪路径和多周期路径约束。但是,这些工具生成的某些路径例外(path exception)也可能是无效的。这是因为这些工具通常使用形式验证技术(formal verification techniques)通过逻辑结构来确定伪路径或多周期路径,而设计人员对设计的功能行为有更深入的了解。因此,在接受并在STA中使用它们之前,设计人员需要检查工具生成的路径例外。可能还存在其它基于设计语义行为的路径例外,如果工具无法提取此类路径例外,设计者必须手动定义这些路径例外。
时序约束中最大的风险就是路径例外。因此,应在仔细分析设计后确定出伪路径和多周期路径。通常,相比于伪路径,最好使用多周期路径,这确保了该路径至少受到一定程度的约束。如果在已知或可预期的时间会对信号进行采样,则无论信号离时钟沿有多远,都应使用多周期路径,这样静态时序分析至少可以知道一些时序约束的信息。伪路径可能会导致时序优化工具完全忽略这些路径,而实际上,它们确实可能在经过大量时钟周期后才被采样。
检查跨时钟域
可用工具来确保设计中所有的跨时钟域均有效,这些工具还可以自动生成必要的伪路径约束。这样的工具也可能可以识别出非法(illegal)的跨时钟域,即数据在没有任何时钟同步逻辑的情况下跨越了两个不同时钟域。在这种情况下,这些工具可以提供在需要时自动插入合适的时钟同步逻辑的功能。请注意,并非所有跨异步时钟域都需要时钟同步器,应该取决于数据性质以及是否需要在下一个周期或几个周期后捕获数据。
使用STA检查跨异步时钟域的另一种方法是设置一个很大的时钟不确定度(uncertainty),该不确定度等于采样时钟的周期。这样可以确保至少存在一些时序违例行为,根据这些时序违例行为,可以确定适当的路径例外,或者将时钟同步逻辑添加到设计中。
验证IO和时钟约束
验证IO和时钟约束仍然是一个挑战,设计人员会经常进行时序仿真以检查设计中所有时钟的有效性。可以进行系统级时序仿真来验证IO时序,以确保芯片可以与其外围设备通信且没有任何时序问题。
附录A:SDC
本附录将介绍1.7版本的SDC格式,此格式主要用于指定设计的时序约束。它不包含任何特定工具的命令,例如链接(link)和编译(compile)。它是一个文本文件,可以手写或由程序创建,并由程序读取。某些SDC命令仅适用于实现(implementation)或综合(synthesis),但是本附录会列出所有SDC命令。
SDC语法是基于TCL的格式,即所有命令都遵循TCL语法。一个SDC文件会在文件开头包含SDC版本号,其次是设计约束,注释(注释以字符#开始,并在行尾处结束)在SDC文件中可以散布在设计约束中。设计约束中较长的命令行可以使用反斜杠()字符分成多行。
A.1 基本命令
以下是SDC中的基本命令:
● current_instance [instance_pathname]
上述命令设置了设计的当前实例,这允许其它命令从该实例中设置或获取属性(attribute)。如果未提供任何参数,则当前实例将成为顶层(top-level)。
例子:
● current_instance /core/U2/UPLL
● current_instance .. (向上一层)
● current_instance (设为顶层)
● expr arg1 arg2 ... argn
● list arg1 arg2 ... argn
● set variable_name value
● set_hierarchy_separator separator
上述命令指定了SDC文件中使用的默认层次结构分隔符。在允许的情况下,可以通过在各个SDC命令中使用-hsc选项来覆盖此设置。
例子:
● set_hierarchy_separator /
● set_hierarchy_separator .
● set_units [-capacitance cap_unit] [-resistance res_units] [-time time_unit] [-voltage voltage_unit] [-current current_unit] [-power power_unit]
上述命令指定了SDC文件中使用的单位。
例子:
● set_units -capacitance pf -time ps
A.2 对象访问命令
以下命令指定了如何访问设计实例中的对象。
all_clocks命令会返回一个所有时钟的集合:
● foreach_in_collection clkvar [all_clocks]
● set_clock_transition 0.150 [all_clocks]
all_inputs [-level_sensitive] [-edge_triggered] [-clock clock_name] 命令会返回一个设计中所有输入端口的集合:
● set_input_delay -clock VCLK 0.6 -min [all_inputs]
all_outputs [-level_sensitive] [-edge_triggered] [-clock clock_name] 命令会返回一个设计中所有输出端口的集合:
● set_load 0.5 [all_outputs]
all_registers [-no_hierarchy] [-clock clock_name] [-rise_clock clock_name] [-fall_clock clock_name] [-cells] [-data_pins] [-clock_pins] [-slave_clock_pins] [-async_pins] [-output_pins] [-level_sensitive] [-edge_triggered] [-master_slave] 命令会返回一个具有指定属性的寄存器的集合:
● all_registers -clock DAC_CLK
上述这个命令返回的集合中为所有由时钟DAC_CLK触发的寄存器。
current_design [design name] 命令会返回当前设计的名称。如果使用参数指定,则将会设置当前设计为指定的名称:
● current_design FADD
● current_design
get_cells [-hierarchical] [-hsc separator] [-regexp] [-nocase] [-of_objects objects] patterns 命令会返回一个设计中与指定模型(pattern)匹配的单元的集合,通配符可用于匹配多个单元:
● get_cells RegEdge*
● foreach_in_collection cvar [get_cells -hierarchical *]
get_clocks [-regexp] [-nocase] patterns 命令会返回一个设计中与指定模型匹配的时钟的集合。当在-from或-to等上下文中使用时,它将返回一个由指定时钟驱动的所有触发器的集合:
● set_propagated_clock [get_clocks SYS_CLK]
● set_multicycle_path -to [get_clocks jtag*]
get_lib_cells [-hsc separator] [-regexp] [-nocase] patterns 命令会创建一个当前正在加载的库中并且与指定模型匹配的库单元的集合:
● get_lib_cells cmos131v/AOI3*
get_lib_pins [-hsc separator] [-regexp] [-nocase] patterns 命令会返回一个与指定模型匹配的库单元引脚的集合。
get_libs [-regexp] [-nocase] patterns 命令会返回一个设计中当前加载的库的集合。
get_nets [-hierarchical] [-hsc separator] [-regexp] [-nocase] [-of_objects objects] patterns 命令会返回一个与指定模型匹配的网络的集合:
● get_nets -hierarchical *
● get_nets FIFO_patt*
get_pins [-hierarchical] [-hsc separator] [-regexp] [-nocase] [-of_objects objects] patterns 命令会返回一个与指定模型匹配的引脚名称的集合:
● get_pins *
● get_pins U1/U2/U3/UAND/Z
get_ports [-regexp] [-nocase] patterns 命令会返回一个与指定模型匹配的设计(输入和输出)端口名称的集合:
● foreach_in_collection port_name [get_ports clk*]
可以在不“获取”对象的情况下引用诸如端口(port)之类的对象吗?当设计中只有一个具有该名称的对象时,实际上没有任何区别。但是,当多个对象具有相同的名称时,使用get_ * 命令将变得更加重要,它可以避免在引用哪种类型对象方面所带来的任何可能的混淆。假设有一个名为BIST_N1的网络和一个名为BIST_N1的端口,考虑以下SDC命令:
● set_load 0.05 BIST_N1
问题是要引用哪个BIST_N1?网络还是端口?在大多数情况下,最好明确表明对象的类型,例如:
● set_load 0.05 [get_nets BIST_N1]
现在再假设有一个时钟MCLK和另一个也称为MCLK的端口,考虑以下SDC命令:
● set_propagated_clock MCLK
该对象是引用名为MCLK的端口还是引用称为MCLK的时钟?在此特定情况下,它指的是时钟,因为这是set_propagated_clock命令的优先级所选择的。但是,要明确一点,最好明确表明对象类型,如下所示:
● set_propagated_clock [get_clocks MCLK]
● set_propagated_clock [get_ports MCLK]
有了这种明确的条件申明,就不必依赖优先级规则了,并且SDC命令会非常清楚。
A.3 时序约束
本节将介绍与时序约束有关的SDC命令。
create_clock -period period_value [-name clock_name] [-waveform edge_list] [-add] [source_objects] 命令可用于定义时钟。如果未指定clock_name,则时钟名称将是第一个源对象的名称。-period选项指定时钟周期,-add选项用于在已经具有时钟定义的引脚上创建时钟。否则,如果不使用此选项,则此时钟定义将覆盖该节点上任何其它现有的时钟定义。-waveform选项指定时钟的上升沿和下降沿(占空比),默认值为(0,period / 2)。如果时钟定义的节点位于另一个时钟之后的路径上,则它将阻塞该点之前一个时钟。
例子:
● create_clock -period 20 -waveform {0 6} -name SYS_CLK [get_ports SYS_CLK]
● create_clock -name CPU_CLK -period 2.33 -add [get_ports CPU_CLK]
create_generated_clock [-name clock_name] [-source master_pin] [-edges edge_list] [-divide_by factor] [-multiply_by factor] [-duty_cycle percent] [-invert] [-edge_shift shift_list] [-add] [-master_clock clock] [-combinational] [source_objects] 命令可用于定义内部的衍生时钟。如果未指定-name,则时钟名称为第一个源对象的名称。-source指定衍生时钟的源是设计中的引脚或端口。如果有多个时钟输入源节点,必须使用-master_clock选项指定将这些时钟中的哪一个用作衍生时钟的源。-divide_by选项用于指定时钟的分频系数,与-multiply_by类似。-duty_cycle可以用于指定时钟的占空比。如果时钟的相位已反转,则可以指定-invert选项。除了使用时钟倍频或分频,还可以使用-edges和-edge_shift选项指定衍生时钟。-edges选项指定一个由三个数字组成的列表,该列表指定用于第一个上升沿、下一个下降沿和下一个上升沿的主时钟边沿。例如,可以将时钟分频器指定为-divide_by 2或-edges {1 3 5}。-edge_shift选项可以与-edges选项一起使用,以指定三个边沿中每个边沿的偏移量。
例子:
● create_generated_clock -divide_by 2 -source [get_ports sys_clk] -name gen_sys_clk [get_pins UFF/Q]
● create_generated_clock -add -invert -edges {1 2 8} -source [get_ports mclk] -name gen_clk_div
● create_generated_clock -multiply_by 3 -source [get_ports ref_clk] -master_clock clk10MHz [get_pins UPLL/CLKOUT] -name gen_pll_clk
group_path [-name group_name] [-default] [-weight weight_value] [-from from_list] [-rise_from from_list] [-fall_from from_list] [-to to_list] [-rise_to to_list] [-fall_to to_list] [-through through_list] [-rise_through through_list] [-fall_through through_list] 命令可以为指定的路径组命名。
set_clock_gating_check [-setup setup_value] [-hold hold_value] [-rise] [-fall] [-high] [-low] [object_list] 命令可以提供对任何对象指定时钟门控检查的功能。时钟门控检查仅在具有时钟信号的逻辑门处执行,默认情况下建立时间和保持时间值为0。
例子:
● set_clock_gating_check -setup 0.15 -hold 0.05 [get_clocks ck20m]
● set_clock_gating_check -hold 0.3 [get_cells U0/clk_divider/UAND1]
set_clock_groups [-name name] [-logically_exclusive] [-physically_exclusive] [-asynchronous] [-allow_paths] -group clock_list 命令指定了一组具有特定属性的时钟,并为该组分配了一个名称。
set_clock_latency [-rayise] [-fall] [-min] [-max] [-source] [-late] [-early] [-clock clock_list] delay object_list 命令指定给定时钟的时钟延迟。有两种类型的延迟:网络延迟和源延迟。源延迟是时钟定义引脚与其源之间的时钟网络延迟,而网络延迟是时钟定义引脚与触发器时钟引脚之间的时钟网络延迟。
例子:
● set_clock_latency 1.86 [get_clocks clk250]
● set_clock_latency -source -late -rise 2.5 [get_clocks MCLK]
● set_clock_latency -source -late -fall 2.3 [get_clocks MCLK]
set_clock_sense [-positive] [-negative] [-pulse pulse] [-stop_propagation] [-clock clock_list] pin_list 命令在引脚上设置时钟属性。
set_clock_transition [-rise] [-fall] [-min] [-max] transition_clock_list 命令指定时钟定义点处的时钟过渡时间。
例子:
● set_clock_transition -min 0.5 [get_clocks SERDES_CLK]
● set_clock_transition -max 1.5 [get_clocks SERDES_CLK]
set_clock_uncertainty [-from from_clock] [-rise_from rise_from_clock] [-fall_from fall_from_clock] [-to to_clock] [-rise_to rise_to_clock] [-fall_to fall_to_clock] [-rise] [-fall] [-setup] [-hold] uncertainty [object_list] 命令指定了时钟或时钟到时钟传输的时钟不确定度。STA将从路径的数据需要到达时间中减去建立时间不确定度,并将保持时间不确定度增加到路径的数据需要到达时间中。
例子:
● set_clock_uncertainty -setup -rise -fall 0.2 [get_clocks CLK2]
● set_clock_uncertainty -from [get_clocks HSCLK] -to [get_clocks SYSCLK] -hold 0.35
set_data_check [-from from_object] [-to to_object] [-rise_from from_object] [-fall_from from_object] [-rise_to to_object] [-fall_to to_object] [-setup] [-hold] [-clock clock_object] value 命令在两个数据引脚之间执行指定的检查。
例子:
● set_data_check -from [get_pins UBLK/EN] -to [get_pins UBLK/D] -setup 0.2
set_disable_timing [-from from_pin_name] [-to to_pin_name] cell_pin_list 命令中断了指定单元内的时序弧。
例子:
● set_disable_timing -from A -to ZN [get_cells U1]
set_false_path [-setup] [-hold] [-rise] [-fall] [-from from_list] [-to to_list] [-through through_list] [-rise_from rise_from_list] [-rise rise_to_list] [-rise_through rise_through_list] [-fall_from fall_from_list] [-fall_to fall_to_list] [-fall_through fall_through_list] 命令指定了STA不需要考虑的路径例外。
● set_false_path -from [get_clocks jtag_clk] -to [get_clocks sys_clk]
● set_false_path -through U1/A -through U4/ZN
set_ideal_latency [-rise] [-fall] [-min] [-max] delay object_list 命令用于为特定对象设置理想的延迟。
set_ideal_network [-no_propagate] object_list 命令将指定设计中理想网络的源节点。
set_ideal_transition [-rise] [-fall] [-min] [-max] transition_time object_list 命令将指定理想网络的过渡时间。
set_input_delay [-clock clock_name] [-clock_fall] [-rise] [-fall] [-max] [-min] [-add_delay] [-network_latency_included] [-source_latency_included] delay_value port_pin_list 命令将指定相对于指定时钟的输入端口数据到达时间,默认为时钟的上升沿。-add_delay选项允许向该引脚或端口添加多个约束,可以使用此-add_delay选项将时钟设置为不同的时钟。默认情况下,会将发起时钟的时钟源延迟添加到输入延迟值中,但是当指定了-source_latency_included选项时,由于假设已将源网络延迟添加到了输入延迟值中,因此不再添加源网络延迟。-max选项指定的延迟用于建立时间和恢复时间检查,而-min选项指定的延迟用于保持时间和撤销时间检查。如果仅指定-min或-max或两者均未指定,则两者将使用相同的值。
例子:
● set_input_delay -clock SYSCLK 1.1 [get_ports MDIO*]
● set_input_delay -clock virtual_mclk 2.5 [all_inputs]
set_max_delay [-rise] [-fall] [-from from_list] [-to to_list] [-through through_list] [-rise_from rise_from_list] [-rise_to rise_to_list] [-rise_through rise_through_list] [-fall_from fall_from_list] [-fall_to fall_to_list] [-fall_through fall_through_list] delay_value 命令用于设置指定路径上的最大延迟。这个命令用于指定两个任意引脚之间的延迟,而不是从一个触发器到另一个触发器的延迟。
例子:
● set_max_delay -from [get_clocks FIFOCLK] -to [get_clocks MAINCLK] 3.5
● set_max_delay -from [all_inputs] -to [get_cells UCKDIV/UFF1/D] 2.66
set_max_time_borrow delay_value object_list 命令可用于设置在分析锁存器路径时可以借用的最长时间。
例子:
● set_max_time_borrow 0.6 [get_pins CORE/CNT_LATCH/D]
set_min_delay [-rise] [-fall] [-from from_list] [-to to_list] [-through through_list] [-rise_from rise_from_list] [-rise_to rise_to_list] [-rise_through rise_through_list] [-fall_from fall_from_list] [-fall_to fall_to_list] [-fall_through fall_through_list] delay_value 命令用于设置指定路径上的最小延迟,该延迟可以在任意两个引脚之间。
例子:
● set_min_delay -from U1/S -to U2/A 0.6
● set_min_delay -from [get_clocks PCLK] -to [get_pins UFF/*/S]
set_multicycle_path [-setup] [-hold] [-rise] [-fall] [-start] [-end] [-from from_list] [-to to_list] [-through through_list] [-rise_from rise_from_list] [-rise_to rise_to_list] [-rise_through rise_through_list] [-fall_from fall_from_list] [-fall_to fall_to_list] [-fall_through fall_through_list] path_multiplier 命令将路径指定为多周期路径,可以使用多个-through选项。如果多周期路径仅用于建立时间检查,请使用-setup选项,而如果多周期路径用于保持时间检查,请使用-hold选项。如果-setup或-hold均未指定,则默认为-setup且默认的保持时间周期为0。-start选项指定了时钟周期数使用的是发起时钟的 ,而-end选项指定使用的是捕获时钟的,默认值为-start。-hold选项指定的时钟周期数表示需要偏离默认多周期保持时间值0的时钟沿数。
例子:
● set_multicycle_path -start -setup -from [get_clocks PCLK] -to [get_clocks MCLK] 4
● set_multicycle_path -hold -from UFF1/Q -to UCNTFF/D 2
● set_multicycle_path -setup -to [get_pins UEDGEFF*] 4
set_output_delay [-clock clock_name] [-clock_fall] [-level_sensitive] [-rise] [-fall] [-max] [-min] [-add_delay] [-network_delay_included] [-source_latency_included] delay_value port_pin_list 命令可以指定相对于时钟的输出所需时间,默认是上升沿。默认情况下,时钟源延迟会添加到输出延迟值中,但是当指定-source_latency_included选项时,不会添加时钟延迟值,因为会假定它已包含在输出延迟值中。-add_delay选项可用于在一个引脚/端口上指定多个set_output_delay。
set_propagated_clock object_list 命令指定时钟延迟需要计算,即不是理想的。
● set_propagated_clock [all_clocks]
A.4 环境命令
本节介绍了用于设置待分析设计环境的命令。
set_case_analysis value port_or_pin_list 命令用于指定被设置为常数的端口或引脚。
例子:
● set_case_analysis 0 [get_pins UDFT/MODE_SEL]
● set_case_analysis 1 [get_ports SCAN_ENABLE]
set_drive [-rise] [-fall] [-min] [-max] resistance port_list 命令用于指定输入端口的驱动强度,它指定端口的外部驱动电阻,值为0表示驱动强度是最高的。
例子:
● set_drive 0 {CLK RST}
set_driving_cell [-lib_cell lib_cell_name] [-rise] [-fall] [-library lib_name] [-pin pin_name] [-from_pin from_pin_name] [-multiply_by factor] [-dont_scale] [-no_design_rule] [-input_transition_rise rise_time] [-input_transition_fall fall_time] [-min] [-max] [-clock clock_name] [-clock_fall] port_list 命令用于模拟驱动输入端口的单元的驱动电阻。
例子:
● set_driving_cell -lib_cell BUFX4 -pin ZN [all_inputs]
set_fanout_load value port_list 命令在输出端口上设置指定的扇出负载。
例子:
● set_fanout_load 5 [all_outputs]
set_input_transition [-rise] [-fall] [-min] [-max] [-clock clock_name] [-clock_fall] transition port_list 命令指定了输入端口上的过渡时间。
例子:
● set_input_transition 0.2 [get_ports SD_DIN*]
● set_input_transition -rise 0.5 [get_ports GPIO*]
set_load [-min] [-max] [-subtract_pin_load] [-pin_load] [-wire_load] value objects 命令用于指定在设计中引脚或网络上的电容性负载的值。-subtract_pin_load选项表示从指定负载中减去引脚电容。
例子:
● set_load 50 [all_outputs]
● set_load 0.1 [get_pins UFF0/Q]
● set_load -subtract_pin_load 0.025 [get_nets UCNT0/NET5]
set_logic_dc port_list 命令、set_logic_one port_list 命令以及set_logic_zero port_list 命令将指定的端口设置为不关心(don't care)、逻辑1或逻辑0。
例子:
● set_logic_dc SE
● set_logic_one TEST
● set_logic_zero [get_pins USB0/USYNC_FF1/Q]
set_max_area area_value 命令指定了当前设计的最大面积限制。
例子:
● set_max_area 20000.0
set_max_capacitance value object_list 命令指定了端口或设计中的最大电容。如果是设计,则指定了设计中所有引脚的最大电容。
● set_max_capacitance 0.2 [current_design]
● set_max_capacitance 1 [all_outputs]
set_max_fanout value object_list 命令指定了端口或设计中的最大扇出值。如果是设计,则指定了设计中所有输出引脚的最大扇出值。
● set_max_fanout 16 [get_pins UDFT0/JTAG/ZN]
● set_max_fanout 50 [current_design]
set_max_transition [-clock_path] [-data_path] [-rise] [-fall] value object_list 命令指定了端口或设计中的最大过渡时间。如果是设计,则指定了设计中所有引脚上的最大过渡时间。
例子:
● set_max_transition 0.2 UCLKDIV0/QN
set_min_capacitance value object_list 命令指定了设计中端口或引脚上的最小电容值。
例子:
● set_min_capacitance 0.05 UPHY0/UCNTR/B1
set_operating_conditions [-library lib_name] [-analysis_type type] [-max max_condition] [-min min_condition] [-max_library max_lib] [-min_library min_lib] [-object_list objects] [condition] 命令可以设置用于时序分析的工作条件。分析类型可以是single(单个情况),bc_wc(最佳情况/最差情况)或者on_chip_variation(片上变化)。可以使用operating_conditions命令在库中定义工作条件。
例子:
● set_operating_conditions -analysis_type bc_wc
● set_operating_conditions WCCOM
● set_operating_conditions -analysis_type on_chip_variation
set_port_fanout_number value port_list 命令可用于设置端口的最大扇出数。
例子:
● set_port_fanout_number 10 [get_ports GPIO*]
set_resistance [-min] [-max] value list_of_nets 命令可用于设置指定网络上的电阻。
例子:
● set_resistance 10 -min U0/U1/NETA
● set_resistance 50 -max U0/U1/NETA
set_timing_derate [-cell_delay] [-cell_check] [-net_delay] [-data] [-clock] [-early] [-late] derate_value [object_list] 命令指定了降额系数。
set_wire_load_min_block_size size 命令指定了将线负载模型设置为“enclosed”时使用的最小的块大小。
例子:
● set_wire_load_min_block_size 5000
set_wire_load_mode mode_name 命令定义了如何对分层设计(hierarchical design)中的网络使用线负载模型的机制。mode_name可以是top,enclosure或segmented。top模式规定在顶层定义的线负载模型将用于所有较低级别上。enclosure模式规定完全封闭在模块中的网络的线负载模型用于该网络。segmented模式规定模块中的网络段使用该模块的线负载模型。
例子:
● set_wire_load_mode enclosed
set_wire_load_model -name model_name [-library lib_name] [-min] [-max] [object_list] 命令定义了用于当前设计或指定网络的线负载模型。
例子:
● set_wire_load_model -name "eSiliconLightWLM"
set_wire_load_selection_group [-library lib_name] [-min] [-max] group_name [object_list] 命令会在根据块的单元面积确定线负载模型时,为设计设置线负载选择组,该选择组通常在技术库中定义。
A.5 多电压命令
当设计中存在多电压岛(multi-voltage islands)时,以下命令适用。
create_voltage_area -name name [-coordinate coordinate_list] [-guard_band_x float] [-guard_band_y float] cell_list
set_level_shifter_strategy [-rule rule_type]
set_level_shifter_threshold [-voltage float] [-percent float]
set_max_dynamic_power power [unit] 命令指定了最大动态功率。
例子:
● set_max_dynamic_power 0 mw
set_max_leakage_power power [unit] 命令指定了最大漏电功率。
例子:
● set_max_leakage_power 12 mw
附录B:SDF
本附录将介绍标准延迟标注格式,并说明了如何在仿真中执行反标。
延迟格式描述了设计网表的单元延迟和互连走线延迟,无论设计是用两种主要硬件描述语言(VHDL或Verilog HDL)中的哪一种所描述的。
本章还会介绍仿真的反标(backannotation),STA的反标其实是一个简单直接的过程,其中DUA中的时序弧将由SDF所指定的延迟进行标注。
B.1 什么是SDF?
SDF是指标准延迟格式(Standard Delay Format)。它是一个IEEE标准——IEEE Std1497,它是ASCII文本文件,它描述了时序信息和约束,其目的是用作各种工具之间的文本类型的时序信息交换媒介,它也可以用来描述需要它的工具的时序数据。由于它是IEEE标准,因此由一个工具生成的时序信息可以被支持该标准的许多其它工具所使用。SDF中的数据与工具和语言都无关,且包括了互连走线延迟、器件延迟以及时序检查的规范。
由于SDF是ASCII文件,因此它易于阅读,尽管对于实际设计而言,这些文件往往很大。但是,它是作为工具之间的交换媒介。经常在进行信息交换时,一个工具可能会在生成SDF文件时产生一个问题,而另一个读取SDF的工具可能无法正确读取SDF。读取SDF的工具可能会在读取SDF时产生一个错误或警告,或者它可能会错误地解释SDF中的值。在这种情况下,设计人员可能必须查看SDF文件,看看出了什么问题。本章介绍了SDF文件的基础知识,并提供了必要和足够的信息,以帮助理解和调试任何标注问题。
图B-1显示了如何使用SDF文件的典型流程。时序计算工具通常会生成时序信息存储在SDF文件中。然后,通过读取SDF的工具将该信息反标到设计中。请注意,完整的设计信息不会都存储到SDF文件中,而只会存储延迟值。例如,实例名称和实例的引脚名称将被存储到SDF文件中,因为它们对于指定实例相关或引脚相关的延迟是必需的。因此,必须为SDF生成工具和SDF读取工具提供相同的设计。
一个设计可以具有多个与之关联的SDF文件。可以为一个设计创建一个SDF文件,在分层设计中,也可以为分层中的每个块创建多个SDF文件。在标注期间,每个SDF都将应用于适当的分层实例中,如图B-2所示。
SDF文件包含了用于反标和标注的时序数据。更具体地说,它包含:
● 单元延迟(Cell delays)
● 脉冲传播(Pulse propagation)
● 时序检查(Timing checks)
● 互连走线延迟(Interconnect delays)
● 时序环境(Timing environment)
引脚到引脚的延迟(pin-to-pin delay)和分布式延迟(distributed delay)都可以针对单元延迟进行建模。引脚到引脚的延迟使用IOPATH结构(construct)表示,这些结构定义了每个单元输入到输出的路径延迟。COND结构还可以用于额外指定有条件的引脚到引脚延迟。状态相关(state-dependent)的路径延迟也可以使用COND结构来指定,分布式延迟的建模是使用DEVICE结构指定的。
脉冲传播结构——PATHPULSE和PATHPULSEPERCENT可用于指定使用引脚到引脚延迟模型时允许传播到单元输出端口的毛刺大小。
可以在SDF中指定的时序检查包括:
● 建立时间:SETUP,SETUPHOLD
● 保持时间:HOLD,SETUPHOLD
● 恢复时间:RECOVERY,RECREM
● 撤销时间:REMOVAL,RECREM
● 最大偏斜:SKEW,BIDIRECTSKEW
● 最小脉冲宽度:WIDTH
● 最小周期:PERIOD
● 不变化:NOCHANGE
时序检查中的信号可能存在某些条件。在时序检查中允许使用负值,不支持负值的工具可以选择将其替换为零。
SDF描述中支持三种类型的互连走线建模。INTERCONNECT结构是最通用且最常用的,可用于指定点对点延迟(从源端到接收端),因此单个网络可以具有多个INTERCONNECT结构。PORT结构可用于指定负载端口处的网络延迟,假定网络只有一个源端驱动。NETDELAY结构可用于指定整个网络的延迟,而无需考虑其源端或接收端,因此是指定网络上延迟的最不具体的方法。
时序环境提供了设计在工作时所依据的信息,这些信息包括ARRIVAL,DEPARTURE,SLACK和WAVEFORM结构。这些结构主要用于标注,例如可用于综合。
B.2 SDF格式
SDF文件包含一个首部(header section),后跟一个或多个单元。每个单元代表设计中的一个区域或范围,它可以是库原语(primitive)或用户自定义的黑盒。


首部包含一般信息,除了层次结构分隔符、时间刻度(timescale)和SDF版本号外,都不会影响SDF文件的语义。默认情况下,层次结构分隔符DIVIDER是点字符(“.”)。通过以下方法,可以将其替换为“/”字符:
● (DIVIDER /)
如果首部中没有时间刻度信息,则默认值为1ns。否则,可以使用以下命令明确指定时间刻度TIMESCALE:
● (TIMESCALE 10ps)
也就是说,将SDF文件中指定的所有延迟值乘以10ps。
SDF版本号SDFVERSION是必需的,SDF文件的使用者会根据它来确保文件符合指定的SDF版本。首部中可能存在的其它信息(属于常规信息类别)包括日期、程序名称、版本和工作条件。

首部之后是一个或多个单元的描述,每个单元在设计中代表一个或多个实例(使用通配符),单元可以是库原语或分层块(hierarchical block)。

单元的顺序很重要,因为数据是从上到下进行处理的。后面的单元描述可以覆盖前面的单元描述所指定的时序信息(通常,两次定义同一单元实例的时序信息并不常见)。另外,可以将时序信息标注为绝对值或增量的形式。如果时序信息使用增量的形式,它将会把新值添加到现有值中。而如果时序信息是绝对值,它将覆盖任何先前指定的时序信息。
单元实例可以是分层实例名称。用于层次结构分隔的分隔符必须符合首部中指定的分隔符。单元实例名称可以选择为“ * ”字符,即通配符,这表示指定类型的所有单元实例。

单元中可以描述四种类型的时序规范:
● DELAY:用于描述延迟
● TIMINGCHECK:用于描述时序检查
● TIMINGENV:用于描述时序环境
● LABEL:声明可用于描述延迟的时序模型变量。
以下是一些例子:

DELAY时序规范有四种类型:
● ABSOLUTE:在反标期间替换单元实例的现有延迟值。
● INCREMETN:将新的延迟数据添加到单元实例的任何现有延迟值。
● PATHPULSE:指定设计输入和输出之间的脉冲传播极限。此极限值用于决定是将出现在输入上的脉冲传播到输出,还是将其标记为“ X ”,或者将其滤除。
● PATHPULSEPERCENT:除了值以百分比表示外,这与PATHPULSE完全相同。
以下是一些例子:
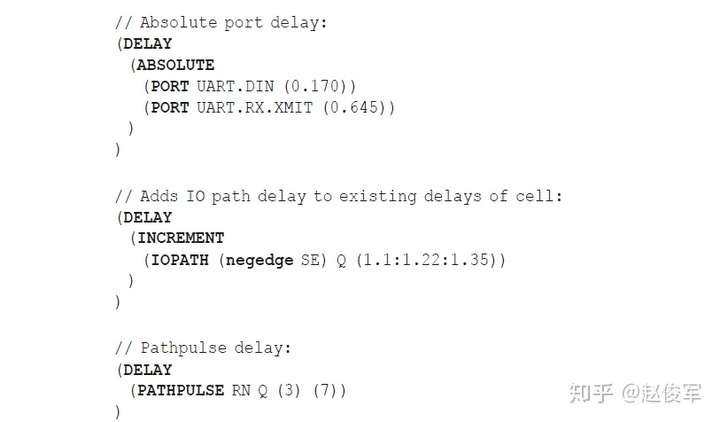

RN和Q是单元的输入端口和输出端口。第一个值3是脉冲抑制极限(pulse rejection limit),称为r-limit,它定义了可以出现在输出上的最窄脉冲。窄于此的任何脉冲都会被拒绝通过,也就是说,它将不会出现在输出上。第二个值7(如果存在)是错误极限(error limit),也称为e-limit。任何小于e-limit的脉冲都会导致输出为“ X ”。e-limit必须大于r-limit,如图B-3所示。 当出现小于3(r-limit)的脉冲时,该脉冲不会传播到输出;当脉冲宽度在3(r-limit)和7(e-limit)之间时,输出为X ;当脉冲宽度大于7(e-limit)时,脉冲会传播到输出且没有任何滤除(unfiltered)。
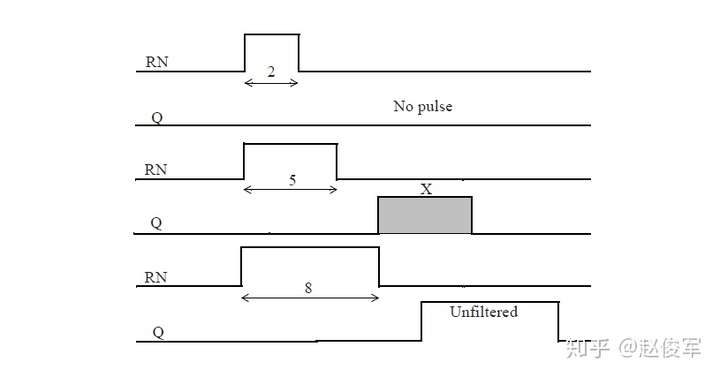
可以使用ABSOLUTE或INCREMENT描述八种延迟定义:
● IOPATH:输入到输出路径的延迟。
● RETAIN:保留时间定义,可以用于指定输出端口在其相关输入端口改变后应保留其先前值的时间。
● COND:条件路径延迟,可以用于指定状态相关的输入到输出路径延迟。
● CONDELSE:默认路径延迟,可以用于指定条件路径的默认值。
● PORT:端口延迟,可以用于指定互连走线延迟,该延迟被建模为输入端口的延迟。
● INTERCONNECT:互连走线延迟,可以用于指定从其源端到接收端的整个网络的传播延迟。
● NETDELAY:网络延迟,可以用于指定从一个网络的所有源端到所有接收端的传播延迟。
● DEVICE:器件延迟,主要用于描述分布式时序模型,可以用于指定通过单元到输出端口的所有路径的传播延迟。
以下是一些例子:

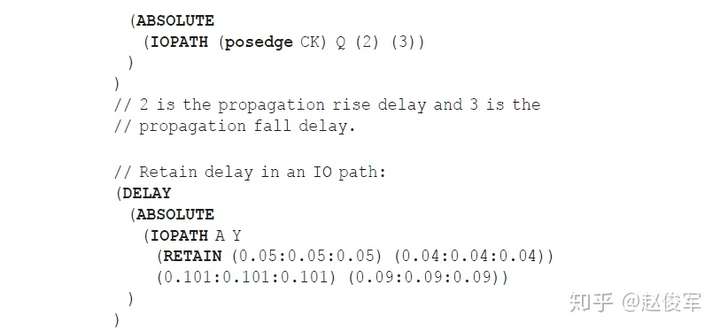
输入A上的值发生更改后,Y将保留其先前值50ps(低电平为40ps)。50ps是保持高电平的值,40ps是保持低电平的值,101ps是传播上升沿延迟,90ps是传播下降沿延迟,如图B-4所示。
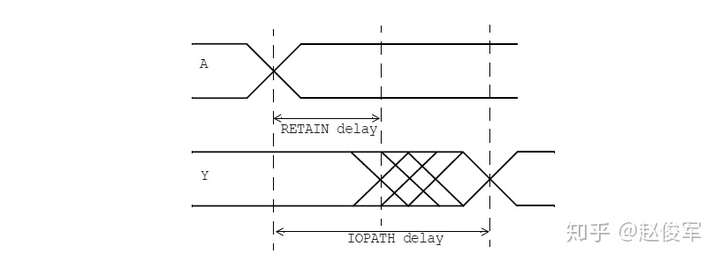

延迟
到目前为止,我们已经看过了许多不同形式的延迟,其实延迟规范还有其它形式。通常,可以将延迟指定为一个、两个、三个、六个或十二个令牌(token)的集合,这些令牌可用于描述以下过渡的延迟:0-> 1、1-> 0、0-> Z,Z-> 1,1-> Z,Z-> 0,0-> X,X-> 1,1-> X,X-> 0,X-> Z,Z-> X。下表展示了如何使用少于十二个延迟令牌来表示十二种过渡情况。
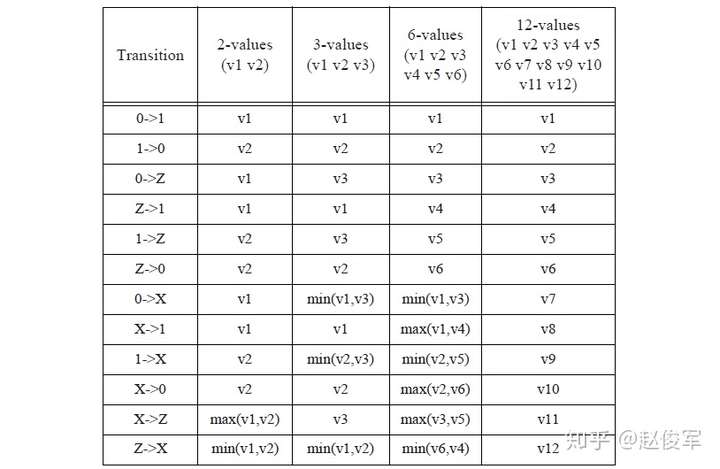
以下是这些延迟的一些示例:


每个延迟令牌可以依次写为一个、两个或三个值,如以下示例所示:


一个SDF文件中的延迟值可以使用有符号的实数或以下形式的三元数组来编写:
● ( 8.0:3.6:9.8 )
为了表示出设计在三个工艺工作条件下的最小、典型以及最大延迟,注释器通常会根据用户提供的选项来决定去选择哪个值。三元数组形式中的值是可选的,但是至少应有一个。例如,以下形式是规范的:
● ( : : 0.22)
● ( 1.001 : : 0.998 )
未指定的值就不会去标注。
时序检查
在以TIMINGCHECK关键字开头的部分中指定了时序检查的极限。在任何这些检查中,可以使用COND结构指定有条件的时序检查。在某些情况下,可以指定两个额外的条件检查SCOND和CCOND,它们与stamp event和check event关联。
以下是一组检查:
● SETUP:建立时间检查
● HOLD:保持时间检查
● SETUPHOLD:建立时间和保持时间检查
● RECOVERY:恢复时间检查
● REMOVAL:撤销时间检查
● RECREM:恢复时间和撤销时间检查
● SKEW:单向偏斜时序检查
● BIDIRECTSKEW:双向偏斜时序检查
● WIDTH:脉宽时序检查
● PERIOD:周期时序检查
● NOCHANGE:不变化时序检查
以下是一些例子:


标签
标签可用于指定VHDL泛型(generics)或Verilog HDL参数的值。

时序环境
有许多结构可用于描述设计的时序环境。但是,这些结构可用于标注,而不是用于反标,例如在逻辑综合工具中。这些未在本文中描述。
B.2.1 例子
接下去,我们将为两个设计提供完整的SDF文件。
全加器
这是用于全加器(full-adder)电路的Verilog HDL网表(netlist):


以下是时序分析工具生成的完整SDF文件:




INTERCONNECT中的所有延迟均为0,因为这是布局前的数据,因此建模的是理想互连走线模型。
十进制计数器
这是十进制计数器的Verilog HDL模型:

对应的完整SDF文件如下:






B.3 标注过程
在本节中,我们将介绍如何在HDL描述中进行SDF的标注(annotation)。SDF的标注可以通过多种工具执行,例如逻辑综合工具、仿真工具和静态时序分析工具。SDF标注器(annotator)是这些工具的组件,可用于读取SDF、解释并向设计中标注时序值。假定会使用与HDL模型一致的信息创建SDF文件,并且在反标期间使用相同的HDL模型。此外,SDF标注器还需要负责正确解释SDF中的时序值。
SDF标注器标注了反标时序的泛型和参数。如果在语法或映射(mapping)过程中不符合该标准,它将给出错误报告。如果一个SDF标注器不支持某些SDF结构,则不会产生任何错误,标注器将忽略这些错误。
如果SDF标注器未能修改反标时序的泛型,则在反标过程中不会修改泛型的值,即保持不变。
在仿真工具中,反标通常发生在规划(elaboration)阶段之后,紧接在负约束延迟计算之前。
B.3.1 Verilog HDL
在Verilog HDL中,标注的主要机制是指定块(specify block),指定块可以指定路径延迟和时序检查。实际延迟值和时序检查极限值是通过SDF文件指定的,映射是一种行业标准,在IEEE Std 1364中定义。
从SDF文件中获得并在Verilog HDL模块的指定块中标注的信息包括指定路径的延迟、参数值、时序检查约束极限值和互连走线延迟。向一个Verilog HDL模型进行标注时,将忽略SDF文件中的其它结构。SDF中的LABEL部分定义了参数值。通过将SDF结构与相应的Verilog HDL声明进行匹配,然后将现有的时序值替换为SDF文件中的时序值,即可完成反标。
下表显示了SDF延迟值如何映射到Verilog HDL延迟值:
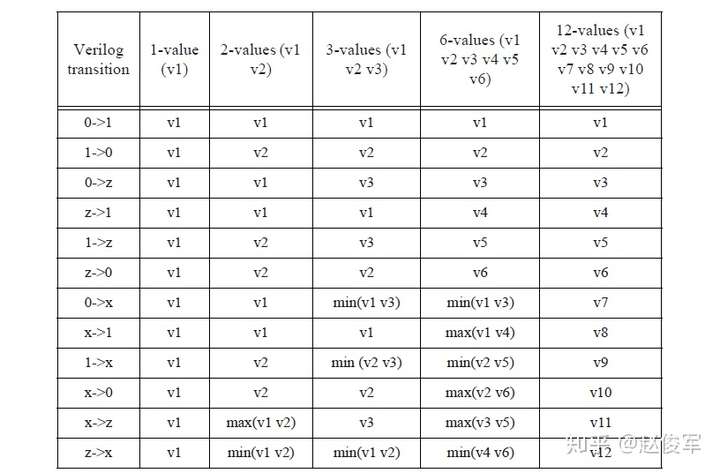
下表描述了SDF结构到Verilog HDL结构的映射:
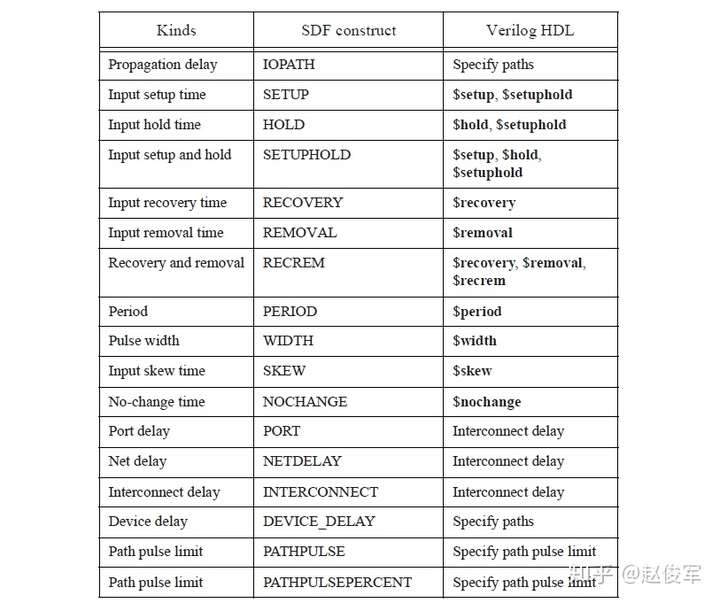
有关示例,请参见后面部分。
B.3.2 VHDL
SDF到VHDL的标注是一个行业标准,它在VITAL ASIC建模规范的IEEE标准IEEE Std 1076.4中定义,该标准的其中一部分描述了SDF延迟到ASIC库的标注。在这里,我们仅介绍与SDF映射有关的VITAL标准的相关部分。
SDF可用于直接在符合VITAL的模型中修改反标时序泛型,只能使用SDF为符合VITAL的模型指定时序数据。有两种方法可以将时序数据传递到VHDL模型中:通过配置,或直接传递到仿真中去。SDF标注过程包括在仿真期间在符合VITAL的模型中映射SDF结构和相应的泛型。
在符合VITAL的模型中,存在着有关如何命名和声明泛型的规则,以确保可以在模型的时序泛型和相应的SDF时序信息之间建立映射。
时序泛型由泛型名称及其类型组成,名称指定时序信息的种类,类型指定时序值的种类。如果泛型名称不符合VITAL标准,则它不是时序泛型,也不会被标注。
下表显示了SDF延迟值如何映射到VHDL延迟:
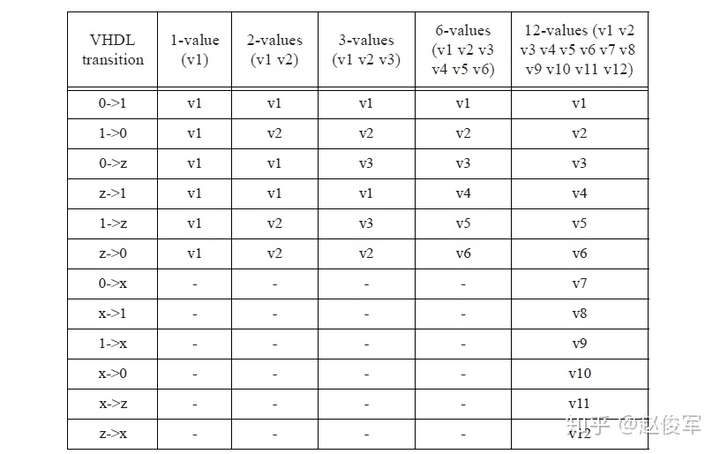
在VHDL中,时序信息是通过泛型进行反标的。泛型名称遵循一定的规则,以便保持一致或从SDF结构中获取。利用每个时序泛型名称,可以指定条件边沿的可选后缀。边沿可以指定一个与时序信息相关联的边沿。
下表列出了各种时序泛型名称:
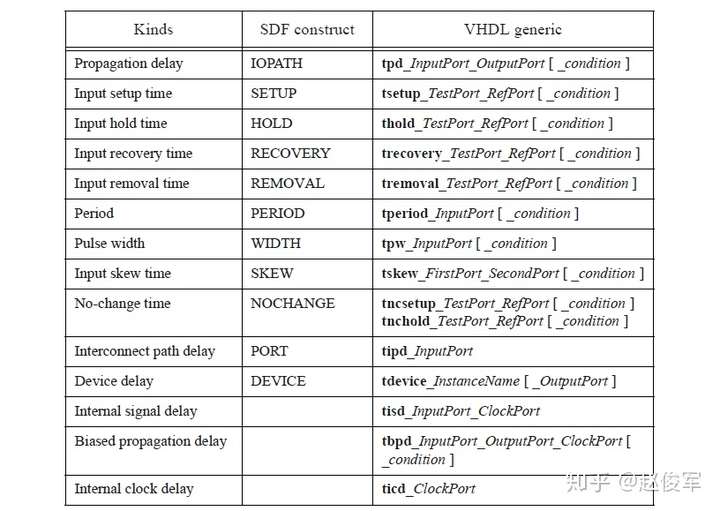
B.4 映射示例
以下是将SDF结构映射到VHDL泛型(generic)和Verilog HDL声明(declaration)的示例。
传播延迟
● 从输入端口A到输出端口Y的传播延迟:上升时间为0.406,下降时间为0.339:

● 从输入端口OE到输出端口Y的传播延迟:上升时间为0.441,下降时间为0.409。最小、标准和最大延迟是相同的:

● 从输入端口S0到输出端口Y的条件传播延迟:


● 从输入端口A到输出端口Y的条件传播延迟:

● 从输入端口CK到输出端口Q的传播延迟:

● 从输入端口A到输出端口Y的条件传播延迟:

● 从输入端口CK到输出端口ECK的传播延迟:
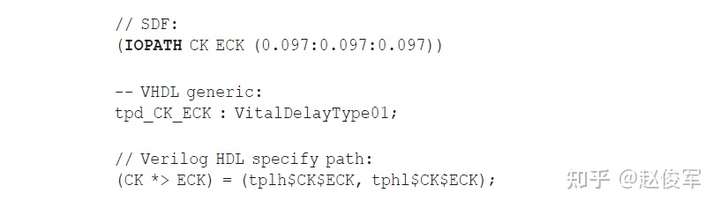
● 从输入端口CI到输出端口S的条件传播延迟:


● 从输入端口CS到输出端口S的条件传播延迟:

● 从输入端口A到输出端口ICO的条件传播延迟:

● 从输入端口A到输出端口CO的条件传播延迟:

● 从CK的上升沿到Q的延迟:


输入建立时间
● D的上升沿与CK的上升沿之间的建立时间:
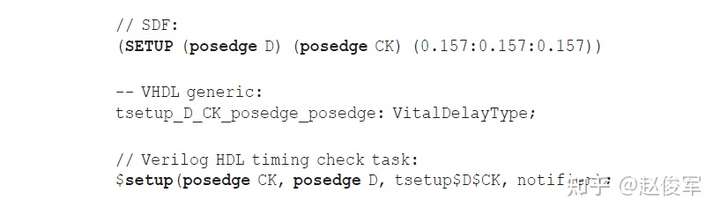
● D的下降沿与CK的上升沿之间的建立时间:

● 输入端口E的上升沿与参考CK的上升沿之间的建立时间:

● 输入端口E的下降沿和参考CK的上升沿之间的建立时间:

● SE和CK之间的条件建立时间:

输入保持时间
● D的上升沿与CK的上升沿之间的保持时间:

● RN与SN之间的保持时间:

● 输入端口SI与参考端口CK之间的保持时间:

● E和CK上升沿之间的条件保持时间:

输入建立和保持时间
● 在D和CLK之间的建立时间与保持时间检查。这是一个有条件的检查,第一个延迟值是建立时间,第二个延迟值是保持时间:
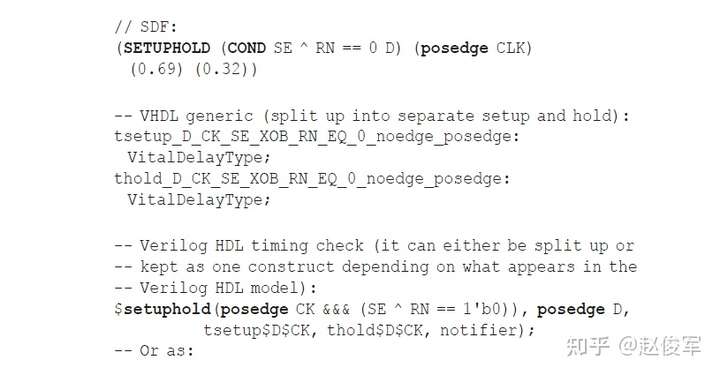

输入恢复时间
● CLKA和CLKB之间的恢复时间:

● CLKA上升沿与CLKB上升沿之间的条件恢复时间:

● SE与CK之间的恢复时间:

● RN与CK之间的恢复时间:

输入撤销时间
● E的上升沿与CK的下降沿之间的撤销时间:


● CK的上升沿和SN之间的条件撤销时间:

周期
● 输入CLKB的周期:

● 输入端口EN的周期:


● 输入端口TCK的周期:

脉宽
● CK上高脉冲的脉冲宽度:
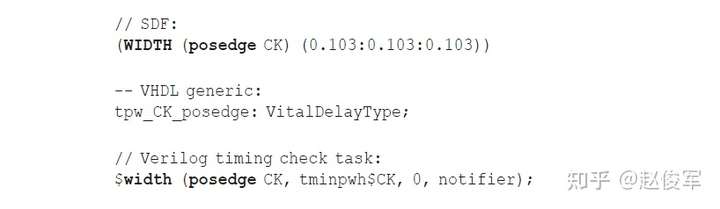
● CK上低脉冲的脉冲宽度:


● RN上高脉冲的脉冲宽度:

输入偏斜时间
● CK与TCK之间的偏斜:

● SE和CK下降沿之间的偏斜:


无变化的建立时间
SDF文件中的NOCHANGE结构将同时映射到VHDL中的tncsetup和tnchold泛型。
● D和CK下降沿之间无变化的建立时间:

无变化的保持时间
SDF文件中的NOCHANGE结构将同时映射到VHDL中的tncsetup和tnchold泛型。
● E和CLKA之间无变化的条件保持时间:


端口延迟
● 端口OE的延迟:

● 端口RN的延迟:

网络延迟
● 连接到端口CKA的网络延迟:

互连路径延迟
● 从端口Y到端口D的互连路径延迟:
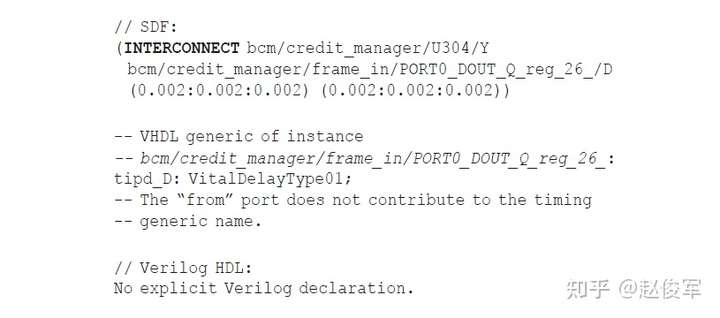
器件延迟
● 实例uP的输出SM的器件延迟:

B.5 完整语法
以下是使用BNF格式显示的SDF的完整语法。终端(terminal)名称是大写的,关键字是粗体的,但是不区分大小写。起始的终端是delay_file:












附录C:SPEF
本附录将介绍标准寄生参数提取格式(SPEF),它是IEEE Std 1481标准的一部分。
C.1 基础
SPEF允许以ASCII交换格式描述设计的寄生信息(R,L和C)。用户可以读取和检查SPEF文件中的值,尽管用户永远不会手动创建此文件。它主要用于将寄生信息从一个工具传递到另一个工具。图C-1显示了SPEF可以由诸如布局布线工具或寄生参数提取工具之类的工具生成,然后交由时序分析工具用于电路仿真或执行串扰分析。
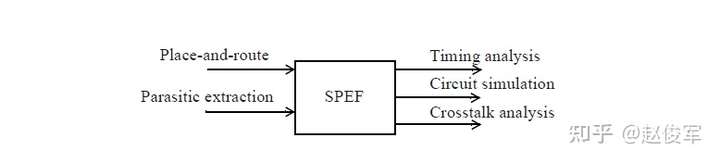
寄生参数可以在许多不同的层次上表示。SPEF支持分布式(distributed)网络模型、(reduced)简化网络模型和(lumped)集总电容模型。在分布式网络模型(D_NET)中,网络走线的每段都有其自己的R和C。在简化网络模型(R_NET)中,在网络的负载引脚上考虑一个简化的R和C,而在网络的驱动引脚上考虑一个π模型(C-R-C)。在集总电容模型中,仅为整个网络指定一个电容。图C-2显示了物理网络走线的一个示例,图C-3显示了分布式网络模型,图C-4显示了简化的网络模型,图C-5显示了集总电容模型。
互连寄生效应取决于工艺,SPEF支持最佳(best-case)、典型(typical)和最差(worst-case)三种情况。允许R、L和C值、端口压摆和负载使用此三种不同情况下的值。
通过提供一个包含网络名称和实例名称映射到索引的一个名称映射(name map),可以有效地减小SPEF文件的大小,更重要的是,所有较长名称仅出现在一个位置。
设计的SPEF文件可以拆分为多个文件,也可以分层。
C.2 格式
SPEF文件的格式如下:

header_definition包含了基本信息,例如SPEF版本号、设计名称以及R,L和C的单位。name_map指定了网络名称和实例名称到索引的映射。power_definition声明了电源网络和地网络。external_definition定义了设计的端口。define_definition中指出了SPEF还在其它文件中进行了描述的那些实例。internal_definition包含的是文件的核心——设计的寄生参数。
图C-6显示了header_definition的示例:

SPEF name 指定了SPEF的版本号;
DESIGN name 指定了设计的名称;
DATE string 指定了创建文件时的时间戳;
VENDOR string 指定了用于创建SPEF的供应商工具;
PROGRAM string 指定了用于生成SPEF的程序;
VERSION string 指定了用于创建SPEF的程序的版本号;
DESIGN_FLOW string string string . . . 指定了在什么阶段创建SPEF文件。它描述了有关SPEF文件的信息,这些信息无法通过读取文件来获得。
预定义的字符串值为:
● EXTERNAL_LOADS:外部载荷在SPEF文件中完全指定。
● EXTERNAL_SLEWS:外部压摆在SPEF文件中完全指定。
● FULL_CONNECTIVITY:SPEF中存在逻辑网表连接。
● MISSING_NETS:SPEF文件中可能缺少某些逻辑网络。
● NETLIST_TYPE_VERILOG:使用Verilog HDL类型命名约定。
● NETLIST_TYPE_VHDL87:使用VHDL87命名约定。
● NETLIST_TYPE_VHDL93:使用VHDL93网表命名约定。
● NETLIST_TYPE_EDIF:使用EDIF类型命名约定。
● ROUTING_CONFIDENCE:(正整数)所有网络的默认走线置信度,基本上是寄生精度的水平。
● ROUTING_CONFIDENCE_ENTRY:补充走线置信度值。
● NAME_SCOPE_LOCAL | FLAT:指定了SPEF文件中的路径是相对于文件还是相对于设计顶层。
● SLEW_THRESHOLDS:(low_input_threshold_percent,high_input_threshold_percent)指定了设计的默认输入转换阈值。
● PIN_CAP NONE | INPUT_OUTPUT | INPUT_ONLY:指定了作为总电容一部分的引脚电容类型,默认值为INPUT_OUTPUT。
DIVIDER / 指定了层次结构分隔符。可以使用的其它字符是" . " , " : "和" / "。
DELIMITER :指定了实例与其引脚之间的分隔符。可以使用的其它可能字符是" . " , " / " , " : " 或者 "|"。
BUS_DELIMITER [ ] 指定了用于标识总线位的前缀和后缀。可以用于前缀和后缀的其他可能字符是" { " , " ( " , " < " , " : "," ."和" } " , " ) ", " > "。
T_UNIT 正整数 NS | PS 指定了时间单位。
C_UNIT 正整数 PF | FF 指定了电容单位。
R_UNIT 正整数 OHM| KOHM 指定了电阻单位。
L_UNIT 正整数 HENRY | MH | UH 指定了电感单位。
SPEF文件中的注释可以两种形式出现:

图C-7显示了一个名称映射的示例。 它的形式为:


名称映射将指定名称到唯一整数值(它们的索引)的映射。名称映射有助于通过索引来对名称进行引用从而减小文件的大小,名称可以是网络名称或实例名称。考虑图C-7中的名称映射,以后可以使用它们的索引在SPEF文件中引用这些名称,例如:


因此,名称映射会通过使用其唯一的整数表示来避免重复长名称及其路径。
power definition部分定义了电源和接地网络:

以下是一些例子:

external_definition包含了设计的逻辑和物理端口的定义。图C-8显示了逻辑端口的示例,逻辑端口可以以下形式描述:


其中port_name可以是形式为*正整数的端口索引。方向为I表示输入,O表示输出,B表示双向。连接属性(conn_attribute)是可选的,可以是以下属性:
● *C number number:端口的坐标。
● *L par_value:端口的电容负载。
● *S par_value par_value:定义端口上的波形。
● *D cell_type:定义端口的驱动单元。
可以使用以下命令定义SPEF文件中的物理端口:

define definition部分定义了当前SPEF文件中引用的实例,但其寄生参数在其它SPEF文件中进行了描述:

当实例是物理分区(而不是逻辑层次结构)时,将使用*PDEFINE。以下有些例子:

这意味着将存在另一个带有*DESIGN值ddrphy的SPEF文件,该文件将包含设计ddrphy的寄生参数,其可能具有物理和逻辑层次结构。跨越层次边界的任何网络都必须描述为分布式网络(D_NET)。
internal definition部分包含了SPEF文件的核心,即设计中网络的寄生参数。基本上有两种形式:分布式网络D_NET和简化网络R_NET。图C-9中为一个分布式网络定义的示例:

第一行中的*5426是网络的索引号(网络名称请参见名称映射),0.899466是网络上的总电容值。电容值是网络上所有电容的总和,其中包括假定为接地的交叉耦合电容,还包括负载电容。它可能包含也可能不包含引脚电容,具体取决于DESIGN_FLOW定义中的PIN_CAP设置。
connectivity section描述了网络的驱动和负载引脚:

I表示内部引脚( P表示端口),14212:D表示实例14212的D引脚,14212是一个索引号(有关实际名称需参见名称映射)。“ I”表示网络上的负载(输入引脚),“ O”表示网络上的驱动(输出引脚)。C和 D如先前在connection attributes中所定义的那样,C定义了引脚的坐标,D定义了引脚的驱动单元。
capacitance section描述了分布式网络的电容,电容单位在之前已用* C_UNIT指定。

第一个数字是电容标识符。电容规范有两种形式: 第一种到第四种一种形式,第五种是另一种形式。第一种形式(第一至第四种)指定两个网络之间的交叉耦合电容,而第二种形式(id为5)指定接地电容。因此,在电容id1中,网络5426和5290之间的交叉耦合电容为0.217446;在电容id5中,接地电容为0.529736。请注意,第一个节点名称必须是所描述的D_NET的网络名称。网络索引后面的正整数(5426:10278中的10278)指定内部节点或连接点。因此,电容id4表示在内部节点10278的网络5426和内部节点9922的网络*5116之间存在耦合电容,该耦合电容的值为0.113918。
resistance section描述了分布式网络的电阻,电阻单位在之前已用* R_UNIT指定。

第一个字段是电阻标识符。因此,该网络具有三个电阻部分。第一个在内部节点5426:10278与14212上的D引脚之间,电阻值为0.34。使用图C-10中所示的RC网络可以更好地理解电容和电阻部分。
图C-11显示了分布式网络的另一个示例。该网络具有一个驱动和两个负载,网络上的总电容为2.69358。图C-12显示了与分布式网络相对应的RC网络。

通常,内部定义(internal definition)可以包含以下规范:
● D_NET:逻辑网络的分布式RC网络形式。
● R_NET:逻辑网络的简化RC网络形式。
● D_PNET:物理网络的分布式形式。
● R_PNET:物理网络的简化形式。
语法如下:


inductance section用于指定电感,其格式类似于电阻部分。 * V用于指定网络寄生参数的准确性。这些可以单独使用网络指定,也可以使用带有ROUTING_CONFIDENCE值的*** DESIGN_FLOW**语句进行全局指定,例如:

它指定了寄生参数是在最终单元布局和最终布线之后提取得到的,并且使用了3d提取。走线置信度的其它可能值为:
● 10:统计线负载模型
● 20:物理线负载模型
● 30:具有位置但没有单元布局的物理分区
● 40:使用基于斯坦纳树(steiner tree)的走线估计的单元位置
● 50:使用全局走线估计的单元位置
● 60:使用斯坦纳走线进行的最终单元布局
● 70:使用全局走线进行的最终单元布局
● 80:最终单元布局,最终走线,2d提取
● 90:最终单元布局,最终走线,2.5d提取
● 100:最终单元布局,最终走线,3d提取
reduced net是从分布式网络形式简化而来的网络。网络上每个驱动都有一个驱动精简部分(driver reduction section)。驱动精简部分的形式为:

C2_R1_C1表示在网络的驱动引脚上使用π模型的寄生参数。 RC结构中的rc_value是指Elmore延迟(R * C)。 图C-13显示了简化后的网络的SPEF示例,图C-14以图形方式显示了RC网络。

可使用D_NET或R_NET结构描述集总电容模型(lumped capacitance model),该结构仅具有总电容而没有其它信息。以下是集总电容声明的示例:

SPEF文件中的值可以采用三元数组的形式来表示工艺变化,例如:
● 0.243 : 0.269 : 0.300
最佳情况下值为0.243,典型情况下值为0.269,最差情况下值为0.300。
C.3 完整语法
本节描述了SPEF文件的完整语法。
可以在字符前面加上反斜杠()来对其进行转义。注释有两种形式://开始注释直到行尾,而/ * . . . * /是多行注释。
在以下语法中,粗体字符如(,[是语法的一部分。所有结构均按字母顺序排列,起始符号为SPEF_file:











